本文主要是介绍干货!多模态学习的机遇与挑战|PhD Debate-4,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击蓝字

关注我们
AI TIME欢迎每一位AI爱好者的加入!
在信息技术飞速发展的今天,多模态数据已经成为近年来数据资源的主要形式,因此研究多模态学习的发展赋予计算机理解多元异构数据的能力就具有着重要的价值。利用多种模态,对深度学习的研究具有重要的意义。同时多模态的数据也可为模型的决策提供更多的信息,从而提高决策总体的准确率。
7月3日,PhD Debate第四期“多模态学习的机遇与挑战”,AI TIME特别邀请了清华大学的仝美涵、浙江大学的张圣宇、大连理工大学的刘晋源,并由西安交通大学的赵子祥和李健铨主持。
一、多模态是什么,优势是什么

仝美涵从多模态的定义方面将多模态的认知分成两个方向,一种认知是用不同的感知机器去获取数据,另一种是文本、图像、视频以及语音等多模态的分类表达。而多模态的优势在于数据天然是以多种模态存在的,如果我们能够去进行多模态的融合,那么就可以去更全面的获取信息。对于我的研究领域,新闻分析而言,会有文本记录、也有现场照片、采访者的音频以及现场视频,如果能够充分利用这些异构,对于细粒度的语义理解,对话意图识别以及情感的分析是非常有帮助的。那么另一个优势,在于能够提供更加人性化的人机交互。
张圣宇则对比单模态和多模态在形式上的差异,多模态具有丰富的形式。比如视频、图片、文本和音频,其实有着针对性,对于人类而言,图片对应我们的眼睛,音频对应耳朵,自然语言对应嘴巴或者记录等。
赵子祥从他的角度将多模态分为三种形式:
1、 描述同一个对象的多媒体数据,例如某一个特定对象的视频图片、音频文本等信息。
2、 来自不同感知器的同一个媒体数据,例如MRI和CT等图像的融合。
3、 具有不同的数据结构特点的数据融合,例如描述同一个数学概念,公式、逻辑符号,函数图,解释文本等。
并且他认为多模态的优势在于可以通过对于冗余信息的删除和互补信息的补充,完成对目标更清晰准确的表征和认知。
刘晋源则通过自动驾驶中的可见光、红外、激光雷达等测量方式加深了多模态的优势方面,通过多种图像生成方式,适应不同种类的场景,使得自动驾驶中的场景描述更加的可靠,更加详细。
二、多模态的技术瓶颈和挑战是什么

