本文主要是介绍使用Spleeter分离人声和伴奏,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目地址
spleeter是一个开源的项目,可使用预训练好的声音模型分离音频中的人声和乐器,亦可用于训练用户自己的声音模型,Github地址:Spleeter
使用流程
官方提供了使用教程,官方教程:Spleeter Wiki。这里根据我使用过程中遇到过的坑,总结了一份新的使用流程。
环境要求
- 软件要求:需要预先配置好ffmpeg,设置方法可参考ffmpeg的下载及安装
- Python环境: 3.6+
- python依赖环境:ffmpeg-python
这里可能会踩坑,如果运行时报与ffmpeg相关的错,可以尝试使用如下命令重新安装ffmpeg: pip uninstall ffmpeg pip uninstall ffmpeg-python pip install ffmpeg-python
安装spleeter
使用pip命令安装spleeter:
python -m pip install spleeter
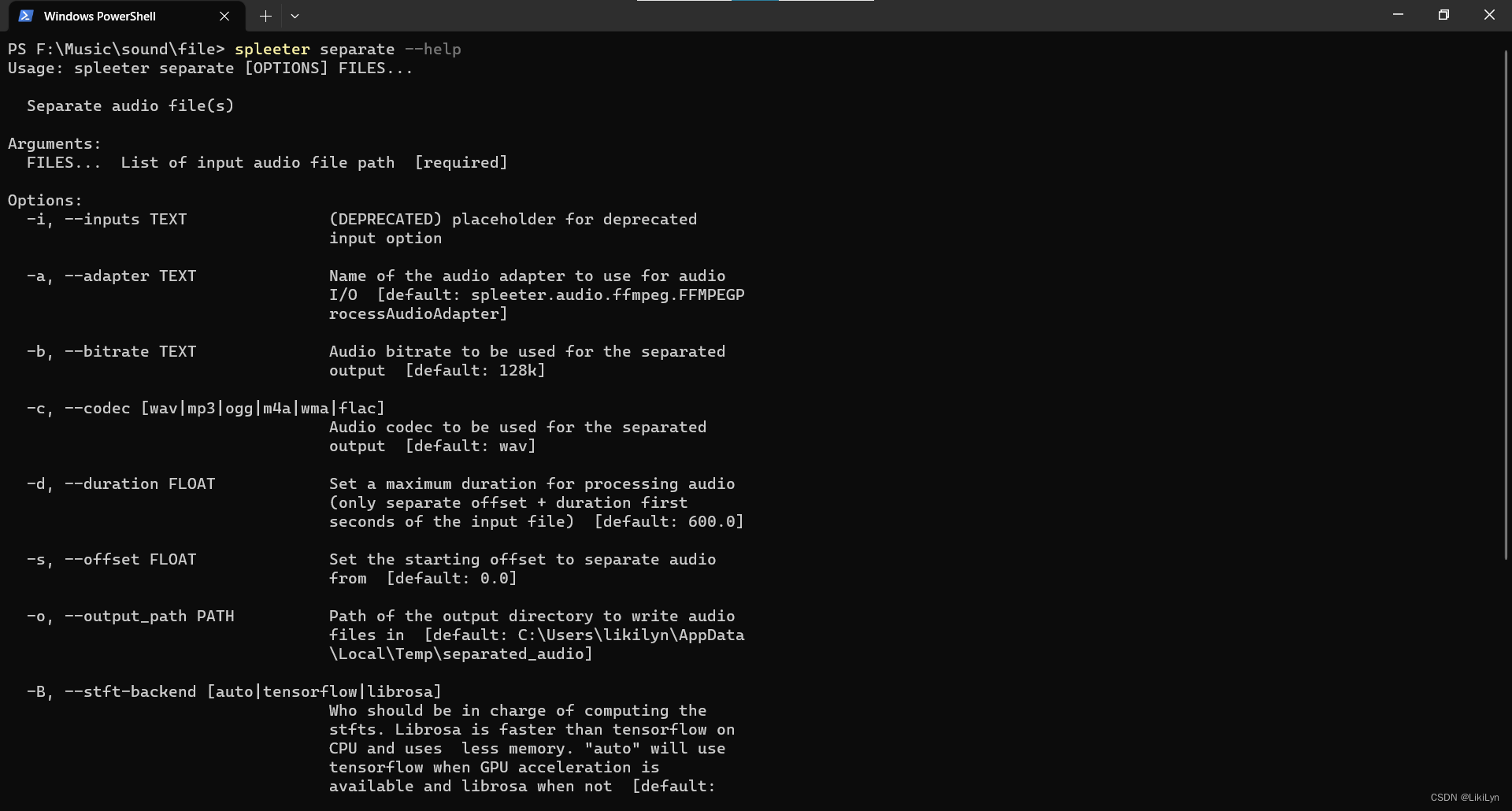
使用如下命令查看spleeter是否安装成功:
