本文主要是介绍Go语言开发者的Apache Arrow使用指南:数据类型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如果你不是做大数据分析的,提到Arrow这个词,你可能会以为我要聊聊那个箭牌卫浴或是箭牌口香糖(注:其实箭牌口香糖使用的单词并非Arrow)。其实我要聊的是Apache的一个顶级项目:Arrow[1]。
为什么要聊这个项目呢?说来话长,主要是因为前段时间接触到的几个时序数据库开源项目,包括国外大名鼎鼎的InfluxDB(尤指其iox这个新存储引擎)[2]以及国内一个新初创公司的开源项目greptimedb[3]。它们其实是竞争对手,但他们有一个共同的特点,那就是时序数据在内存中的组织都是基于Arrow设计与实现的。
InfluxDB iox的主力开发者Andrew Lamb在他的一次技术分享[4]中曾提到这样一个观点:
如果你在编码实现一个分析型数据库系统,那么你最终将实现Arrow的功能集合。
在上述公司技术人员的眼中,Arrow是构建下一代时序数据库引擎的核心技术之一。
Arrow内容很多,不是一篇文章可以聊完的,因此我计划了一个系列的文章,争取能覆盖到Arrow项目的核心部分的内容,这里是第一篇。
注:Arrow是语言无关的,但这里所有代码示例使用的都是Go语言^_^。
1. Arrow项目简介
按照Arrow项目官方的说法:“Apache Arrow是一个用于内存分析的开发平台。它包含一组技术,这些技术可以使大数据系统能够快速处理和移动数据。它为平面和分层数据指定了一种标准化的独立于语言的列式内存格式,其组织形式为现代硬件上的数据的高效分析操作做了充分考虑”。
简单诠释一下上面这段话:
Apache Arrow编写了一套编程语言无关的内存格式规范[5](当前版本为v1.3),这是一种列式存储的格式,基于这种格式可以实现高压缩比的数据的压缩存储、高效的性能分析操作以及无需序列化和反序列化的低开销数据传输。
下图是展示了Arrow的列式存储格式。最上面的是一个逻辑表,这个表有三个列:ARCHER、LOCATION和YEAR,左下角是使用行式存储实现逻辑表的内存存储方式,而右下角则是Arrow的方案,即采用列式存储格式实现逻辑表的方式:
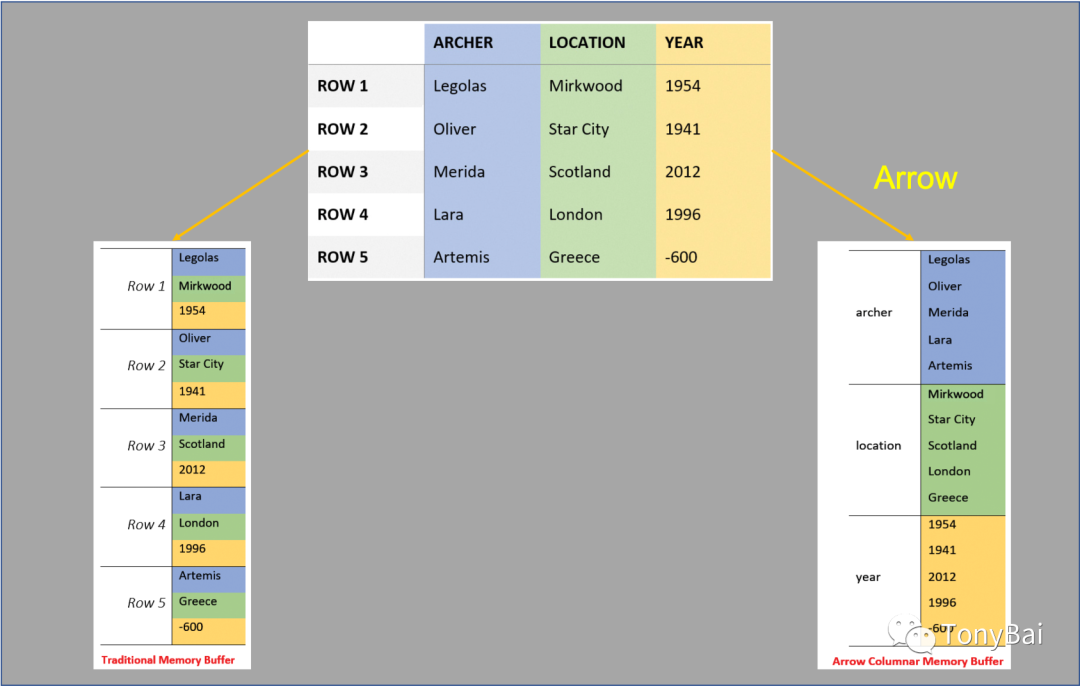
注:上图由来自《In-Memory Analytics with Apache Arrow》[6]书中的几幅图拼接而成。
一套规范,大家共尊,这样数据传递和处理时,无需序列化和反序列化
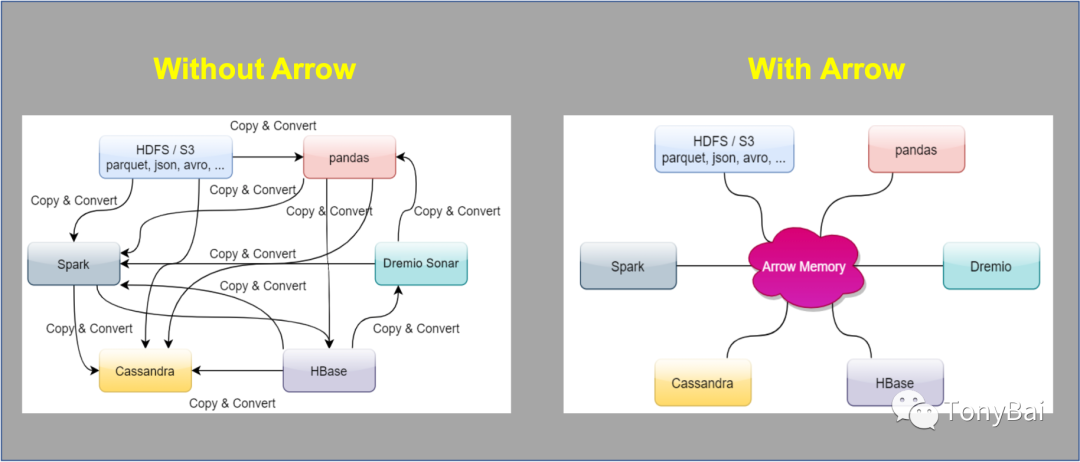
注:上图同样由来自《In-Memory Analytics with Apache Arrow》[7]书中的2幅图拼接而成。
多种主流语言的实现
下面是Arrow项目的各个编程语言的实现和支持矩阵情况:
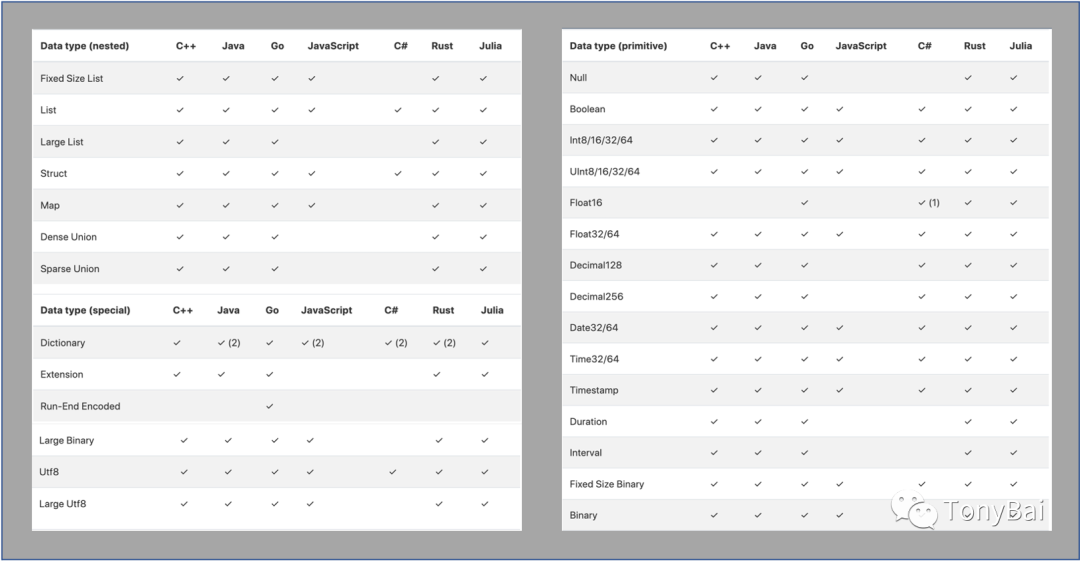
我们看到,目前C++、Java、Go和Rust等对Arrow的支持较为全面。
通信传输与磁盘存储
Arrow的子项目Arrow Flight RPC[8]为使用Arrow内存格式的系统提供了标准的通信传输方式。
Apache的另外一个顶级项目Parquet[9]则经常被用作Arrow数据的磁盘存储格式,InfluxDB iox项目也是将内存中的Arrow格式数据转换为Parquet后存储在对象存储中的。
了解了Arrow项目的大致情况后,我们接下来再来看看Arrow项目的核心规范:Arrow Columnar Format[10]。
2. Arrow Columnar Format规范
很多人最厌恶读所谓的“规范”了,太抽象,太概念化了,啃起来很烧脑。很不巧,Arrow Columnar Format规范也归属在这一类规范中。
不过,再难啃也得啃。如果不了解规范中的术语和概念,后面我们很可能就走不下去了。好在我们有《In-Memory Analytics with Apache Arrow》[11]的帮助,算是有了抓手,将书与规范结合在一起看,略微降低一些理解上的难度。
Arrow的列式格式有一些关键特性,这里引述一下:
顺序访问(扫描)的数据邻接性
O(1)(恒定时间)随机访问
对SIMD和矢量化友好
可重新定位,没有"指针摆动",允许在共享内存中实现真正的零拷贝访问
这些关键特性都在告诉我们Arrow具备一个优点:快!这也是为什么influxdb iox引擎使用Arrow作为数据在内存中组织形式的原因,Andrew Lamb在他的分享中给出了Rust使用Arrow和不使用Arrow的性能对比:

我们看到基于Arrow的实现比原生Rust实现还要快很多!
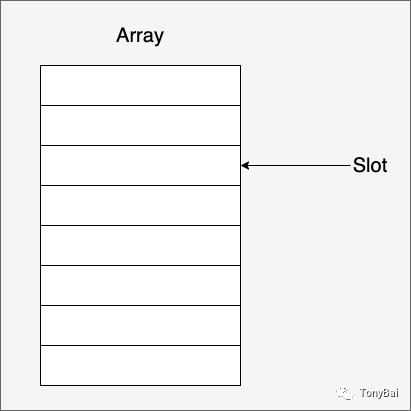
前面说过:Arrow是列式存储格式,它的核心型态就是Array。
Array是已知长度的同构类型值的序列,Array中一个值称为一个slot:
规范同时定义了承载Array的内存表示(physical layout),通常一个Array的内存表示由多个buffer构成,每个buffer实际上就是一个固定长度的连续内存区域:
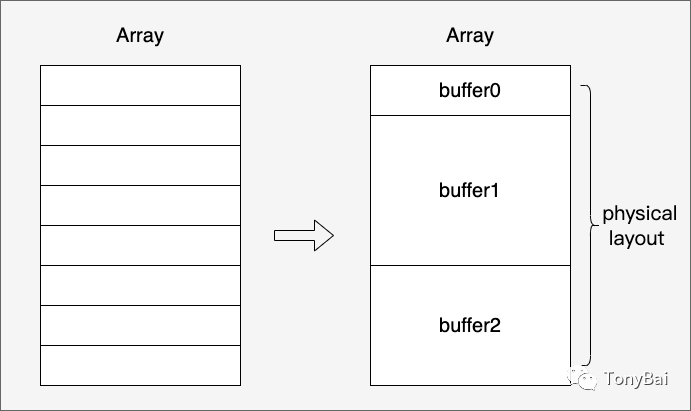
Array支持嵌套,像List<U>就是一个嵌套类型(Nested type),而List<U>称为parent array类型,而U则称为child array type。如果一个Array不是嵌套类型,那么称之为Primitive type。
要真正了解Arrow,就要了解每个Array type的physical layout,一个array type也被称为一个logical type。Arrow定义了多种logical type,它们拥有不同的physical layout,当然也可以拥有相同的physical layout。相同physical layout的logical type可以划为一类,按layout type进行分类,我们能得到下面这张表(摘自《In-Memory Analytics with Apache Arrow》[12]一书):
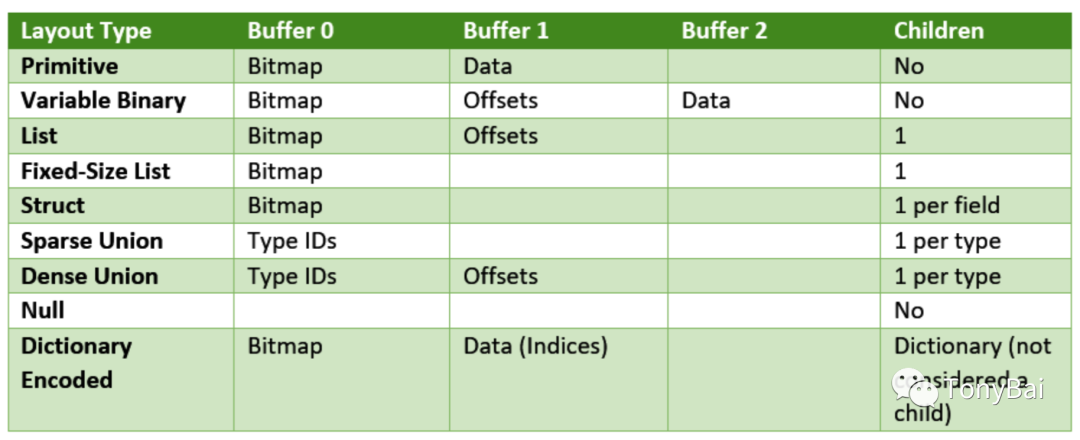
我们看到不同layout中有一些buffer并非用来存储data,比如多数layout的buffer0存储的是一个bitmap,有的buffer1存储的是offset,这些非data的信息被称为metadata。实际上,一个array是由一些metadata和真正的data组合而成的。
下面我们逐个来看看这些layout不同的Arrow array类型。
3. 数据类型
3.1 metadata
在介绍Arrow的array类型之前,我们简单说说metadata。
Arrow array有如下几个常见的属性是存放在metadata中的:
Array length:array中slot的数量,即array有几个元素,通常用64-bit signed integer表示;
Null count:null value slot的数量,同样也通常用64-bit signed integer表示;
