本文主要是介绍Linuk(包含信创Tongweb东方通,AAS金蝶)部署solr,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Linuk部署solr
统一安装目录都在 /data/application中application为自己创建的目录
文章目录
- Linuk部署solr
- 安装JDk
- 查看JDK版本:
- JDK下载地址:
- 指定solr启动用的jdk
- 安装sorl 服务
- 1、下载solr
- 2、安装solr
- 3、运行/关闭和重启solr-Jetty容器
- 4、修改默认端口
- 5、查看日志
- 6、安装常见失败错误
- **root启动失败**(force)
- Xss768k错误
- 创建solr核心(数据源)
- 一、只检索文档meta_db
- 1、创建meta_db
- 2、导入jar包
- 3、中文分词器安装配置
- 4、链接oracle数据表
- 4.1新建数据配置文件
- 4.2导入新建的数据库配置文件
- 4.3配置字段映射
- 4.4Solr建立索引时,过滤HTML标签
- 4.5全量导入数据
- 4.6全量删除数据
- 4.7查看导入的数据
- 5、定时自动同步数据
- 方法一(官方不更新了)
- 方法二
- 6、API
- 二、检索文档和附件[多层嵌套格式数据]file_db
- 1、创建file_db
- 2、导入jar包
- 3、中文分词器安装配置
- 4、链接oracle数据表
- 4.1新建数据配置文件
- 4.2导入新建的数据库配置文件
- 4.3配置字段映射
- 4.4全量导入数据
- 4.5全量删除数据
- 4.6查看导入的数据
- 5、定时自动同步数据
- 6、API
- 配置中间件启动solr
- 1、配置tomcat 启动 solr
- 找不到默认index页面
- 2、配置TongWeb(东方通)启动solr
- 3、配置AAS(金蝶)启动solr
- solr安全策略
- 一、solr基于jetty容器配置后台登陆角色用户名密码
- 1.新建用户密码文件
- 2.添加jetty 用户加载这个文件
- 3.配置web.xml,用密码登录
- 4.重启solr服务器
- 二、solr基于Tongweb(东方通)容器配置后台登陆角色用户名密码
- 1.创建tongweb-web.xml
- 2.配置web.xml,用密码登录
- 3.重启solr服务器
- 三、solr基于AAS(金蝶)容器配置后台登陆角色用户名密码
- 1.创建apusic-application.xml
- 2.配置web.xml,用密码登录
- 3.重启solr服务器
- Springboot用户密码方式连接solr
- 配置文件application.yml
安装JDk
查看JDK版本:
java -version
JDK下载地址:
https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html 中选择相应jdk版本
cd /data/application
tar -zxvf 这个jdk
指定solr启动用的jdk
cd /data/application/solr-8.9.0/bin
vim solr.in.sh
SOLR_JAVA_HOME="" jdk路径不要带bin
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PHBUWpHB-1688616477906)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110100701.jpg)]
安装sorl 服务
1、下载solr
官网默认下载地址:https://solr.apache.org/downloads.html
官网其它版本下载地址:http://archive.apache.org/dist/lucene/solr/
官网文档地址:http://archive.apache.org/dist/lucene/solr/
本次下载的为Solr 8.9.0 版本,最新版本9.0.0用的JDK 11 不能进行升级了
2、安装solr
cd /data/application
将solr-9.0.0.tgz 上传到application 目录中
解压solr-9.0.0.tgz 文件 到当前目录:
tar zxvf solr-8.9.0.tgz
3、运行/关闭和重启solr-Jetty容器
解压后进行solr-8.9.0\bin目录,访问http://localhost:8983/出现solr管理界面即安装成功。
./solr start -p 8983 启动
./solr stop -p 8983 关闭
./solr restart -p 8983 重启
查看是否运行成功ps -f |grep solr
4、修改默认端口
cd /data/application/solr-8.9.0/bin
vim solr.in.sh SOLR_PORT="8983"
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-HKLsrc8C-1688616477907)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110100826.jpg)]
5、查看日志
cd /data/application/solr-8.9.0/server/logs
6、安装常见失败错误
root启动失败(force)
*** [WARN] *** Your Max Processes Limit is currently 14690. It should be set to 65000 to avoid operational disruption. If you no longer wish to see this warning, set SOLR_ULIMIT_CHECKS to false in your profile or solr.in.sh
WARNING: Starting Solr as the root user is a security risk and not considered best practice. Exiting.Please consult the Reference Guide. To override this check, start with argument '-force'
解决方式
./solr start -force
Xss768k错误
cd /data/application/solr-8.9.0/bin
vim solr.in.sh #添加或修改
SOLR_JAVA_STACK_SIZE="-Xss768k"
创建solr核心(数据源)
一、只检索文档meta_db
1、创建meta_db
cd /data/application/solr-8.9.0/bin./solr create -c meta_db -force
然后在/data/application/solr-8.9.0/server/solr目录下会建立meta_db目录,目录下自动生成以下文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-2T98NMTU-1688616477908)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110153828.jpg)]
2、导入jar包
将solr-8.9.0\dist下2个jar包
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-mCp6EEzR-1688616477912)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\F2A70A45-691E-4327-9E4F-A2904073CA28.png)]
和JDBC驱动包拷贝到solr-8.9.0\server\solr-webapp\webapp\WEB-INF\lib目录下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-DEOkuWDk-1688616477913)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110153447.jpg)]
3、中文分词器安装配置
下载地址:https://github.com/magese/ik-analyzer-solr
下载的jar : ik-analyzer-8.5.0.jar
拷贝到solr-8.9.0\server\solr-webapp\webapp\WEB-INF\lib目录下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sCUVwuvq-1688616477914)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110154403.jpg)]
将resources目录下的5个配置文件放入solr服务的solr-8.9.0\server\solr-webapp\webapp\WEB-INF\classes目录下
如果没有classes 就自己新建文件夹
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-JBuXJPt8-1688616477915)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110154605.jpg)]
将下面代码加到\solr-8.9.0\server\solr\meat_db\conf\managed-schema里
<!-- ik分词器 --><fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>
说明:当 useSmart=”false”,分词粒度较小,分词后个数多;当 useSmart=”true”,分词粒度大,分词后个数据少。
选择Analysis 输入要搜索的中文 选择FieldType为text_ik 可以发现分词成功
ps:如果没有text_ik 就重启一下solr
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cuvqHCNf-1688616477915)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110155900.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-OlRy4Gwl-1688616477916)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110155954.jpg)]