spleeter separate --help
安装成功后会出现如下界面:
下载模型
由于spleeter依赖的模型较大,这里可以使用离线下载的方式自行下载模型。
模型下载地址
下载地址:Spleeter public release
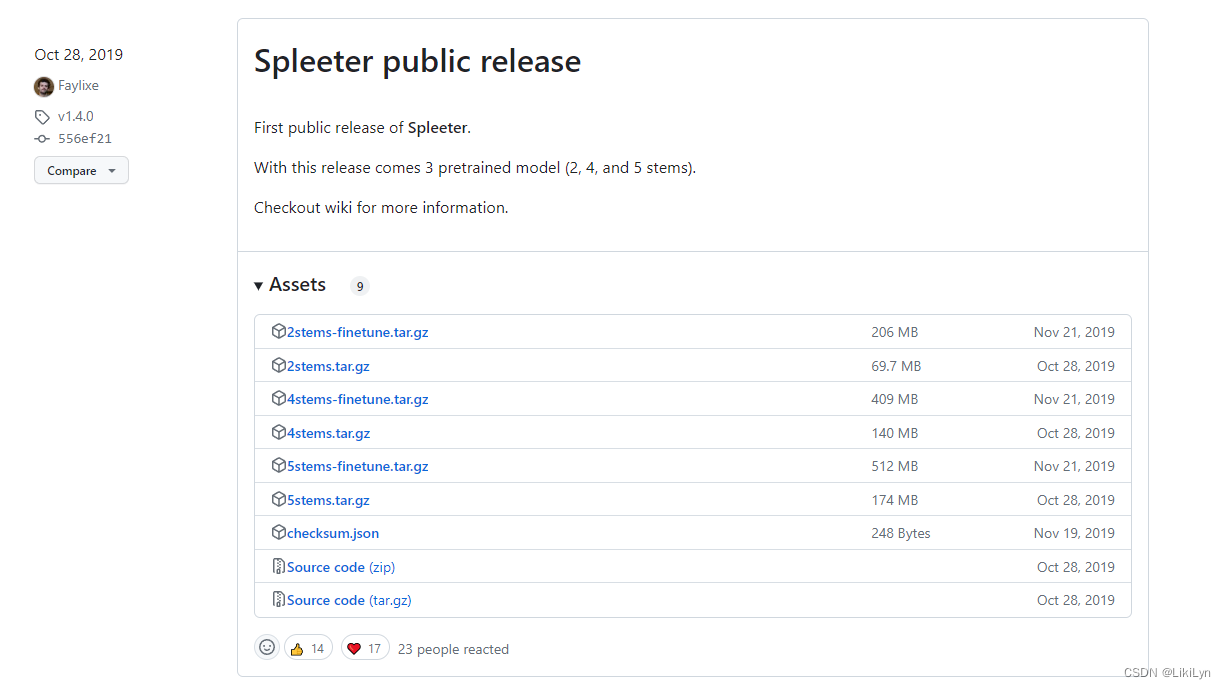
根据自己需要下载预训练模型,这里以可分离人声与伴奏的2stems为例(2stems,4stems,5stems的区别在于可以分离的声音数量不同,后两者可以将伴奏中的不同乐器声进行分离,具体区别可见项目介绍)。
下载模型——以2stems为例
- 从First Release中下载2stems.tar.gz
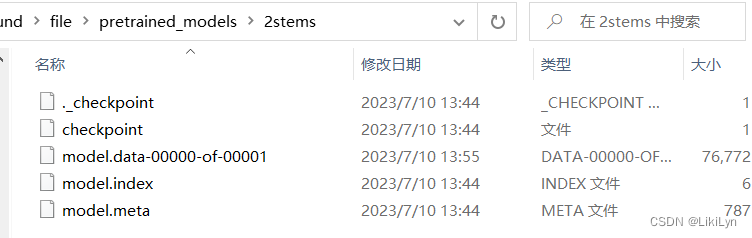
- 解压该文件,得到如下文件
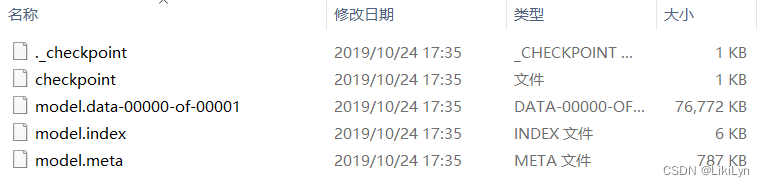
Windows解压.tar.gz文件可以参照该文章:windows如何解压tar.gz文件
如需要使用4stems和5stems模型,可自行建立相应的目录并放入模型。
运行spleeter
目录结构
如下图所示,file文件夹为项目根目录,后面的操作均基于此目录进行,将需要分离的音频文件放入file中。同时创建一个名为“pretrained_models”的目录——该目录及子目录名称不可随意更改。