Validity bitmaps:bitmap中的bit用来指示对应的array slot是否为null。并且arrow使用的是“小端bit序”,以一个字节(8bit)为一组,bitmap的最右侧bit指示的是array中第一个slot是否为null(未置位代表是null),下面是一个示意图:

下面是用arrow的go包实现的上述示意图中的代码示例:
// bitmap_of_array.go
package mainimport ("encoding/hex""fmt""github.com/apache/arrow/go/v13/arrow/array""github.com/apache/arrow/go/v13/arrow/memory"
)func main() {bldr := array.NewInt64Builder(memory.DefaultAllocator)defer bldr.Release()bldr.AppendValues([]int64{1, 2}, nil)bldr.AppendNull()bldr.AppendValues([]int64{4, 5, 6, 7, 8, 9, 10}, nil)arr := bldr.NewArray()defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps)) // fb 03 00 00fmt.Println(arr) // [1 2 (null) 4 5 6 7 8 9 10]
}如果一个array没有null元素,那也可以省略bitmap。
看完metadata,我们接下来就来看一些arrow定义的array逻辑类型。
3.2 Null type
Null type并非null,它是一种无需真正分配内存的logical type,下面是arrow go实现中NullType的定义:
// NullType describes a degenerate array, with zero physical storage.
type NullType struct{}我们知道struct{}不占用任何真实内存空间,NullType则“继承”了这点。
3.3 Primitive Type
Primitive type指的是slot元素类型相同且定长的arrow array type,从Go的源码中我们能找到如下这些Primitive Types:
var (PrimitiveTypes = struct {Int8 DataTypeInt16 DataTypeInt32 DataTypeInt64 DataTypeUint8 DataTypeUint16 DataTypeUint32 DataTypeUint64 DataTypeFloat32 DataTypeFloat64 DataTypeDate32 DataTypeDate64 DataType}{... ...}
)下面挑重点说说。
3.3.1 Boolean Type
Boolean Type不在上面的Primitive Types行列,但实质上,Boolean Type也属于PrimitiveType这一类。在Arrow中,Boolean array Type是使用bit对每一个slot进行存储的。我们来看一个例子:
// boolean_array_type.go
package mainimport ("encoding/hex""fmt""github.com/apache/arrow/go/v13/arrow/array""github.com/apache/arrow/go/v13/arrow/memory"
)func main() {bldr := array.NewBooleanBuilder(memory.DefaultAllocator)defer bldr.Release()bldr.AppendValues([]bool{true, false}, nil)bldr.AppendNull()bldr.AppendValues([]bool{true, true, true, false, false, false, true}, nil)arr := bldr.NewArray()defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps))bufs := arr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}这个例子输出的结果如下:
$go run boolean_array_type.go
00000000 fb 03 00 00 |....|00000000 fb 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 39 02 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |9...............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[true false (null) true true true false false false true]输出结果的第一行是bitmap的部分。
后面两段则是构成boolean array的两个buffer的layout,我们看到第一个buffer存储的是bitmap,第二个buffer则是存储的是boolean data。
大家看到这个输出结果的第一感觉是:为什么用了这么多字节?我们数了一数,每个buffer用了64字节,这与arrow对buffer的对齐要求是分不开的,默认情况下,要求buffer按64字节对齐。
3.3.2 Integer types
arrow支持各种integer type作为primitive types,这里以int32为例:
// int32_array_type.go
func main() {bldr := array.NewInt32Builder(memory.DefaultAllocator)defer bldr.Release()bldr.AppendValues([]int32{1, 2}, nil)bldr.AppendNull()bldr.AppendValues([]int32{4, 5, 6, 7, 8, 9, 10}, nil)arr := bldr.NewArray()defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps))bufs := arr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}输出上述程序的执行结果:
$go run int32_array_type.go
00000000 fb 03 00 00 |....|00000000 fb 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 01 00 00 00 02 00 00 00 00 00 00 00 04 00 00 00 |................|
