本文主要是介绍自动化测试框架中如何记录日志更加已读 ?一文介绍使用loguru来管理日志的心得。,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

只要做代码开发,记录日志必不可少的 ,对于像我这样的测试开发同学也是 ,你在编写自动化时如何记录日志 ?怎么要日志记录更容易已读 ?如何备份日志文件 ? 这都是我们在编写代码时要考虑的问题 ,如果你也遇到了这样的问题 ,不妨看看如下的这篇文章 。
目录结构
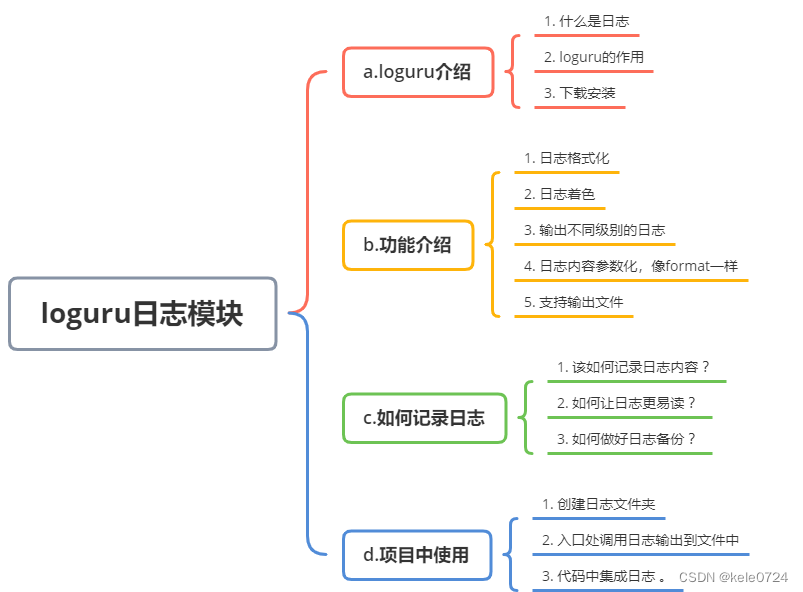
1. loguru介绍
1.1 什么是日志 ?
程序运行过程中,难免会遇到各种报错 。如果这种报错是在本地发现的 ,你还可以进行debug 。但是如果程序已经上线了 ,你就不能使用debug方式了 。这种情况下该如何解决呢 ?目前通用的方式就是在软件中记录主要的操作轨迹和数据,以便在软件报错时可以方便查找到报错原因 。这种记录程序的操作轨迹和数据的方式叫记录日志 。
目前记录日志,都是使用专门的日志模块来进行记录的。而不同的开发语言所使用的日志模块也有所不同 。像python最常用的两个日志模块就是logging和loguru .