4、链接oracle数据表
4.1新建数据配置文件
在/data/application/solr-8.9.0/server/solr/meta_db/conf文件夹中,新建db-data-config.xml
cd /data/application/solr-8.9.0/server/solr/meta_db/confvim db-data-config.xml
将下边内容粘贴到db-data-config.xml
<dataConfig><dataSource name="source1" type="JdbcDataSource" driver="oracle.jdbc.driver.OracleDriver" url="jdbc:oracle:thin:@:1521:orcl" user="" password=""/> <!-- sql 编写 --><!-- entity属性:name:实体名称dataSource:数据源名称pk:实体主键,增量导入时使用query:全量同步SQLdeltaQuery:增量导入时查询需要导入的数据的主键deltaImportQuery:增量导入查询SQL,根据deltaQuery查询出的id查询数据deletedPkQuery:增量导入时会删除solr中根据该SQL查询出来的id对应的数据增量同步原理:首先保障数据库表里面有个记录时间的字段,每次添加或者修改后记录时间;solr每次同步数后会记录同步时间:last_index_time,然后SQL语句里面就可以添加查询条件 :last_modify_date >= '${dih.last_index_time}',表里面更新时间大于solr的更新时间,说明数据被更新了或者是新增的数据;last_modify_date:这个是表里面记录更新、插入时间的字段;--><!-- 以下为自定义配置 liuyu--><!--deltaQuery用于查询比上一次数据更新操作的时间更晚的数据的id,deltaImportQuery则根据deltaQuery取到的id去MySql数据库查询数据用以更新solr中的数据--><document><entity name="share" transformer="ClobTransformer,HTMLStripTransformer" dataSource="source1" pk="RECID"query="select cnd.recid as id,cnd.recid, cnd.chnlid, cnd.docid, cnd.modal, cnd.docstatus, cnd.docpuburl, cnd.docpubtime,cnd.docreltime,cnd.siteid, cnd.docchannel, doc.doctitle,doc.doccontent,doc.opertime from cms_chnldocinfo cnd left outer join cms_documentinfo doc on cnd.docid=doc.docid where cnd.docstatus=10" deltaImportQuery="select cnd.recid as id,cnd.recid, cnd.chnlid, cnd.docid, cnd.modal, cnd.docstatus, cnd.docpuburl, cnd.docpubtime,cnd.docreltime, cnd.siteid, cnd.docchannel, doc.doctitle,doc.doccontent,doc.opertime from CMS_chnldocinfo cnd left outer join CMS_documentinfo doc on cnd.docid=doc.docid where cnd.DOCSTATUS=10 and cnd.recid = '${dih.delta.RECID}'"deltaQuery="select cnd.recid as id,recid from cms_chnldocinfo cnd left outer join CMS_documentinfo doc on cnd.docid=doc.docid where cnd.docstatus=10 and cnd.UPDATEINGTIME > to_date('${dih.last_index_time}','yyyy-mm-dd hh24:mi:ss')" deletedPkQuery="select recid from cms_chnldocinfo where docstatus!=10"><field column="ID" name="id" /><field column="RECID" name="recid" /><field column="CHNLID" name="chnlid" /><field column="DOCID" name="docid" /><field column="MODAL" name="modal" /><field column="DOCSTATUS" name="docstatus" /><field column="DOCPUBURL" name="docpuburl" /><field column="DOCPUBTIME" name="docpubtime" /><field column="DOCRELTIME" name="docreltime" /><field column="SITEID" name="siteid" /><field column="DOCCHANNEL" name="docchannel" /><field column="DOCTITLE" name="doctitle" /><field column="DOCCONTENT" name="doccontent" clob="true"/><field column="OPERTIME" name="opertime" /></entity></document>
</dataConfig>
注意大写字段的地方,测试了好久才发现大小写对增量发布有影响
4.2导入新建的数据库配置文件
配置solrconfig.xml导入的db-data-config.xml
cd /data/application/solr-8.9.0/server/solr/meta_db/confvim solrconfig.xml
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">db-data-config.xml</str> </lst>
</requestHandler>
4.3配置字段映射
将下面代码加到F:\solr-8.9.0\server\solr\meat_db\conf\managed-schema里
cd /data/application/solr-8.9.0/server/solr/meta_db/conf
<!-- 定义文档字段name:字段名称;type:分词类型;indexed:是否进行索引;stored:是否进行储存,需要进行显示一般需要储存;required:字段是否可为空;multiValued:是否有多个值--><field name="recid" type="string" uninvertible="false" indexed="true" required="true" stored="true"/><field name="chnlid" type="strings" stored="false" required="false" multiValued="false"/><field name="docid" type="strings" stored="false" required="false" multiValued="false"/><field name="modal" type="strings" stored="false" required="false" multiValued="false"/><field name="docstatus" type="strings" stored="true" required="false" multiValued="false"/><field name="docpuburl" type="strings" stored="true" required="false" multiValued="false"/><field name="docpubtime" type="strings" stored="true" required="false" multiValued="false"/><field name="docreltime" type="strings" stored="true" required="false" multiValued="false"/><field name="siteid" type="strings" stored="false" required="false" multiValued="false"/><field name="docchannel" type="strings" stored="true" required="false" multiValued="false"/><field name="doctitle" type="text_ik" stored="true" required="false" multiValued="false"/><field name="doccontent" type="text_ik" stored="true" required="false" multiValued="false"/><field name="opertime" type="strings" stored="true" required="false" multiValued="false"/><!-- 索引复制,联合索引 --><field name="keyword" type="text_ik" indexed="true" stored="true" omitNorms="true" multiValued="true"/><copyField source="doctitle" dest="keyword" maxChars="30000"/><copyField source="doccontent" dest="keyword" maxChars="30000"/>
4.4Solr建立索引时,过滤HTML标签
下边这种方式不管用,再项目中二次处理结果集
1、在数据库的读取文件data-config.xml 中的entity 标记里边添加 transformer=”HTMLStripTransformer” 代码。