00000010 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00 |................|
00000020 09 00 00 00 0a 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[1 2 (null) 4 5 6 7 8 9 10]值得注意的是:data buffer中是以小端字节序存储的int32。
3.3.3 Float types
Go对arrow的实现支持float16、float32和float64三个精度的浮点数类型,下面以float32为例,看看其layout:
// float32_array_type.go
func main() {bldr := array.NewFloat32Builder(memory.DefaultAllocator)defer bldr.Release()bldr.AppendValues([]float32{1.0, 2.0}, nil)bldr.AppendNull()bldr.AppendValues([]float32{4.0, 5.0, 6.0, 7.0, 8.0, 9.0, 10.1}, nil)arr := bldr.NewArray()defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps))bufs := arr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}输出上述程序的执行结果:
$go run float32_array_type.go
00000000 fb 03 00 00 |....|00000000 fb 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 80 3f 00 00 00 40 00 00 00 00 00 00 80 40 |...?...@.......@|
00000010 00 00 a0 40 00 00 c0 40 00 00 e0 40 00 00 00 41 |...@...@...@...A|
00000020 00 00 10 41 9a 99 21 41 00 00 00 00 00 00 00 00 |...A..!A........|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[1 2 (null) 4 5 6 7 8 9 10.1]3.4 Variable-size Binary Type
Primitive Types的slot是定长类型的,针对变长类型slot,Arrow定义了Variable-size Binary Type。在前面的那张不同类型的layout表中我们看到Variable-size Binary Type除了有bitmap buffer、data buffer外,还有一个offset buffer。
下面我们就以最为典型的字符串(string) array为例,看看Variable-size Binary Type的layout是什么样子的:
// string_array_type.gofunc main() {bldr := array.NewStringBuilder(memory.DefaultAllocator)defer bldr.Release()bldr.AppendValues([]string{"hello", "apache arrow"}, nil)arr := bldr.NewArray()defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps))bufs := arr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}运行该示例:
$go run string_array_type.go
00000000 03 |.|00000000 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 00 00 05 00 00 00 11 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 68 65 6c 6c 6f 61 70 61 63 68 65 20 61 72 72 6f |helloapache arro|
00000010 77 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |w...............|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|["hello" "apache arrow"]我们看到Variable-size Binary Type使用了三个buffer,除了第一个bitmap buffer和最后的data buffer外,中间的那个是offset buffer。在offset buffer中,arrow使用一个整型数来指示每个slot的起始offset,这里将上面例子整理成一张示意图,大家可以看的更清晰一些:
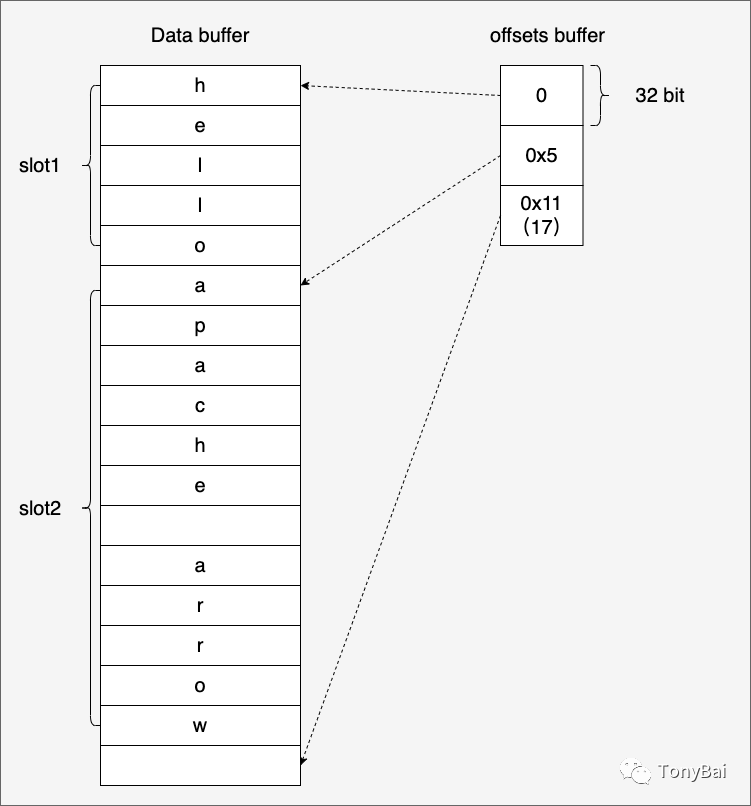
3.5 Fixed-Size List type
在上面Primitive Types的基础上,arrow提供了“嵌套类型”,比如List type。list type分为两类,一类是Fixed-Size List type,另一类则是Variable-Size List type。我们先来看Fixed-Size List type。
顾名思义,Fixed-Size List type就是list的每个slot存储的都是类型相同且定长的值,可记作:FixedSizeList<T>[N]。T可以是Primitive type或其他嵌套类型,N是T的长度。
下面是一个fixed-size list type的示例,这里的Fixed-Size List type可以表示为FixedSizeList<Int32>[3],即list中每个slot存储的都是一个[3]int32数组:
// fixed_list_array_type.go