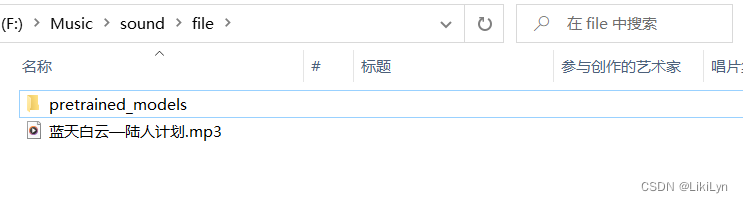
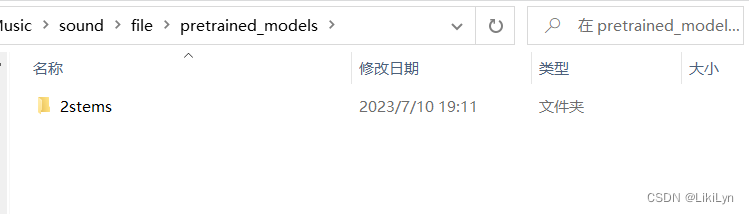
在pretrained_models目录中,创建2stems目录用于存放预训练好的模型(刚刚我们下载并解压好的模型)
运行命令
在file目录下运行该命令:
spleeter separate -o output 蓝天白云—陆人计划.mp3

上述命令的含义如下:将“蓝天白云—陆人计划.mp3”按照2stems模型进行人声与伴奏分离,并将结果保存在output目录下。-o output 指定了处理结果的存放位置,蓝天白云—陆人计划.mp3则是需要处理的文件名,在未指定-p参数时,默认使用2stems模型。其他参数可以通过help命令自行查看。
运行结果
在file->output目录下查看运行结果。


上图中的accompaniment.wav即为伴奏,vocals.wav即为人声。
这篇关于使用Spleeter分离人声和伴奏的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