<entity name="edusystem" pk="url" transformer="HTMLStripTransformer" query="SELECT description from table"><field column="description" name="description" stripHTML="true"/>
</entity>
2、在field 字段需要过滤html代码的字段添加 stripHTML=”true”
<entity name="edusystem" pk="url" transformer="HTMLStripTransformer" query="SELECT description from table"><field column="description" name="description" stripHTML="true"/>
</entity>
3、修改schema.xml文件中的fieldType标记中的内容,添加如下代码
<charFilter class="solr.HTMLStripCharFilterFactory" /><analyzer type="query"><tokenizer class="com.chenlb.mmseg4j.solr.MMSegTokenizerFactory" mode="simple" reload="true" /><filter class="solr.LowerCaseFilterFactory" /><charFilter class="solr.HTMLStripCharFilterFactory" />
</analyzer>
4.5全量导入数据
配置完成(重启solr),进入solr管理界面查看:
选择要配置的核心,点击dataimport,选择entity,execute,刷新,导入完成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-KZ2Ch4FR-1688616477918)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110162406.jpg)]
4.6全量删除数据
Documents
Document Type中点选XML
Document(s)中输入:
<delete><query>*:*</query></delete>
<commit/>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-T5sJaGWx-1688616477919)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110162807.jpg)]
4.7查看导入的数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-aHvtRq6Y-1688616477920)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110162507.jpg)]
5、定时自动同步数据
方法一(官方不更新了)
参考地址:https://blog.csdn.net/dqb4531/article/details/103183690
1、下载jar包:solr定时任务需要的包
下载地址: https://pan.baidu.com/s/1cgCVzT5IlSg1TabHCtfnPA 提取码: cncs
如果在solr的页面中选择增量导入没有问题时,但是定时导入一直没有执行的话,按以下步骤进行:
2、在solr-8.2.0\server\solr-webapp\webapp\WEB-INF\lib下导入需要的包(log4j-1.2.16.jar,slf4j-api-1.7.25.jar,slf4j-log4j12-1.7.25.jar)
经过测试:metrics-core-3.0.2.jar不能放在lib下,有冲突
3、找到目录solr-8.9.0/server/solr-webapp/webapp/WEB-INF 的web.xml ,在里面配置监听器,添加如下代码:
<!-- 定时更新数据 --><listener> <listener-class>org.apache.solr.handler.dataimport.scheduler.ApplicationListener</listener-class></listener>
4、确定dataimport.proterties的位置没有放错
这个经过测试是放在solr-8.2.0\server\solr下新建一个conf文件夹,然后放入dataimport.properties
#Thu Nov 10 08:26:15 UTC 2022
share.last_index_time=2022-11-10 08\:26\:14
last_index_time=2022-11-10 08\:26\:14
#################################################
# #
# 定时任务执行增量更新 #
# #
################################################## server BASIC authorization by userName and password
# format:userName:password
# if no server BASIC authorization,please set:
# authorizationMsg=
#authorizationMsg=userName:password# to sync or not to sync
# 同步执行更新
syncEnabled=1#
# solr中对应得core名,可写多个,多个时用逗号“,”分隔
#
syncCores=meta_db# 没有密码验证就不用配置
# solr服务添加了登录验证,所以这里也要配置用户名和密码
# 用户名:密码
user_pwd=solr:SolrRocks# solr server name or IP address
# [defaults to localhost if empty]
# solr服务的id,定时任务服务是集成在solr服务里面的,所以都在同一台机器,所以localhost即可
# server=localhostserver=localhost# solr服务的端口号
# [defaults to 80 if empty]
port=8984# application name/context
# [defaults to current ServletContextListener's context (app) name]
webapp=solr# URL params [mandatory]
# remainder of URL
#增量更新对应的访问参数,注意/dataimport?地址不同版本sorl了能地址名不同,具体可登录solr管理后台##查看dataimport的具体访问ULR
# clean=false 表示不清空以前的数据,只有全量更新才为true
params=/dataimport?command=delta-import&clean=false&commit=true&optimize=false&wt=json&indent=true&verbose=false&debug=false# schedule interval
# number of minutes between two runs
# 定时任务执行增量更新的间隔,不能为0.5这样的数,默认设置为1分钟
interval=1########################## 默认没有全量导入功能,可以自己写定时任务调用solr全量更新的地址,地址如下reBuildIndexParams ###################### 重做索引的时间间隔,单位分钟,默认7200,即5天;
# 为空,为0,或者注释掉:表示永不重做索引,即全量更新的时间间隔,1分钟一同步
#reBuildIndexInterval=7200# 重做索引的参数,即全量更新
reBuildIndexParams=/dataimport?command=full-import&clean=true&commit=true&optimize=true&wt=json&indent=true&verbose=false&debug=false# 重做索引时间间隔的计时开始时间,第一次真正执行的时间=reBuildIndexBeginTime+reBuildIndexInterval*60*1000;
# 两种格式:2020-05-15 16:10:00 或者 16:10:00,后一种会自动补全日期部分为服务启动时的日期
reBuildIndexBeginTime=08:30:00
重启solr 服务即可,可以通过日志查看执行情况,solr日志路径:/solr/solr-8.9.0/server/logs/solr.log
方法二
自己写一个定时任务调用
http://124.221.212.171:8984/solr/meta_db/dataimport?command=delta-import&clean=false&commit=true
接口定时同步即可
6、API
SOLR在浏览器中输入命令:
1、全导入:
http://124.221.212.171:8984/solr/meta_db/dataimport?command=full-import&commit=true
2、增量导入:
http://124.221.212.171:8984/solr/meta_db/dataimport?command=delta-import&clean=false&commit=true
3、查看导入状态
http://124.221.212.171:8984/solr/meta_db/dataimport?command=status
浏览器地址可用做定时任务执行调用的地址
二、检索文档和附件[多层嵌套格式数据]file_db
1、创建file_db
cd /data/application/solr-8.9.0/bin./solr create -c file_db -force
然后在/data/application/solr-8.9.0/server/solr目录下会建立file_db目录,目录下自动生成以下文件
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8isFRpk4-1688616477920)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\8750CC32-45B6-46c8-A163-A9557F49DEA0.png)]