func main() {const N = 3var (vs = [][N]int32{{0, 1, 2}, {3, 4, 5}, {6, 7, 8}, {9, -9, -8}})lb := array.NewFixedSizeListBuilder(memory.DefaultAllocator, N, arrow.PrimitiveTypes.Int32)defer lb.Release()vb := lb.ValueBuilder().(*array.Int32Builder)vb.Reserve(len(vs))for _, v := range vs {lb.Append(true)vb.AppendValues(v[:], nil)}arr := lb.NewArray().(*array.FixedSizeList)defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps))varr := arr.ListValues().(*array.Int32)bufs := varr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}我们不再像前面那样直接打印FixedSizeList的Buffer layout,我们仅输出FixedSizeList的bitmap buffer,其value的buffer需要获取到其values,然后通过values type的buffer输出。上述示例输出结果如下:
$go run fixed_list_array_type.go
00000000 0f 00 00 00 |....|00000000 ff 0f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 00 00 01 00 00 00 02 00 00 00 03 00 00 00 |................|
00000010 04 00 00 00 05 00 00 00 06 00 00 00 07 00 00 00 |................|
00000020 08 00 00 00 09 00 00 00 f7 ff ff ff f8 ff ff ff |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[[0 1 2] [3 4 5] [6 7 8] [9 -9 -8]]这里有两个bitmap,一个是FixedSizeList的,一个是其values类型的,其value类型就是一个定长的int32 primitive array type。大家也可以借助《In-Memory Analytics with Apache Arrow》书中的一幅示意图再深刻理解一下FixedSizeList的layout:
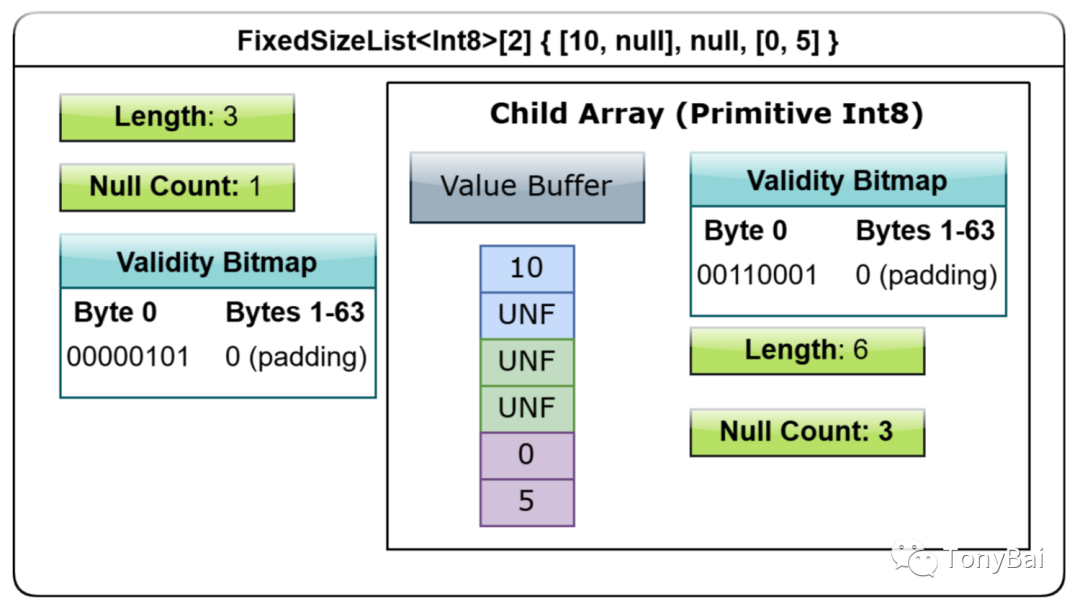
3.6 Variable-Size List type
有了FixedSizeList做铺垫,那么Variable-Size List type理解起来就容易了。和variable-size binary type一样,相较于FixedSizeList,Variable-Size List type在bitmap buffer基础上又多了一个offset buffer,我们看下面例子:
// variable_list_array_type.gofunc main() {var (vs = [][]int32{{0, 1}, {2, 3, 4, 5}, {6}, {7, 8, 9}})lb := array.NewListBuilder(memory.DefaultAllocator, arrow.PrimitiveTypes.Int32)defer lb.Release()vb := lb.ValueBuilder().(*array.Int32Builder)vb.Reserve(len(vs))for _, v := range vs {lb.Append(true)vb.AppendValues(v[:], nil)}arr := lb.NewArray().(*array.List)defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps))bufs := arr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}varr := arr.ListValues().(*array.Int32)bufs = varr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}输出上述示例的运行结果:
$go run variable_list_array_type.go
00000000 0f 00 00 00 |....|00000000 0f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 00 00 02 00 00 00 06 00 00 00 07 00 00 00 |................|
00000010 0a 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 ff 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 00 00 01 00 00 00 02 00 00 00 03 00 00 00 |................|
00000010 04 00 00 00 05 00 00 00 06 00 00 00 07 00 00 00 |................|
00000020 08 00 00 00 09 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[[0 1] [2 3 4 5] [6] [7 8 9]]前两大块数据是Variable-Size List type的bitmap buffer和offset buffer。后两大段数据则是int32 array type的bitmap buffer和data buffer。Variable-Size List type的offset buffer有四个偏移量:0, 2, 6, 7,分别指向int32 array type的data buffer中的相应位置。
《In-Memory Analytics with Apache Arrow》书中的一幅示意图可以帮助我们理解Variable-size List的layout:
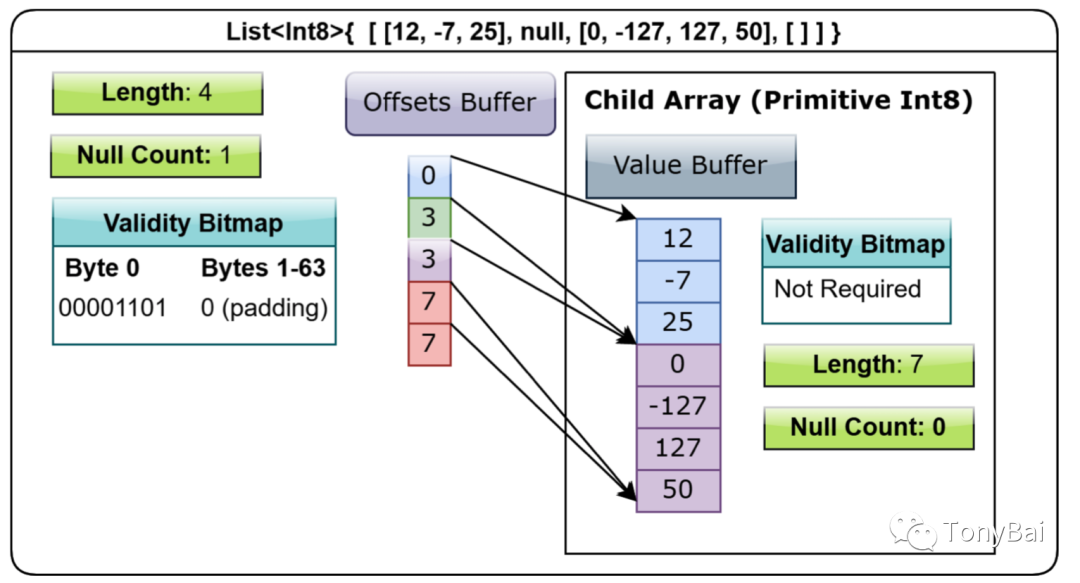
3.7 Struct type
struct也是一个嵌套类型,它可以包含多个field,而每个field又是一个arrow array type。struct的layout中包含bitmap buffer,之后就是各个field value buffer。每个field也都有自己的layout,具体layout是什么样子的需根据field的type而定。下面是一个示例,这个示例中的struct有两个field:name和age,name是一个String类型的array,而age则是int32类型的array:
// struct_array_type.go