张圣宇首先从技术的角度描述了目前遇到的瓶颈,并且将其分为几个阶段,首先是从感知到认知,最后到决策。其认为在多模态中,感知层面对应着关联以及表征,在多模态研究时需要在多个模态的细粒度上学关联。而关联的挑战有两个,一个是多模态存在结构上的鸿沟,另一个是语义上的鸿沟。而这种多模态中每一种模态都存在这种底层的,和结构上的底层特征的鸿沟,两者就是交叉之后语义上的难点。在表征上,动态学习仍然有着两个挑战,其一是表征学习所需要的大规模预训练,其中迁移复用的泛化能力,其二则是特定领域的建模。
赵子祥从三个方面阐述了他认为的多模态的技术瓶颈。第一点是数据方面,不同于单模态,多模态的数据更多的是综合性的数据,例如视频中的图像和语音;第二点是特征提取能力,或者说我们如何的去排除冗余信息,然后提出互补信息;第三点则是特征对齐模块的设计,从耦合的结构来说就是两种模态,在某些层面上存在关联,而我们需要完成后面的冗余特征或者互补特征的综合的利用,而今后会出现我们目前不甚了解的模态,这会成为今后的技术瓶颈。
刘晋源补充到,在真实的数据中,存在数据配准的问题,以及应用方面存在可用于改进的地步。
仝美涵针对下游任务提出了自己的见解,关于如何从不同模态中挑选比较有足够有价值的信息,如何处理数据融合,如何处理模态数据缺失。例如尝试去构建多模态教育知识图谱,但是对于某一个知识点,它可能只有文字描述,有时候可能只有图片描述,那么如何在某个数据缺失的情景下,保证多模态感知模型的鲁棒性是一个挑战。
三、多模态的技术细节
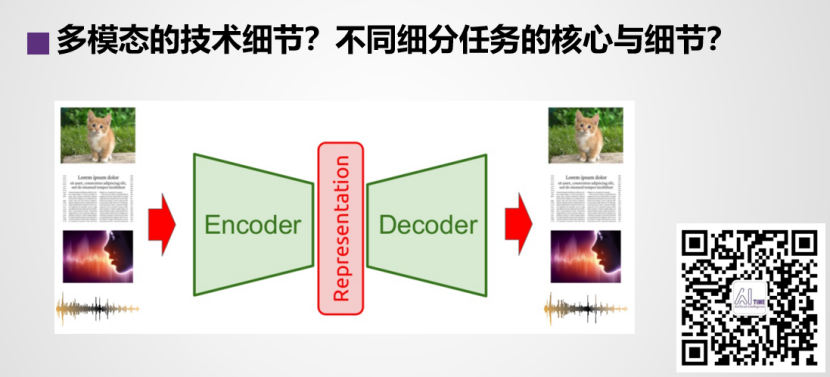
赵子祥首先从多模态的技术细节开始,他把多模态学习分成了5个步骤,分别为多模态表征学习、模态转换、对齐、多模态融合和协同学习。第一个多模态表征学习是指通过利用多模的互补性提出模态之间的冗余性,从而学习到更好的特征表示。第二个是模态转换,主要是负责一个模态的信息转化成另一个模态信息。第三个是对齐,即同一个实例在不同的物态之间的子分支或者是元素之间的关系。第四个是多模态融合,对应原始数据的融合,抽象特征的融合,决策层面的融合。最后一个是协同学习,通过一个资源丰富的模态信息来到辅助另一个资源相对贫瘠的模态进行学习,另外还有一种是协同训练,负责研究如何在多模态的数据层面上扩充数据,得到更多的标注信息。对于不同细节任务的核心和细分,他主要从多模态图像融合和图像处理角度展开。
刘晋源在此基础上补充了多模态图像融合的深度学习领域中的两个优化方向,分别是网络结构层面的优化,另一个是损失函数的优化。
张圣宇对动态多模领域做了详细的梳理。通过对他曾经做的推荐任务,多模态怎么跟推荐结合是一个很直观但又不那么直观的一个问题。他从两个思路去设计,针对推荐细分任务,一个角度是分析它的决策过程,然后把它看到的,听到的多模态的内容加进去建模。另外一个是被动的,囫囵吞枣的把能想到的在推荐上可能有用的信息都加进去,通过因果的思想和方法,例如把里面的某些模态的信息去掉,任务的预测目标会发生哪些的变化。
仝美涵从模态相互生成,比如说图片生成文本或者文本生成图片的角度进行了分享。难点在于连续的图片实现离散的突破,以及离散的表达形成连续的像素分布。
四、多模态未来的工业应用

刘晋源首先从图像方面讲述了他的经验。主要可以分为三个方面,第一个是自动驾驶,在智能驾驶的过程中需要很多传感器去进行协同的优化,单个模态难以去进行合理的视觉感知,可以引入到红外、可见光雷达、激光雷达等进行联合优化。第二个方面是在智慧医疗方面,比如现在做一些癌症的检测,就需要用一些结构解剖的影像。第三个方面是工业缺陷检测。
张圣宇介绍了杨红霞老师组的M6模型,超大规模多模态预训练。这个模型能够实现服饰设计。
仝美涵则介绍了阿里双11时的AI设计海报,多达4亿张。而且多模态还能实现更为舒适的人机交互。
五、多模态的研究热点和未来发方向

张圣宇从发论文的角度提出了几点发展方向。第一个是挖掘新任务;第二个是发展新的数据。从方法上来说,他认为未来的发展方向之一为因果,其有三种形式,分别为因果观念,共因,和选择偏差。此外对同一种任务,发展出不同的方向。
赵子祥补充了几点,他认为未来的发展热点包括有,数据规模和质量,为新任务设定新的基准,以及特征提取。
刘晋源提出了前序步骤和后期步骤的联合学习在未来发展中的重要性。
仝美涵从自然语言角度阐述了她的观点,未来的一个方向是训练一个大规模的多模态预训练模型,同时输入文本和图像,最终获得统一空间的表示。而对于后续的任务,只需要进行分类,而无需融合。
AI TIME欢迎AI领域学者投稿,期待大家剖析学科历史发展和前沿技术。针对热门话题,我们将邀请专家一起论道。同时,我们也长期招募优质的撰稿人,顶级的平台需要顶级的你!
请将简历等信息发至yun.he@aminer.cn!
微信联系:AITIME_HY
AI TIME是清华大学计算机系一群关注人工智能发展,并有思想情怀的青年学者们创办的圈子,旨在发扬科学思辨精神,邀请各界人士对人工智能理论、算法、场景、应用的本质问题进行探索,加强思想碰撞,打造一个知识分享的聚集地。

更多资讯请扫码关注

(点击“阅读原文”查看精彩回放)
这篇关于干货!多模态学习的机遇与挑战|PhD Debate-4的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