2、导入jar包
将solr-8.9.0\dist下2个jar包
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-cOYUn2Iu-1688616477921)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\F2A70A45-691E-4327-9E4F-A2904073CA28.png)]
和JDBC驱动包拷贝到solr-8.9.0\server\solr-webapp\webapp\WEB-INF\lib目录下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-dwEk41J7-1688616477921)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110153447.jpg)]
3、中文分词器安装配置
下载地址:https://github.com/magese/ik-analyzer-solr
下载的jar : ik-analyzer-8.5.0.jar
拷贝到solr-8.9.0\server\solr-webapp\webapp\WEB-INF\lib目录下
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-qSoSNO6N-1688616477922)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110154403.jpg)]
将resources目录下的5个配置文件放入solr服务的solr-8.9.0\server\solr-webapp\webapp\WEB-INF\classes目录下
如果没有classes 就自己新建文件夹
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o2CVc75g-1688616477923)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110154605.jpg)]
将下面代码加到\solr-8.9.0\server\solr\file_db\conf\managed-schema里
<!-- ik分词器 --><fieldType name="text_ik" class="solr.TextField"><analyzer type="index"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="false" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer><analyzer type="query"><tokenizer class="org.wltea.analyzer.lucene.IKTokenizerFactory" useSmart="true" conf="ik.conf"/><filter class="solr.LowerCaseFilterFactory"/></analyzer></fieldType>
说明:当 useSmart=”false”,分词粒度较小,分词后个数多;当 useSmart=”true”,分词粒度大,分词后个数据少。
选择Analysis 输入要搜索的中文 选择FieldType为text_ik 可以发现分词成功
ps:如果没有text_ik 就重启一下solr
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-rMwPwjPJ-1688616477924)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110155900.jpg)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-YrJYn7l7-1688616477924)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110155954.jpg)]
4、链接oracle数据表
4.1新建数据配置文件
在/data/application/solr-8.9.0/server/solr/file_db/conf文件夹中,新建tika-data-config.xml
cd /data/application/solr-8.9.0/server/solr/file_db/confvim tika-data-config.xml
将下边内容粘贴到tika-data-config.xml
<dataConfig><dataSource name="source" type="JdbcDataSource" driver="dm.jdbc.driver.DmDriver" url="jdbc:dm://127.0.0.1:5236" user="" password=""/> <dataSource name="tk_ds" type="BinURLDataSource" /><script> <![CDATA[ //转换带有中文的文件名function GenerateId(row) {var url = row.get('LINK');if (url === null || true === url.isEmpty() || url === '') {row.remove('LINK');} else {url=encodeURI(url);}row.put('LINK', url);return row;} ]]> </script> <document><entity name="docment" transformer="ClobTransformer,HTMLStripTransformer,DateFormatTransformer" rootEntity="true" dataSource="source" pk="RECID" query="select cnd.recid as id,cnd.recid, cnd.chnlid, cnd.docid, cnd.modal, cnd.docstatus, cnd.docpuburl, cnd.docpubtime,cnd.docreltime,cnd.siteid, cnd.docchannel, doc.doctitle,doc.doccontent,doc.opertime,(select chnlname from cms_channelinfo chnl where chnl.channelid=cnd.chnlid ) as chnlnamefrom cms_chnldocinfo cnd left outer join cms_documentinfo doc on cnd.docid=doc.docid where cnd.docstatus=10 and cnd.chnlid>0" deltaImportQuery="select cnd.recid as id,cnd.recid, cnd.chnlid, cnd.docid, cnd.modal, cnd.docstatus, cnd.docpuburl, cnd.docpubtime,cnd.docreltime, cnd.siteid, cnd.docchannel, doc.doctitle,doc.doccontent,doc.opertime,(select chnlname from cms_channelinfo chnl where chnl.channelid=cnd.chnlid ) as chnlnamefrom CMS_chnldocinfo cnd left outer join CMS_documentinfo doc on cnd.docid=doc.docid where cnd.DOCSTATUS=10 and chnlid>0 and cnd.recid = '${dih.delta.RECID}' " deltaQuery="select cnd.recid as id,recid from cms_chnldocinfo cnd left outer join CMS_documentinfo doc on cnd.docid=doc.docid where cnd.docstatus=10 and cnd.UPDATEINGTIME > to_date('${dih.last_index_time}','yyyy-mm-dd hh24:mi:ss')" deletedPkQuery="select recid from cms_chnldocinfo where docstatus!=10 and chnlid>0 and UPDATEINGTIME > to_date('${dih.last_index_time}','yyyy-mm-dd hh24:mi:ss') "><field column="ID" name="id" /><field column="RECID" name="recid" /><field column="CHNLID" name="chnlid" /><field column="CHNLNAME" name="chnlname" /><field column="DOCID" name="docid" /><field column="MODAL" name="modal" /><field column="DOCSTATUS" name="docstatus" /><field column="DOCPUBURL" name="docpuburl" /><field column="DOCPUBTIME" name="docpubtime" /><field column="DOCRELTIME" name="docreltime" /><field column="SITEID" name="siteid" /><field column="DOCCHANNEL" name="docchannel" /><field column="DOCTITLE" name="doctitle" stripHTML="true" /><field column="DOCCONTENT" name="doccontent" clob="true"/><field column="OPERTIME" name="opertime" /><!-- 附件数据 --><entity name="appendixnifo" dataSource="source" transformer="script:GenerateId"query="select appendixid as id, appendixid,appdocid,showname,REPLACE(REPLACE(filepath, 'C:\CMSData\', 'http://127.0.0.1:8081/'),'\','/') as LINK from CMS_APPENDIXINFO where appdocid ='${docment.DOCID}' "><field column="LINK" name="link" /><field column="APPENDIXID" name="appendixid" /><field column="SHOWNAME" name="showname" /><!-- 导入数据 --><entity name="appendixnifoImport" processor="TikaEntityProcessor" url="${appendixnifo.LINK}" format="text" onError="skip" dataSource="tk_ds"><field column="title" name="title" meta="true" /><field column="text" name="text" /></entity></entity></entity></document>