func main() {fields := []arrow.Field{arrow.Field{Name: "name", Type: arrow.BinaryTypes.String},arrow.Field{Name: "age", Type: arrow.PrimitiveTypes.Int32},}structType := arrow.StructOf(fields...)sb := array.NewStructBuilder(memory.DefaultAllocator, structType)defer sb.Release()names := []string{"Alice", "Bob", "Charlie"}ages := []int32{25, 30, 35}valid := []bool{true, true, true}nameBuilder := sb.FieldBuilder(0).(*array.StringBuilder)ageBuilder := sb.FieldBuilder(1).(*array.Int32Builder)sb.Reserve(len(names))nameBuilder.Resize(len(names))ageBuilder.Resize(len(names))sb.AppendValues(valid)nameBuilder.AppendValues(names, valid)ageBuilder.AppendValues(ages, valid)arr := sb.NewArray().(*array.Struct)defer arr.Release()bitmaps := arr.NullBitmapBytes()fmt.Println(hex.Dump(bitmaps))bufs := arr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}nameArr := arr.Field(0).(*array.String)bufs = nameArr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}ageArr := arr.Field(1).(*array.Int32)bufs = ageArr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}执行上述代码,我们将得到如下输出:
$go run struct_array_type.go
00000000 07 00 00 00 |....|00000000 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 00 00 05 00 00 00 08 00 00 00 0f 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 41 6c 69 63 65 42 6f 62 43 68 61 72 6c 69 65 00 |AliceBobCharlie.|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 07 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 19 00 00 00 1e 00 00 00 23 00 00 00 00 00 00 00 |........#.......|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|{["Alice" "Bob" "Charlie"] [25 30 35]}第一大块数据是struct的bitmap buffer,之后的三大块数据是name field的bitmap、offset和data buffer,最后两大块数据则是age field的bitmap和data buffer。
下面是那本书中的一个struct类型layout的示意图,可以帮助大家理解这个结构:
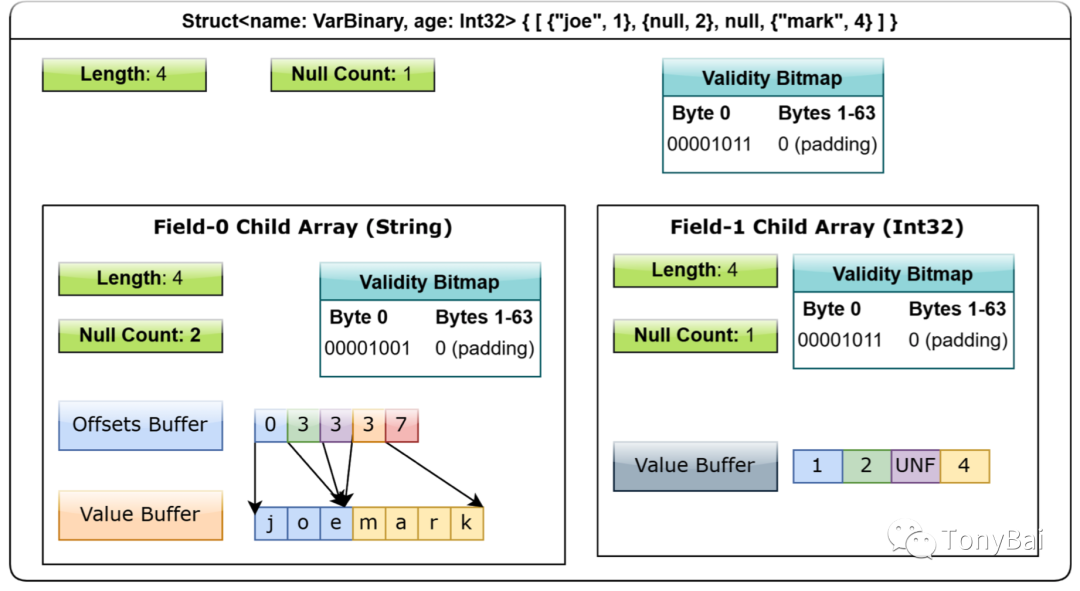
3.8 Union type
学过C语言的都知道union,名为联合体,说白了就是一堆类型共享一块内存,好比现代医学中的“多重人格”,能表现出哪种人格全由你来定。
Arrow的union array type就是每个slot中放置一个union类型的序列。Arrow的union array type还分为两种,一种为dense union type,一种是sparse union type。至于他们有什么区别,我们可以通过下面的两个示例直观的看到。union array type相对于上面的primitive type和list、struct这样的嵌套类型来说都相对难于理解一些。
我们先来看看dense union array type。
3.8.1 dense union array type
我们先看一个这样的union array: [{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}]。我们看到这个union array实例有两种union type: float32和int32。其中float32有三个值:1.2、null和3.4;int32有两个值:5和6。我们编写go代码来构建一下这个union array:
// dense_union_array_type.go var (F32 arrow.UnionTypeCode = 7I32 arrow.UnionTypeCode = 13
)func main() {childFloat32Bldr := array.NewFloat32Builder(memory.DefaultAllocator)childInt32Bldr := array.NewInt32Builder(memory.DefaultAllocator)defer func() {childFloat32Bldr.Release()childInt32Bldr.Release()}()ub := array.NewDenseUnionBuilderWithBuilders(memory.DefaultAllocator,arrow.DenseUnionOf([]arrow.Field{{Name: "f32", Type: arrow.PrimitiveTypes.Float32, Nullable: true},{Name: "i32", Type: arrow.PrimitiveTypes.Int32, Nullable: true},}, []arrow.UnionTypeCode{F32, I32}),[]array.Builder{childFloat32Bldr, childInt32Bldr})defer ub.Release()ub.Append(I32)childInt32Bldr.Append(5)ub.Append(F32)childFloat32Bldr.Append(1.2)ub.AppendNull()ub.Append(F32)childFloat32Bldr.Append(3.4)ub.Append(I32)childInt32Bldr.Append(6)arr := ub.NewDenseUnionArray()defer arr.Release()// print type bufferbuf := arr.TypeCodes().Buf()fmt.Println(hex.Dump(buf))// print offsetsoffsets := arr.RawValueOffsets()fmt.Println(offsets)fmt.Println()// print buffer of child arraybufs := arr.Field(0).Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}bufs = arr.Field(1).Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}我们看到union array的构建也是非常复杂的。按照前面的表格,dense union array type的layout中metadata占用两个buffer,第一个buffer是typeIds,第二个buffer则是offset。没有data buffer,真正的数据存储在child array的layout中。我们运行一下上面的示例直观看一下:
$go run dense_union_array_type.go
00000000 0d 07 07 07 0d 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[0 0 1 2 1]00000000 05 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 9a 99 99 3f 00 00 00 00 9a 99 59 40 00 00 00 00 |...?......Y@....|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 03 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 05 00 00 00 06 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}]第一块数据是union typeid buffer,这里我们的union array type一共有两类子类型,我分为赋予他们的typeid为float32(0x07)和int32(0x0d)。union array type一共有5个slot(3个float32,2个int32),typeids buffer这里用一个字节表示一个slot的类型,因此有3个07和2个0d。
下面输出的[0 0 1 2 1]则是一个offset buffer。表示同类type的value buffer的offset(一个offset值是一个4字节的int32)。以int32 slot为例,我们有两个int32 slot,分为位于总union array type 的第一个和第五个。但int32 slot是放在一起存储为int32 primitive array type的,因此union array type的第一个slot是int32 primitive array type的第一个slot,即其offset在int32 type中的偏移为0。而union array type的第5个slot是int32 primitive array type的第2个slot,即其offset在int32 type中的偏移为1。这就是[0 0 1 2 1]中第一个值为0和最后一个值为1的原因。依次类推,你可以算一下为何中间的三个值为0 1 2。
后面的四块数据则分别是float32 array type的buffer和int32 array type的buffer layout。我们用下图可以更直观地看到union array type的laytout:
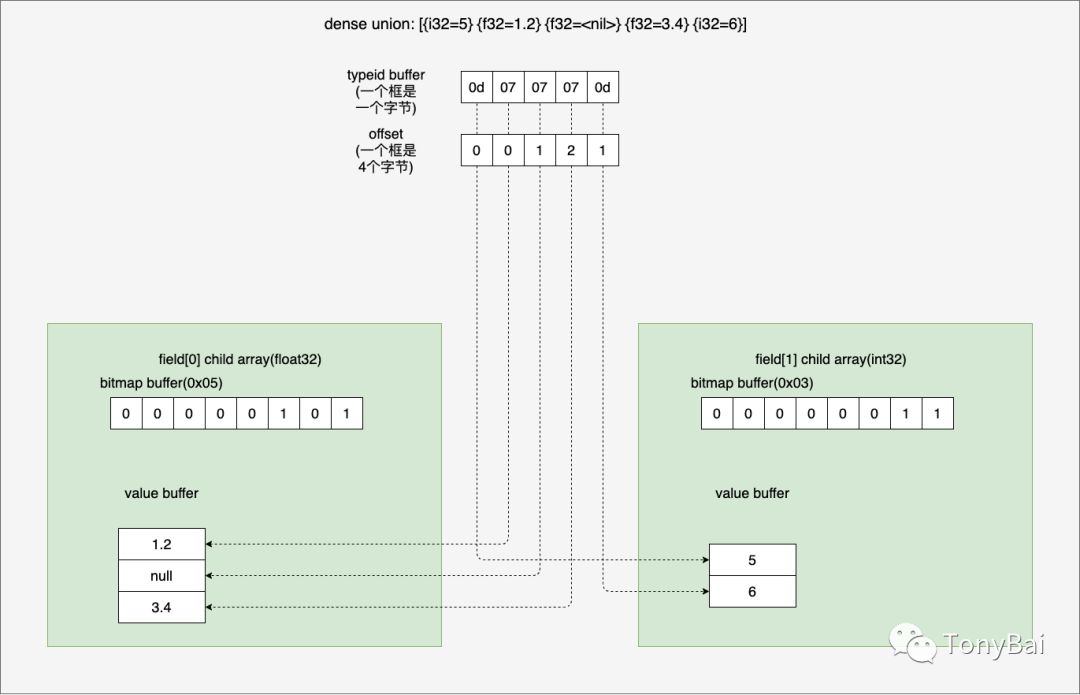
3.8.2 sparse union array type
接下来,趁热打铁,我们再来看看sparse union array type。我们还以union array: [{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}]为例,看看用sparse union array type来表示其layout是什么样子的。我们先用go构建出这个union array type:
// sparse_union_array_type.govar (F32 arrow.UnionTypeCode = 7I32 arrow.UnionTypeCode = 13
)func main() {childFloat32Bldr := array.NewFloat32Builder(memory.DefaultAllocator)childInt32Bldr := array.NewInt32Builder(memory.DefaultAllocator)defer func() {childFloat32Bldr.Release()childInt32Bldr.Release()}()ub := array.NewSparseUnionBuilderWithBuilders(memory.DefaultAllocator,arrow.SparseUnionOf([]arrow.Field{{Name: "f32", Type: arrow.PrimitiveTypes.Float32, Nullable: true},{Name: "i32", Type: arrow.PrimitiveTypes.Int32, Nullable: true},}, []arrow.UnionTypeCode{F32, I32}),[]array.Builder{childFloat32Bldr, childInt32Bldr})defer ub.Release()ub.Append(I32)childInt32Bldr.Append(5)childFloat32Bldr.AppendEmptyValue()ub.Append(F32)childFloat32Bldr.Append(1.2)childInt32Bldr.AppendEmptyValue()ub.AppendNull()ub.Append(F32)childFloat32Bldr.Append(3.4)childInt32Bldr.AppendEmptyValue()ub.Append(I32)childInt32Bldr.Append(6)childFloat32Bldr.AppendEmptyValue()arr := ub.NewSparseUnionArray()defer arr.Release()// print type bufferbuf := arr.TypeCodes().Buf()fmt.Println(hex.Dump(buf))// print childbufs := arr.Field(0).Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}bufs = arr.Field(1).Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}和dense union type相比,sparse union type要求所有child type的length都要与union type相同。这就是上述代码为什么在append一个float32后,还要append一个emtpy的int32的原因。下面是上述程序的执行结果:
