本文主要是介绍python视觉-特例仪表识别案例,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
项目文件下载地址
一、逻辑流程
1.使用检测模型提取图中的仪表
2.使用分割模型对仪表的刻度进行语义分割
3.使用检测模型提取仪表的指针
4.对各个模型的结果进行计算
二、步骤
1.提取仪表
(1)使用yolo5s进行训练200 epochs
(2)使用模型的结果对原图进行裁剪,得到仪表
2.语义分割
(1)使用deeplab对仪表的刻度条进行分割训练,训练结果在100 epoch时最佳
(2)对模型的结果进行点拟合
a.对mask图进行27* 27膨胀
b.对膨胀图进行fitEllipse椭圆拟合
c.得到椭圆的圆心(XC, YC)和长轴(R )
d.制作拟椭圆的边mask图
e.将边的mask图与膨胀图进行交运算,得到刻度的拟合曲线
f.根据卷积原理,定义3*3的卷积核遍历上一步得到的图,找到曲线的两个端点(corner_1, corner_2)
g.计算拟合曲线的长度 (length)
h.返回拟合曲线上的所有点坐标(point_axis)和XC, YC, R, corner_1, corner_2, length

3.提取指针
(1)采用yolo5x进行训练,最佳结果出现在90-100 epoch
(2)根据模型返回的结果在仪表图上进行掩膜处理,只保留指针部分
(3)对mask图进行OTSU二值处理并使用Canny算子检测边缘
(4)对边缘图进行HoughLine检测,以像素为长度单位、Π/360为弧度单位, 得到最长线段的端点(pt1, pt2)
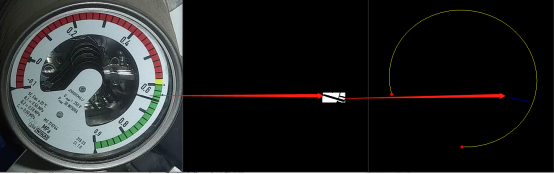
5. 计算
(1)定位指针指向的刻度位置
a.遍历point_axis,找到min(dis(pt, pt1), dis(pt, pt2)),pt即为指针指向刻度的点 corner
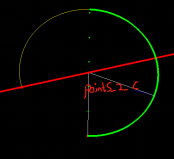
(2)计算读数比例
a.圆心角计算法:
i.计算刻度拟合线的圆心(XC, YC)与拟合曲线端点(corner_1, corner_2)、交点 corner的线段长度:line_C_1, line_C_2, line_C_c, line_c_1, line_c_2
ii.根据余弦定理计算出三个圆心角夹角:theta_1_C_c, theta_2_C_c, theta_1_C_2
iii.找到theta_1_C_c, theta_2_C_c的最小值设为theta_s, 最大值设为theta_m
iv.计算对应的theta_s, theta_m两边的偏移量bias_s, bias_m
v.计算规则:(2 * pi - theta_s - theta_1_C_2 - bias_s) / (2 * pi - theta_1_C_2 - bias_s - bias_m)

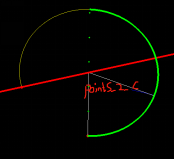
b.边计算法:
i.计算圆心(XC,YC)与pt1、pt2的斜率k_1_C、k_2_C
ii.定义两点式直线方程(x-x1)/(x2-x1) = (y-y1)/(y2-y1)
iii.采用二乘法原理,判定点在直线的上方还是下方
iv.当k_1_C、k_2_C < 0时,取直线下方的点;反之取上方的点。得到points_1_C、 points_2_C【点集合】
v.对与圆心与corner的直线,全部取直线下方的点points_c_C【点集合】
vi.计算规则 1 - len(points_1_C & points_2_C & points_c_C) / length
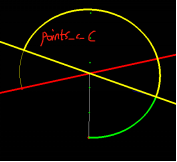
如果上述a、b两种方法计算结果误差在0.02之间,则取两者的平均值做为最终结果;反之,取最大值作为最终结果
三、问题总结
1.Deeplab给的官方文档说该网络结果适用于小目标的分割,但是实际在语义分割中对指针进行分割时,分割结果几乎为0原因:
A、该次仪表的指针非常规的指针,属于及其特例的情况,指针与表盘中间的空洞在分割特征上比较类似
B、Deeplab卷积尺度比较深,在遇到这种情况的时候,特征直接被卷积掉了,如果是常规指针,是可以分割的
C、拟合很慢,分割出现空洞和边缘不精确问题。从网络层面上,需要添加空间注意力和通道注意力机制。但是本次项目,我采用的是对结果层面的处理机制,没引入注意力机制。
相较于Unet、Segnet、FCN等网络,Deeplab对个体进行区域分割效果更好,前三者适合对单体进行分割。对于常规的仪表指针,使用Unet即可进行精确分割
2.指针提取时,由于分割模型无法分割,所有就使用yolo提取,yolo的双注意力机制比较先进,因此可以准确进行目标识别。
然后对提取的目标区域进行光学处理。最开始采用的方法是对二值图进行点的直线拟合,通过拟合线代表指针,经过测试发现实际情况中,光线、污渍都会影响二值图,从而会影响拟合的趋势走向。
所有舍弃了拟合的方法,对二值图进行轮廓检测,通过Hough变换去寻找接近的线段,经过测试组图像测试,指针定位正常
3.刻度拟合模型分割出来的mask图无法直接用于计算,需要得到每个刻度的位置信息才可进行计算。而且,一些mask图无法分割出详细刻度,只能得到一个整体的刻度mask,所以不能用刻度计算。最好的办法就是将mask图用一条曲线替代了,将这条曲线作为刻度。
一开始采用的方法是 最小二乘法进行圆拟合,通过拟合一个圆,用一段圆弧代替刻度,经过测试,实际很多图是倾斜的、畸变的,计算出来的结果误差都比较高,最大的误差能超过3个小刻度。
所以采用了弥补方案:在计算开始之前,对检测出的仪表图进行透视变换矫正,使用矫正的图去计算。测试过程中发现,图的畸变率不一样,透视变换过程中的转置矩阵和平移矩阵需要不停的调整,适用性太低。
最终就选择了比较粗暴的办法,直接对mask图进行椭圆拟合,为了防止拟合出现偏差,对mask采用比较夸张的内核进行膨胀,即27*27。这样也就填补了空洞。用拟合出来的椭圆,可以理解成也是一个mask图,和模型结果的这个mask图进行交运算,就得到了一段弧,这段弧即可比较理想的代替刻度线。
4.定位对端点、交点进行点定位,需要使用角点检测算子。尝试过了opencv自带的Harris、sobel算子,检测的结果太杂,做筛选太复杂。因此此处针对本项目做了个特例的角点检测,通过3*3卷积核进行遍历,我的目标角点特征只有一种: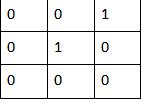
5.即便使用了过量膨胀,有时候拟合的曲线还是会存在不连续的情况,是由空洞、边缘毛凸产生,这种情况还是会导致出现多个角点,针对角点的过滤规则,目前是将角点的检测区域固定在图像下方(场景图都是正向的),然后通过仪表的物理信息设定过滤规则
由于边缘毛凸产生的拟合不连续:
这个问题还在持续解决中!!!
6.Mask被过量膨胀过,因此需要对最终结果减去误差。误差主要就来自膨胀这块,最终选定的控制规则是使用圆心与曲线端点的距离作为等腰三角形的两腰,卷积核/2作为底,三角形的顶角就是偏移量。对边计算法,偏移量则直接减去卷积核/2
这篇关于python视觉-特例仪表识别案例的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