</dataConfig>
注意大写字段的地方,测试了好久才发现大小写对增量发布有影响
4.2导入新建的数据库配置文件
配置solrconfig.xml导入的tika-data-config.xml
cd /data/application/solr-8.9.0/server/solr/file_db/confvim solrconfig.xml
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">tika-data-config.xml</str> </lst>
</requestHandler>
4.3配置字段映射
将下面代码加到F:\solr-8.9.0\server\solr\file_db\conf\managed-schema里
cd /data/application/solr-8.9.0/server/solr/file_db/conf
<!-- 定义文档字段name:字段名称;type:分词类型;indexed:是否进行索引;stored:是否进行储存,需要进行显示一般需要储存;required:字段是否可为空;multiValued:是否有多个值--><field name="appendixid" type="strings" stored="true" required="true" multiValued="true"/><field name="showname" type="text_ik" stored="true" required="true" multiValued="true"/><field name="link" type="strings" stored="true" required="true" multiValued="true"/> <field name="title" type="text_ik" indexed="true" stored="true" multiValued="true"/><field name="text" type="text_ik" indexed="true" stored="true" multiValued="true"/><field name="recid" type="string" uninvertible="false" indexed="false" required="false" stored="true"/><field name="chnlid" type="strings" stored="false" required="false" multiValued="false"/><field name="chnlname" type="strings" stored="false" required="false" multiValued="false"/> <field name="docid" type="strings" stored="false" required="false" multiValued="false"/><field name="modal" type="strings" stored="false" required="false" multiValued="false"/><field name="docstatus" type="strings" stored="true" required="false" multiValued="false"/><field name="docpuburl" type="strings" stored="true" required="false" multiValued="false"/><field name="docpubtime" type="strings" stored="true" required="false" multiValued="false"/><field name="docreltime" type="strings" stored="true" required="false" multiValued="false"/><field name="siteid" type="strings" stored="false" required="false" multiValued="false"/><field name="docchannel" type="strings" stored="true" required="false" multiValued="false"/><field name="doctitle" type="text_ik" stored="true" required="false" multiValued="false"/><field name="doccontent" type="text_ik" stored="true" required="false" multiValued="false"/><field name="opertime" type="strings" stored="true" required="false" multiValued="false"/><!-- 主键 --><field name="id" type="string" indexed="true" stored="true"/> <!-- 索引复制,联合索引 <field name="keyword" type="text_ik" indexed="true" stored="true" omitNorms="true" multiValued="true"/> --><field name="keyword" type="text_ik" indexed="true" stored="false" required="true" multiValued="true" /><copyField source="title" dest="keyword" maxChars="30000"/><copyField source="text" dest="keyword" maxChars="30000"/> <copyField source="showname" dest="keyword" maxChars="30000"/> <copyField source="doctitle" dest="keyword" maxChars="30000"/><copyField source="doccontent" dest="keyword" maxChars="30000"/>
4.4全量导入数据
配置完成(重启solr),进入solr管理界面查看:
选择要配置的核心,点击dataimport,选择entity,execute,刷新,导入完成
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-NoR1sQ2D-1688616477925)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110162406.jpg)]
4.5全量删除数据
Documents
Document Type中点选XML
Document(s)中输入:
<delete><query>*:*</query></delete>
<commit/>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Ce9KQKQk-1688616477925)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110162807.jpg)]
4.6查看导入的数据
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Jx6zu1YO-1688616477926)(E:\ZGtdkxyjy\cms-search-rails\项目文档\文档原文件件\Dingtalk_20221110162507.jpg)]
5、定时自动同步数据
自己写一个定时任务调用
http://124.221.212.171:8984/solr/file_db/dataimport?command=delta-import&clean=false&commit=true
接口定时同步即可
6、API
SOLR在浏览器中输入命令:
1、全导入:
http://124.221.212.171:8984/solr/file_db/dataimport?command=full-import&commit=true
2、增量导入:
http://124.221.212.171:8984/solr/file_db/dataimport?command=delta-import&clean=false&commit=true
3、查看导入状态
http://124.221.212.171:8984/solr/file_db/dataimport?command=status
浏览器地址可用做定时任务执行调用的地址
配置中间件启动solr
1、配置tomcat 启动 solr
参考网址:https://www.cnblogs.com/smiles365/articles/15269607.html
配置和部署
1.准备一个解压后的tomcat,建议用tomcat8或tomcat9版本或以下,tomcat10会报各种错误。
2.打开solr,找到webapp,复制整个webapp到tomcat下的webapps下并修改名字为solr.