$go run sparse_union_array_type.go00000000 0d 07 07 07 0d 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 1b 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 00 00 9a 99 99 3f 00 00 00 00 9a 99 59 40 |.......?......Y@|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 1f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 05 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000010 06 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|[{i32=5} {f32=1.2} {f32=<nil>} {f32=3.4} {i32=6}]同样,我们用一幅示意图可以直观的展现上述结果:
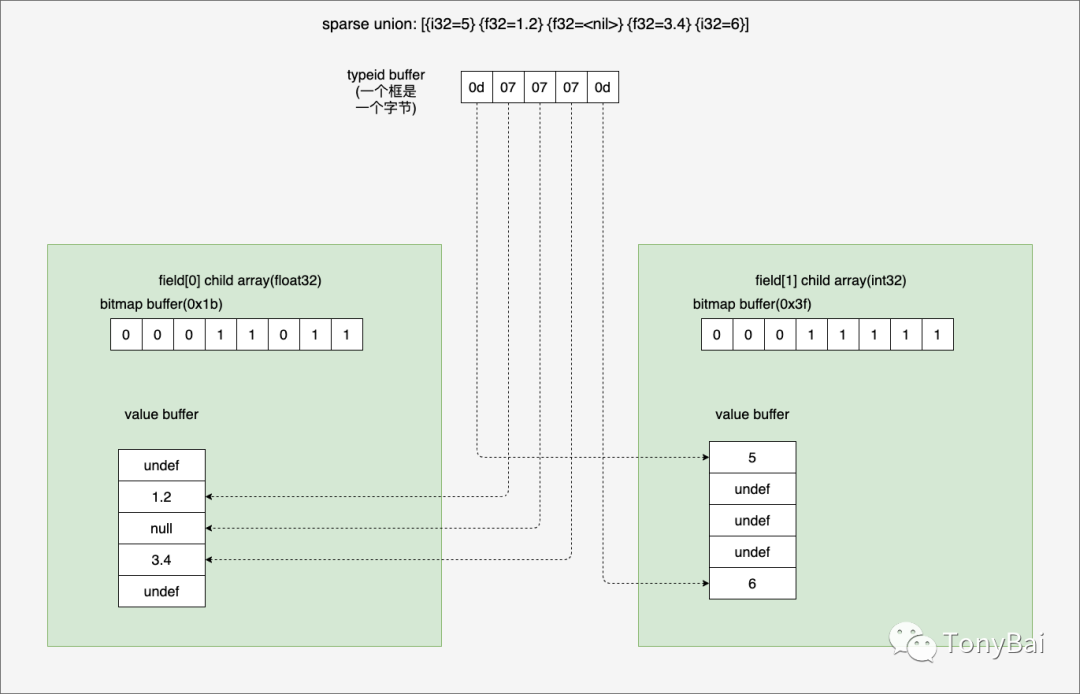
到这里,我们可以简单对比一下dense和sparse union了。显然sparse由于特殊的要求,它实际占用的内存空间会更大。
那么sparse union type用在何种场景呢?按《In Memory Analytics With Apache Arrow》书中的说法,sparse union更容易与矢量表达式求值(vectorized expression evaluation)一起使用。
3.9 Dictionary-encoded type
最后说说字典编码类型。如果现在我们要存储一组字符串,这组字符串中存在重复的值,比如:["foo", "bar", "foo", "bar", null, "baz"],若使用之前提到variable-size binary type来表示,相同的字符串不会只存储一份,而是分别存储。
针对这样的问题,Arrow提供了采用dictionary-encode的array type,在这种type下重复的字符串只会存储一份。我们看一个示例:
// dictionary_encoded_array_type.gofunc main() {dictType := &arrow.DictionaryType{IndexType: &arrow.Int8Type{}, ValueType: &arrow.StringType{}}bldr := array.NewDictionaryBuilder(memory.DefaultAllocator, dictType)defer bldr.Release()bldr.AppendValueFromString("foo")bldr.AppendValueFromString("bar")bldr.AppendValueFromString("foo")bldr.AppendValueFromString("bar")bldr.AppendNull()bldr.AppendValueFromString("baz")arr := bldr.NewDictionaryArray()defer arr.Release()bufs := arr.Data().Buffers()for _, buf := range bufs {fmt.Println(hex.Dump(buf.Buf()))}dict := arr.Dictionary()// print value string in dictbufs = dict.Data().Buffers()for _, buf := range bufs {if buf == nil {continue}fmt.Println(hex.Dump(buf.Buf()))}fmt.Println(arr)
}输出上述程序的执行结果:
$go run dictionary_encoded_array_type.go
00000000 2f 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |/...............|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 01 00 01 00 02 00 00 00 00 00 00 00 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 00 00 00 00 03 00 00 00 06 00 00 00 09 00 00 00 |................|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|00000000 66 6f 6f 62 61 72 62 61 7a 00 00 00 00 00 00 00 |foobarbaz.......|
00000010 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000020 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|
00000030 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 00 |................|{ dictionary: ["foo" "bar" "baz"]indices: [0 1 0 1 (null) 2] }对照的下面的示意图,我们可以更好的理解这大段输出:
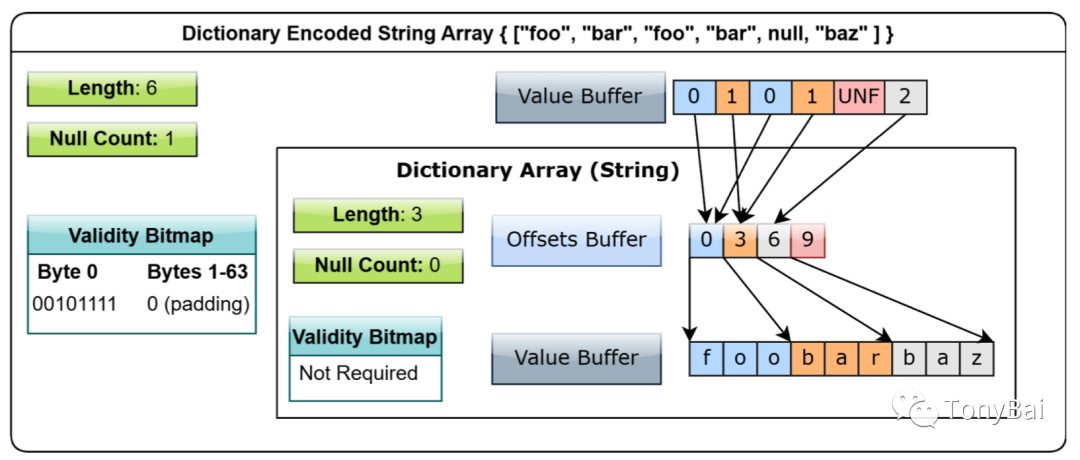
我们看到dictionary array type实际上是通过一个indices建立了到底层存储字符串的array的offset的映射来实现字典编码的,这可以大大节省内存空间。
还有一些类型,比如Time32/Time64、Date32/Date64等,其存储结构与上面的一些类型大同小异,大家可以自行研读规范以及做编码实践来理解体会。
4. Arrow格式规范的版本管理与稳定性
