本文主要是介绍破解极验三代滑动验证,成功率百分之百(一):AST 反混淆,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
声明
原创文章,请勿转载!
本文内容仅限于安全研究,不公开具体源码。维护网络安全,人人有责。
环节概述
-
获取目标文件
极验的验证逻辑由多个 JS 文件共同构成,其中和滑动验证的核心逻辑来自
slide.js文件。
涉及到的文件我们可以从极验官网里直接复制到本地。
-
通过 AST 反混淆
打开刚才下载下来的文件,可以发现,里面充斥着类似下面这种完全无法阅读的代码:
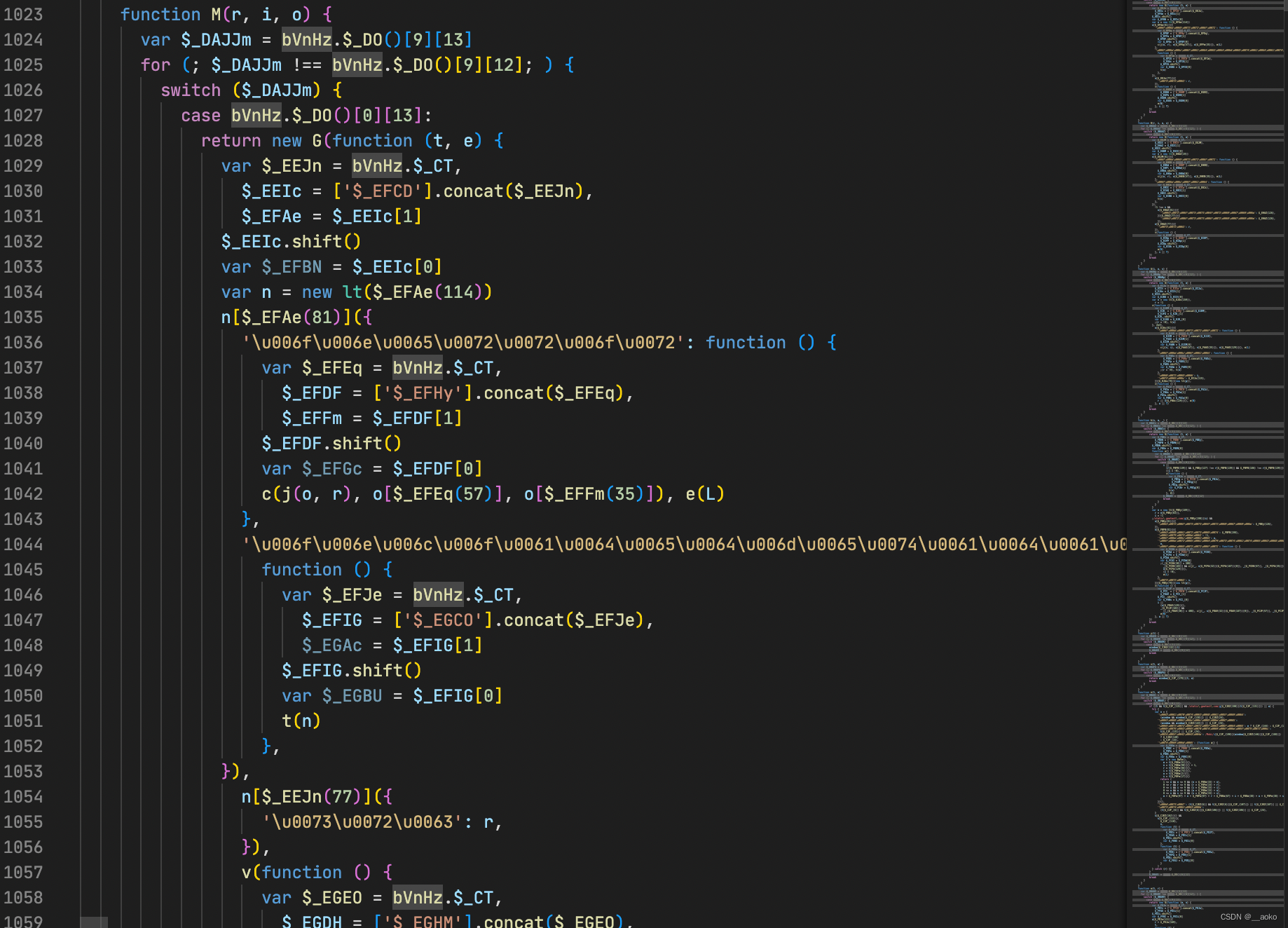
这种代码其实是对方将自己的源码通过一些特定的方式加密混淆后的结果。我们要做的就是通过观察它的一些特征,然后反过来调整 AST,最后输出成比较好理解的一些代码。关于 AST,简单来说就是通过解析代码文字本身,将其转化为一个树形结构。我强烈建议大家先了解下 AST 大概长什么样子,这个在线网站可以直观的看到代码和 AST 的对应关系。
我们这一步需要做的事情大概是这样的:读取原代码文件 -> 解析为 AST -> 处理 AST -> 输出新代码文件。
环境准备
- 首先我们需要在电脑中准备好 node 环境。推荐使用 volta 或者 nvm 这类管理工具,他们能帮助我们便捷的切换 node 和 npm 版本
- 新开一个文件夹,通过 npm init 创建下基本的 package.json 文件,然后装一些基本依赖
- 安装基本依赖:
npm install @babel/core @babel/generator
babel是一个非常常用的解析代码的工具,其中core里提供了解析代码、遍历AST的能力,以及一些辅助功能,generator提供了将AST输出为代码字符串的功能。
基本框架
在基本框架里,我们需要完成核心模块的实现,也就是读取、解析、处理以及最后输出的部分。具体如何去处理,我们在后续的步骤里逐步完善。
import fs from 'fs'
import { parse, traverse } from '@babel/core'
import generator from '@babel/generator'// 1. 读取原文件
const originCodeStr = fs.readFileSync('原代码文件地址')// 2. 解析为 AST
const ast = parse(originCodeStr)// 3. 处理 AST
const processList = [] // 具体处理 AST 的逻辑后续会逐步追加到这里
// processList.push(...)
processList.forEach((process) => {traverse(ast, process())
})// 4. 输出为新文件
fs.writeFileSync('新代码的文件地址',generator(ast, { jsescOption: { minimal: true } }).code
)
处理 AST
下面列出的多个函数,最后 push 到上面的 processList 中即可
-
移除 unicode
首先我们可以看到,代码里有很多
/uxxxx的东西,我们首先要把这个 unicode 转换为平常我们使用的语言。const removeUnicode = () => ({StringLiteral(path) {delete path.node.extra} })效果:

-
简化引用关系
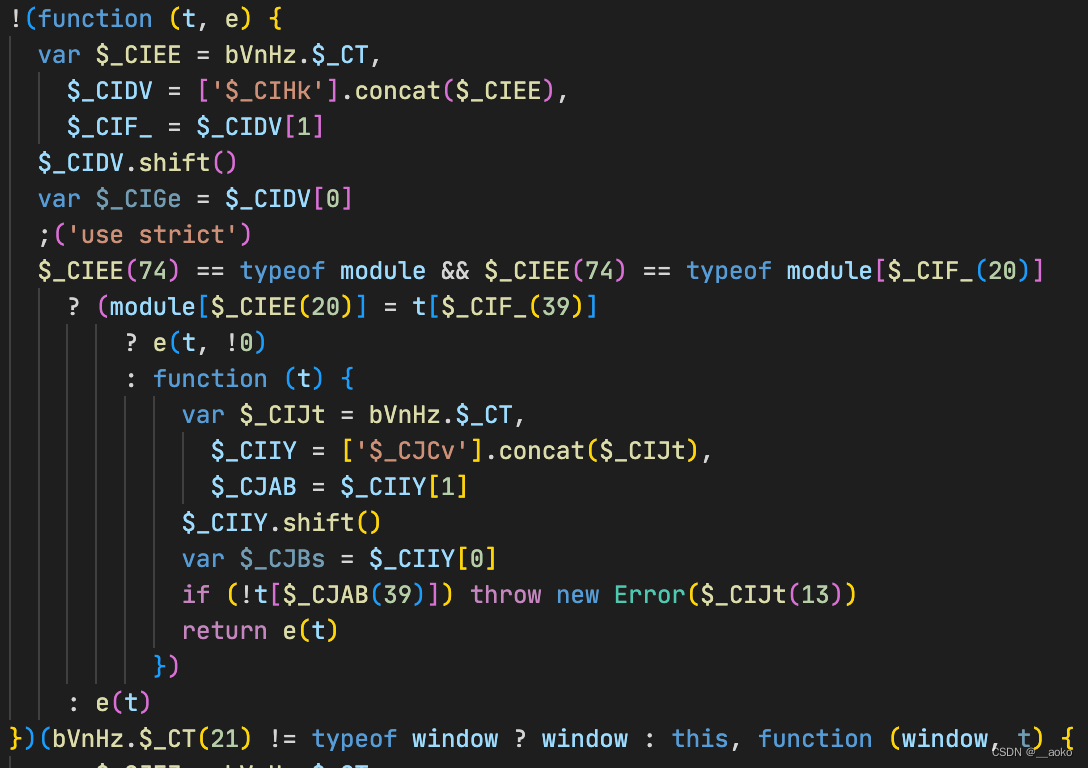
观察代码,发现 JS 文件里,有个基本的对象,然后在主逻辑里,存在多处对这个对象的引用。

以下面第一个箭头所指的部分举例:
$_CT、$_CIEE、$_CIF_三者其实都是一个东西,所以我们可以把这里的直接化简掉。同时它们都是一个函数,并且最后会调用它。我们可以直接用函数的执行结果做替换,进一步化简。
所以我们这里要做的事情有这么几点:
-
获取基本对象所有被引用的地方,以及对应的变量名叫什么,并移除无用代码
// 基本对象的四个字段名 const baseFnName = ['$_AP', '$_Bi', '$_CT', '$_DO'] // 用来缓存变量名前后的关系 const replaceNameMap = {}const getNameList = () => ({VariableDeclaration(path) {const { kind, declarations } = path.nodeconst propertyName = declarations[0]?.init?.property?.name// 代码特征if (kind !== 'var' || declarations.length !== 3 || !baseFnName.includes(name)) {return}// 待替换节点变量名const inputVarName = declarations[0].id.name// 待输出变量名const outputVarName = declarations[2].id.namereplaceNameMap[inputVarName] = namereplaceNameMap[outputVarName] = name// 移除无用代码path.getNextSibling().getNextSibling().remove()path.getNextSibling().remove()path.remove()}, }) -
执行目标函数,替换引用关系
// 把之前的 obj 抠出来,接下来我们需要运行下他里面的方法 const obj = {}const restoreVar = () => ({CallExpression(path) {const replaceNameArray = () => {const { callee, arguments: args } = path.node// 先做些特征判断if (!callee || !args?.length) {return}const name = callee.nameif (!replaceNameMap[name]) {return}// 替换变量const value = obj[replaceNameMap[name]](args[0].value)path.replaceWith(types.stringLiteral(value))}const replaceTargetField = () => {const { callee, arguments: args } = path.node// 先做些特征判断if (!args?.length) {return}if (args[0].type !== 'NumericLiteral') {return}if (callee.type !