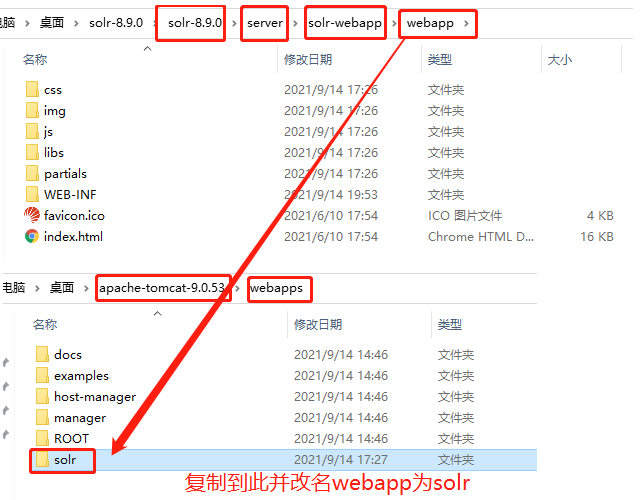
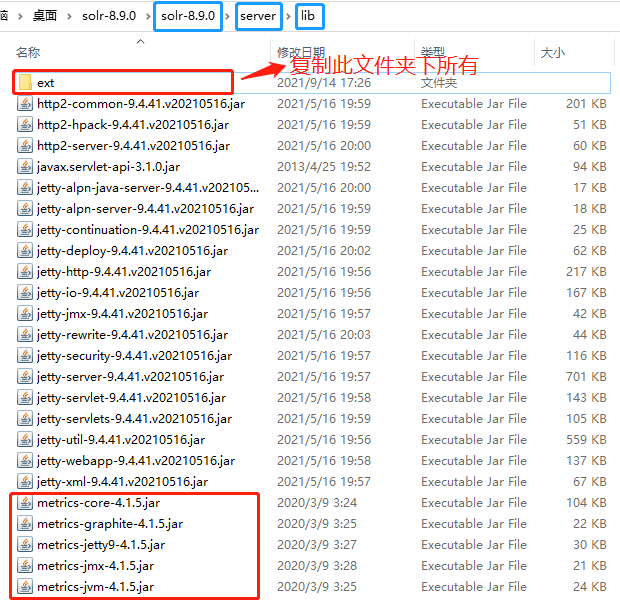
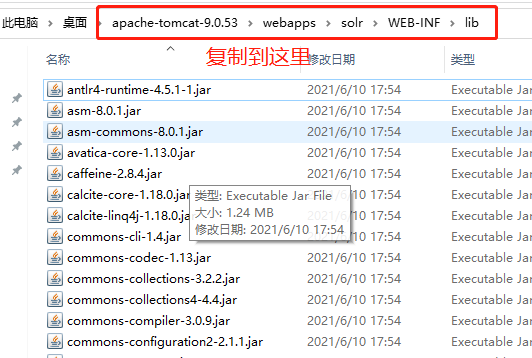
3.添加扩展:复制solr-8.9.0\server\lib\ext下所有jar包及solr-8.9.0\server\lib下带metrics的所有jar到tomcat的apache-tomcat-9.0.53\webapps\solr\WEB-INF\lib下
from:
to:
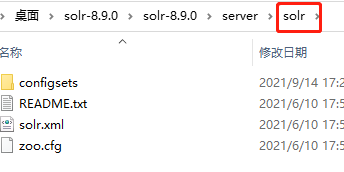
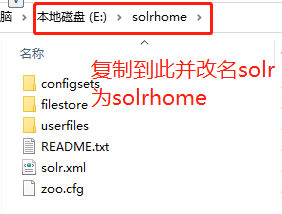
4.创建solrhome,solr-8.9.0\server下的solr其实就是solrhome,复制整个solr到本地盘符下并改名字为solrhome,我这里复制到E盘下。
from:
to:
\5. 在tomcat配置solrhome
位置:打开tomcat中webapps\solr\WEB-INF下web.xml进行编辑
配置1:
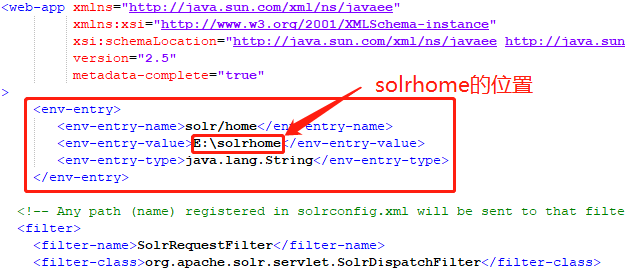
代码:
<env-entry><env-entry-name>solr/home</env-entry-name><env-entry-value>E:\solrhome</env-entry-value><env-entry-type>java.lang.String</env-entry-type></env-entry>
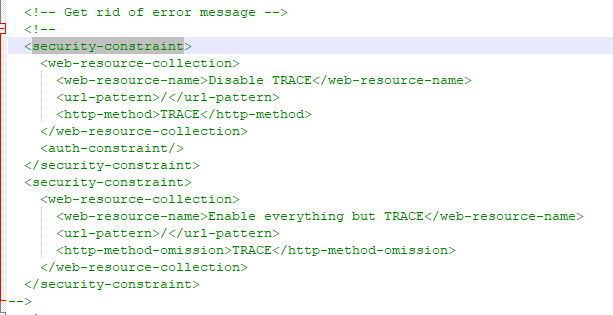
配置2:注释掉security-constraint不然会报403
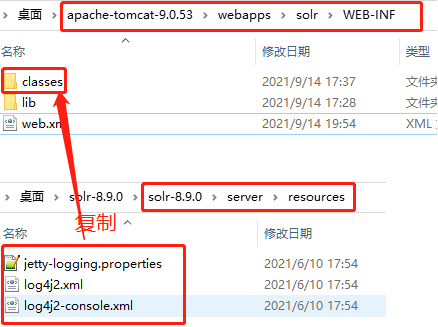
6.配置classes:在tomcat的webapps\solr\WEB-INF下创建classes,复制solr安装包下solr-8.9.0\server\resources下的所有文件到classes中(不做此步骤tomcat启动后浏览器404)。
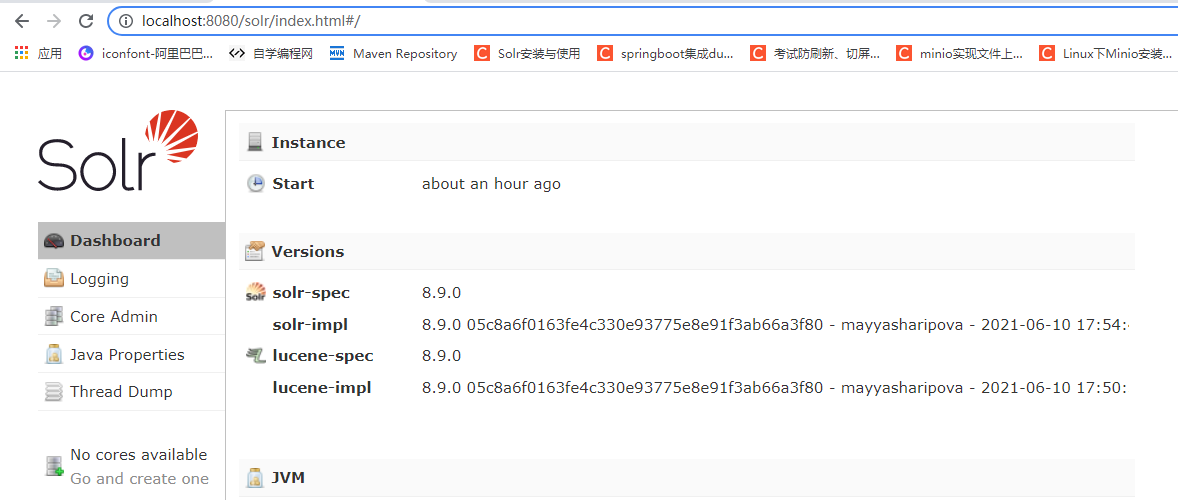
7.启动tomcat访问:http://localhost:8080/solr/index.html#/ 可以看到启动成功了,如果启动时报ClassNotFoundException异常说明少jar包了,我们可以查看它的异常信息然后知道具体少了那个包,你就去solr安装包下solr-8.9.0\server\lib下去找复制过来就好了。

找不到默认index页面
在 solr 跟目录下创建 index.jsp
<%@ page language="java" contentType="text/html; charset=utf-8" pageEncoding="utf-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">
<jsp:forward page="/index.html" />
2、配置TongWeb(东方通)启动solr
和配置tomcat的方式一样
3、配置AAS(金蝶)启动solr
和配置tomcat的方式一样
solr安全策略
一、solr基于jetty容器配置后台登陆角色用户名密码
1.新建用户密码文件
cd /data/application/solr-8.9.0/server/etcvim role.properties
内容如下
#userName: password,role
demo: 123,admin
2.添加jetty 用户加载这个文件
cd /data/application/solr-8.9.0/server/contextsvim solr-jetty-context.xml
添加内容如下:
<?xml version="1.0"?>
<Configure class="org.eclipse.jetty.webapp.WebAppContext"><Set name="contextPath"><Property name="hostContext" default="/solr"/></Set><Set name="war"><Property name="jetty.base"/>/solr-webapp/webapp</Set><Set name="defaultsDescriptor"><Property name="jetty.base"/>/etc/webdefault.xml</Set><Set name="extractWAR">false</Set>这个是添加的内容------------------------------------------------------<Get name="securityHandler"><Set name="loginService"><New class="org.eclipse.jetty.security.HashLoginService"><Set name="name">verify—name</Set><Set name="config"><SystemProperty name="jetty.home" default="."/>/etc/verify.properties</Set></New></Set></Get>
------------------------------------------------
</Configure>
3.配置web.xml,用密码登录
cd /data/application/solr-8.9.0/server/solr-webapp/webapp/WEB-INFvim web.xml
添加内容如下:放在底部就行了
--------------------------------这是添加的内容--------------------------------------
<security-constraint> <web-resource-collection> <web-resource-name>Solr</web-resource-name> <!--描述--> <url-pattern>/</url-pattern> <!-- 验证的网页的位置--> </web-resource-collection> <auth-constraint> <role-name>admin</role-name> <!-- 验证的角色,别写成用户名,如有多个角色可以写多个role-name 标签--> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <!-- 关键--> <realm-name>TestRealm</realm-name>