Arrow格式规范自1.0开始便承诺遵循semver规范,即采用major.minor.fix的版本格式。只有当major版本发生变更时,才会引入不兼容的变化。当前format的版本是1.3,所以我们可以将其视作是向后兼容的。
5. 小结
本文介绍了Apache顶级项目Arrow,这是一个旨在在内存中建立各个类型的统一格式规范的项目,基于Arrow,各个大数据系统便可以省去序列化/反序列化的动作直接操作Arrow数据;同时Arrow采用列式模型,天生适合数据处理与分析。
文中对arrow的常见array type的layout进行了分析。虽然都叫type,但arrow定义的array type是描述一个“列”的,比如primitive types中的int32 type,它表示的是一个什么样的列呢?列中元素定长:sizeof(int32)、列的长度(array length)也是fixed的。只有理解到这一层次,才能更好的理解arrow。
本文的代码和layout适用于: Arrow Columnar Format Version: 1.3版本。
注:本文涉及的源代码在这里[13]可以下载。
6. 参考资料
Arrow FAQ - https://arrow.apache.org/faq/
Arrow implementation matrix - https://arrow.apache.org/docs/status.html
influxdb团队将arrow的Go实现捐献给apache arrow项目 - https://arrow.apache.org/blog/2018/03/22/go-code-donation/
Go and Apache Arrow: building blocks for data science - https://arrow.apache.org/blog/2018/03/22/go-code-donation/
Use Apache Arrow and Go for Your Data Workflows - https://voltrondata.com/resources/use-apache-arrow-and-go-for-your-data-workflows
Make Data Files Easier to Work With Using Golang and Apache Arrow - https://voltrondata.com/resources/make-data-files-easier-to-work-with-golang-arrow
《In-Memory Analytics with Apache Arrow》- https://book.douban.com/subject/35954154/
Apache Arrow的起源及其在当今数据领域的适用性 - https://www.dremio.com/blog/the-origins-of-apache-arrow-its-fit-in-todays-data-landscape/
“Gopher部落”知识星球[14]旨在打造一个精品Go学习和进阶社群!高品质首发Go技术文章,“三天”首发阅读权,每年两期Go语言发展现状分析,每天提前1小时阅读到新鲜的Gopher日报,网课、技术专栏、图书内容前瞻,六小时内必答保证等满足你关于Go语言生态的所有需求!2023年,Gopher部落将进一步聚焦于如何编写雅、地道、可读、可测试的Go代码,关注代码质量并深入理解Go核心技术,并继续加强与星友的互动。欢迎大家加入!




著名云主机服务厂商DigitalOcean发布最新的主机计划,入门级Droplet配置升级为:1 core CPU、1G内存、25G高速SSD,价格5$/月。有使用DigitalOcean需求的朋友,可以打开这个链接地址[15]:https://m.do.co/c/bff6eed92687 开启你的DO主机之路。
Gopher Daily(Gopher每日新闻)归档仓库 - https://github.com/bigwhite/gopherdaily
我的联系方式:
微博(暂不可用):https://weibo.com/bigwhite20xx
微博2:https://weibo.com/u/6484441286
博客:tonybai.com
github: https://github.com/bigwhite

商务合作方式:撰稿、出书、培训、在线课程、合伙创业、咨询、广告合作。
参考资料
[1]
Apache的一个顶级项目:Arrow: https://arrow.apache.org
[2]InfluxDB(尤指其iox这个新存储引擎): https://github.com/influxdata/influxdb_iox
[3]greptimedb: https://github.com/GrepTimeTeam/greptimedb
[4]Andrew Lamb在他的一次技术分享: https://www.youtube.com/watch?v=dQFjKa9vKhM
[5]编程语言无关的内存格式规范: https://arrow.apache.org/docs/format/Columnar.html
[6]《In-Memory Analytics with Apache Arrow》: https://book.douban.com/subject/35954154/
[7]《In-Memory Analytics with Apache Arrow》: https://book.douban.com/subject/35954154/
[8]Arrow Flight RPC: https://arrow.apache.org/docs/format/Flight.html
[9]Apache的另外一个顶级项目Parquet: https://parquet.apache.org/
[10]Arrow Columnar Format: https://arrow.apache.org/docs/format/Columnar.html
[11]《In-Memory Analytics with Apache Arrow》: https://book.douban.com/subject/35954154/
[12]《In-Memory Analytics with Apache Arrow》: https://book.douban.com/subject/35954154/
[13]这里: https://github.com/bigwhite/experiments/blob/master/arrow/array-types
[14]“Gopher部落”知识星球: https://wx.zsxq.com/dweb2/index/group/51284458844544
[15]链接地址: https://m.do.co/c/bff6eed92687
这篇关于Go语言开发者的Apache Arrow使用指南:数据类型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