== 'MemberExpression') {return}const { object, property } = calleeif (object.type !== 'Identifier' || property.type !== 'Identifier') {return}if (!baseFnName.includes(property.name)) {return}// 替换变量const value = obj[property.name](args[0].value)path.replaceWith(types.stringLiteral(value))}replaceNameArray()replaceTargetField()}, })效果:
-
-
反流程平坦化
观察代码我们还会发现,代码整体充斥着 for switch 的嵌套逻辑,完全看不懂里面做了点什么。
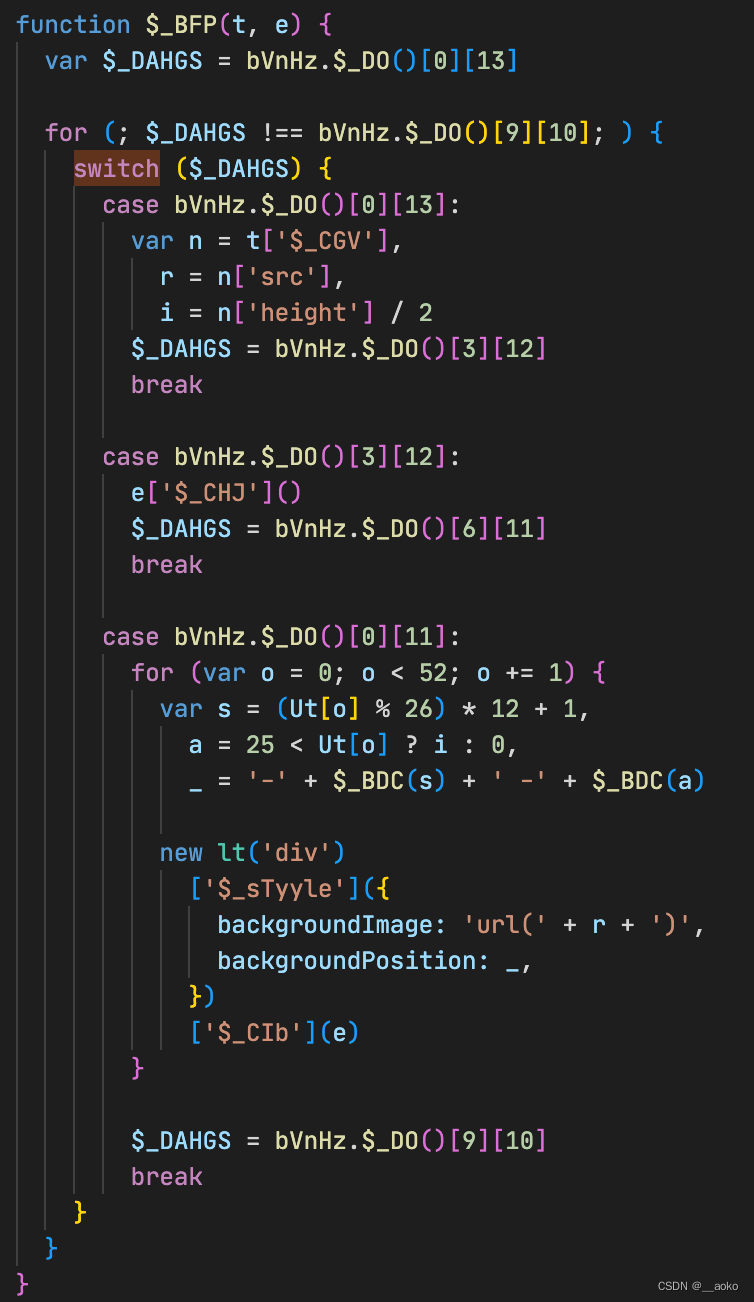
这个就是一个标准的流程平坦化操作,具体大家可以搜索看看他的一些定义和解释。简单来说,就是把原本线性的逻辑,转化为了一个由某个模块控制的循环逻辑,每次循环都会改变一些条件从而走向不同的分支,最后逻辑执行完毕后会走向一个结束分支。
这块儿的特征也是非常的明显,我们所需要做的就是,把离散的流程分支跑一遍,然后把结果做替换
const flat = () => ({ForStatement(path) {const prevNodePath = path.getPrevSibling()if (!types.isVariableDeclaration(prevNodePath)) {return}const init = prevNodePath.node.declarations?.[0]?.initif (!init) {return}const initFirstObject = init.objectif (!initFirstObject) {return}const initFirstObjectObject = initFirstObject.objectif (!initFirstObjectObject) {return}const callee = initFirstObjectObject.calleeif (!callee) {return}const name = callee.property?.nameif (!baseFnName.includes(name)) {return}const switchNode = path.node.body?.body?.[0]if (!types.isSwitchStatement(switchNode) || !switchNode.discriminant) {return}const test = path.node.testif (!test) {return}const testRight = test.rightif (!testRight) {return}// 控制流初始值const baseFnFirstParam = initFirstObject.property.valueconst baseFnSecondParam = init.property.valuelet initState = obj[name]()[baseFnFirstParam][baseFnSecondParam]// for 循环的参数const breakFirstParam = testRight.object?.property?.valueconst breakSecondParam = testRight.property?.valueconst breakState = obj[name]()[breakFirstParam][breakSecondParam]const caseList = switchNode.casesconst resultList = []// 遍历 casesfor (const caseItem of caseList) {while (initState !== breakState) {const caseFirstParam = caseItem.test.object.property.valueconst caseSecondParam = caseItem.test.property.valueconst caseState = obj[name]()[caseFirstParam][caseSecondParam]if (initState !== caseState) {break}const caseContent = caseItem.consequentif (types.isBreakStatement(caseContent.at(-1)) &&types.isExpressionStatement(caseContent.at(-2)) &&caseContent.at(-2).expression.right.object.object.callee.object.name === objName) {const firstParam = caseContent.at(-2).expression.right.object.property.valueconst secondParam = caseContent.at(-2).expression.right.property.valueinitState = obj[name]()[firstParam][secondParam]caseContent.pop()caseContent.pop()} else if (types.isBreakStatement(caseContent.at(-1))) {caseContent.pop()}resultList.push(caseContent)break}}path.replaceWithMultiple(resultList.flat(1))prevNodePath.remove()}, })效果:

总结
这一节内容里,我们搭建了基本的代码环境,下载了目标代码,并对目标代码做了解析和处理,生成了能够进行阅读的新代码。对于处理部分,我只列出了最核心的部分,如果大家还希望对代码做其他处理,可以自行扩展(比如我可能还喜欢用 prettier 把代码做一次格式化)。
另外针对不同版本的 slide 文件,或者针对极验其他的 JS 文件,均可采用同方式来做处理,只需要替换下基本的 obj 对象即可(具体 obj 对象是啥自己从代码里扣下来吧)。
下一节我们要开始对滑动验证页面的图片做分析和处理,来还原缺口图片并得到所需的滑动距离。
本期文章到这里就结束了,如果对您有帮助,记得收藏关注,有什么想法也可以联系我哦。
后续内容持续更新中。。。
这篇关于破解极验三代滑动验证,成功率百分之百(一):AST 反混淆的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