</login-config>
--------------------------------------------------------------------
</web-app>
4.重启solr服务器
配置完成后,重启solr服务器,重新访问solr就需要用户名和密码了
./solr restart -p 8983 重启,再bin目录下执行/data/application/solr-8.9.0/bin
二、solr基于Tongweb(东方通)容器配置后台登陆角色用户名密码
1.创建tongweb-web.xml
cd /data/application/solr-8.9.0/server/solr-webapp/webapp/WEB-INFvim tongweb-web.xml
添加内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<tongweb-web-app><!--<context-root>/</context-root>--><!-- <property name="aliases" value="/aliasPath1=banner,/aliasPath2=banner"/>--><!-- <property name="jspPrintNull" value="false"/>--><security-role-mapping><role-name>thanos</role-name><principal-name>thanos</principal-name><!-- <group-name>thanos</group-name > --></security-role-mapping></tongweb-web-app>
2.配置web.xml,用密码登录
cd /data/application/solr-8.9.0/server/solr-webapp/webapp/WEB-INFvi web.xml
添加内容如下:放在底部就行了
--------------------------------这是添加的内容--------------------------------------
<security-constraint> <web-resource-collection> <web-resource-name>Solr</web-resource-name> <!--描述--> <url-pattern>/</url-pattern> <!-- 验证的网页的位置--> </web-resource-collection> <auth-constraint> <role-name>thanos</role-name> <!-- 验证的角色,别写成用户名,如有多个角色可以写多个role-name 标签--> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <!-- 关键--> <realm-name>TestRealm</realm-name>
</login-config>
--------------------------------------------------------------------
</web-app>
3.重启solr服务器
配置完成后,重启solr服务器,重新访问solr就需要用户名和密码了
用户名密码是东方通/console控制台的用户密码
三、solr基于AAS(金蝶)容器配置后台登陆角色用户名密码
1.创建apusic-application.xml
cd /data/application/solr-8.9.0/server/solr-webapp/webapp/META-INF 【没有META-INF 就手动创建一个】vi apusic-application.xml
添加内容如下:
<?xml version="1.0" encoding="UTF-8"?><!DOCTYPE apusic-application PUBLIC '-//Apusic//DTD Apusic Application 3.0//EN''http://www.apusic.com/dtds/apusic-application_3_0.dtd'><apusic-application><realm-name>default</realm-name><security-role><role-name>admin</role-name><principal>admin</principal><group>administrators</group></security-role>
</apusic-application>
2.配置web.xml,用密码登录
cd /data/application/solr-8.9.0/server/solr-webapp/webapp/WEB-INFvi web.xml
添加内容如下:放在底部就行了
--------------------------------这是添加的内容--------------------------------------
<security-constraint> <web-resource-collection> <web-resource-name>Solr</web-resource-name> <!--描述--> <url-pattern>/</url-pattern> <!-- 验证的网页的位置--> </web-resource-collection> <auth-constraint> <role-name>admin</role-name> <!-- 验证的角色,别写成用户名,如有多个角色可以写多个role-name 标签--> </auth-constraint> </security-constraint> <login-config> <auth-method>BASIC</auth-method> <!-- 关键--> <realm-name>TestRealm</realm-name>
</login-config>
--------------------------------------------------------------------
</web-app>
3.重启solr服务器
配置完成后,重启solr服务器,重新访问solr就需要用户名和密码了
用户名密码是金蝶/admin控制台的用户密码
Springboot用户密码方式连接solr
配置文件application.yml
在 application.yml 文件中配置:
spring:#全文检索data:solr:host: http://124.221.212.171:8984/solruser: rootpwd: 123
新建类SolrConfig增加配置
package com.zhou.config;import com.zhou.config.Filter.HttpRequestInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.UsernamePasswordCredentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.impl.client.BasicCredentialsProvider;
import org.apache.http.impl.client.CloseableHttpClient;
import org.apache.http.impl.client.HttpClientBuilder;
import org.apache.solr.client.solrj.impl.HttpSolrClient;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.web.servlet.config.annotation.InterceptorRegistry;
import org.springframework.web.servlet.config.annotation.WebMvcConfigurer;import java.net.URI;/*** @author 刘洪荣* @description 为了实现 跨域、白白单,solr登录* @desc* @since 2022/9/1 15:41*/
@Configuration
public class SolrConfig{@Value("${spring.data.solr.user}")private String username;@Value("${spring.data.solr.pwd}")private String password;@Value("${spring.data.solr.host}")private String uri;/**** @apiNote 配置solr账号密码登录* @author 刘洪荣* @date 2021-6-8 15:05* @return {@link HttpSolrClient }*/@Beanpublic HttpSolrClient solrClient() {CredentialsProvider provider = new BasicCredentialsProvider();final URI uri = URI.create(this.uri);provider.setCredentials(new AuthScope(uri.getHost(), uri.getPort()),new UsernamePasswordCredentials(username, password));HttpClientBuilder builder = HttpClientBuilder.create();// 指定拦截器,用于设置认证信息builder.addInterceptorFirst(new SolrAuthInterceptor());builder.setDefaultCredentialsProvider(provider);CloseableHttpClient httpClient = builder.build();return new HttpSolrClient.Builder(this.uri).withHttpClient(httpClient).build();}
}
新建类SolrAuthInterceptor拦截器
import org.apache.http.HttpHost;
import org.apache.http.HttpRequest;
import org.apache.http.HttpRequestInterceptor;
import org.apache.http.auth.AuthScope;
import org.apache.http.auth.AuthState;
import org.apache.http.auth.Credentials;
import org.apache.http.client.CredentialsProvider;
import org.apache.http.client.protocol.HttpClientContext;
import org.apache.http.impl.auth.BasicScheme;
import org.apache.http.protocol.HttpContext;
import org.apache.http.protocol.HttpCoreContext;/*** @author 刘洪荣* @description solr 拦截器* @desc* @since 2022/11/14 14:02*/
public class SolrAuthInterceptor implements HttpRequestInterceptor {@Overridepublic void process(final HttpRequest request, final HttpContext context) {AuthState authState = (AuthState) context.getAttribute(HttpClientContext.TARGET_AUTH_STATE);if (authState.getAuthScheme() == null) {CredentialsProvider provider =(CredentialsProvider) context.getAttribute(HttpClientContext.CREDS_PROVIDER);HttpHost httpHost = (HttpHost) context.getAttribute(HttpCoreContext.HTTP_TARGET_HOST);AuthScope scope = new AuthScope(httpHost.getHostName(), httpHost.getPort());Credentials credentials = provider.getCredentials(scope);authState.update(new BasicScheme(), credentials);}}
}
这篇关于Linuk(包含信创Tongweb东方通,AAS金蝶)部署solr的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