相比logging而言 ,loguru使用起来更加简单并也能满足记日志的需求 ,接下来就来介绍下loguru的使用 。
1.2 loguru的作用
loguru是python 开发的一个第三方模块 , 主要用于记录python程序的日志 。其特点就是简单易用 、功能强大 。
1.3 安装与导入
# 下载与安装
pip install loguru
# 验证 :
pip show loguru
# 导入
from loguru import logger
# 说明 :通过上述的导入,直接导入的是对象。而且是一个单例对象 ,即整个项目都可以使用这一个对象来操作,无需担心生成多份同样的日志2.主要功能
在loguru中主要包括如下功能 :
-
已经格式化后的日志
-
日志着色
-
输出不同级别的日志
-
日志内容参数化,像format一样
-
支持输出到文件,并支持分割、备份等操作 。
2.1 输出日志
# 导包
from loguru import logger
# 生成debug、info、success、warning、error日志
logger.debug("这是一条debug日志")
logger.info("这是一条info日志")
logger.success("这是一条success日志")
logger.warning("这是一条warning日志")
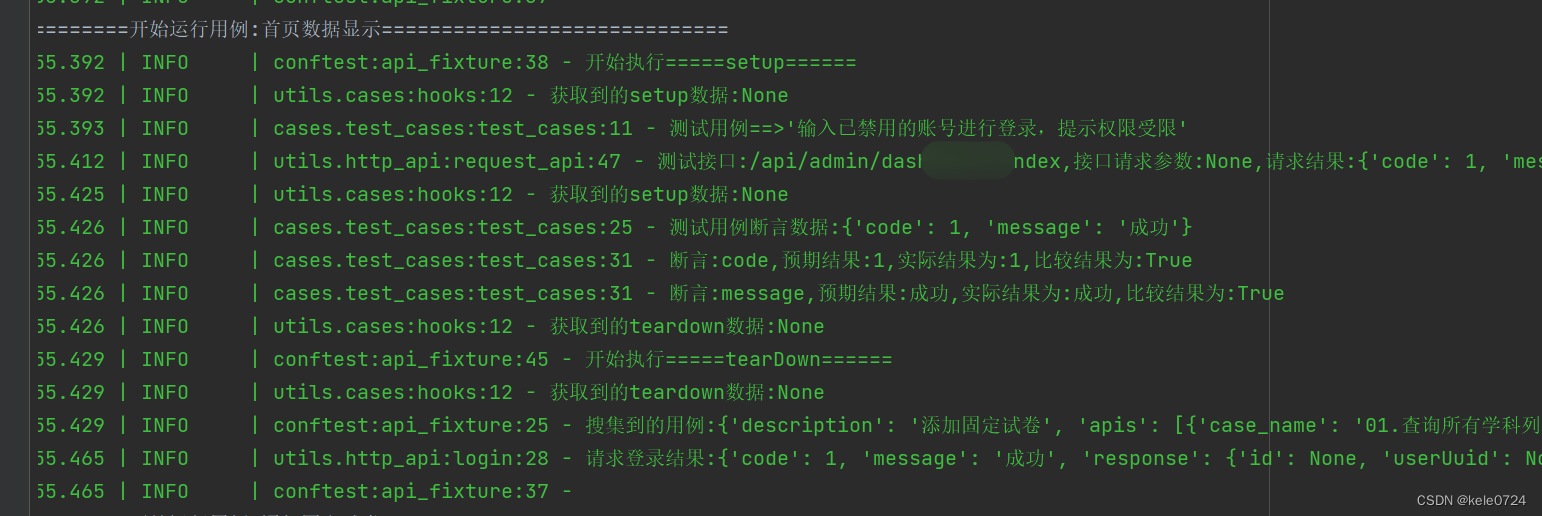
logger.error("这是一条error日志")以上内容的输出为 :
通过以上可以看到 ,只要随便打印一条日志 ,它的日志已经有了默认的格式了 。以下为源代码中的默认日志格式 :
LOGURU_FORMAT = env("LOGURU_FORMAT",str,"<green>{time:YYYY-MM-DD HH:mm:ss.SSS}</green> | ""<level>{level: <8}</level> | ""<cyan>{name}</cyan>:<cyan>{function}</cyan>:<cyan>{line}</cyan> - <level>{message}</level>",
)以下为源码中的日志级别定义 ,级别日志依次为 :
LOGURU_TRACE_NO = env("LOGURU_TRACE_NO", int, 5)
LOGURU_TRACE_COLOR = env("LOGURU_TRACE_COLOR", str, "<cyan><bold>")
LOGURU_TRACE_ICON = env("LOGURU_TRACE_ICON", str, "✏️") # Pencil
LOGURU_DEBUG_NO = env("LOGURU_DEBUG_NO", int, 10)
LOGURU_DEBUG_COLOR = env("LOGURU_DEBUG_COLOR", str, "<blue><bold>")
LOGURU_DEBUG_ICON = env("LOGURU_DEBUG_ICON", str, "🐞") # Lady Beetle
LOGURU_INFO_NO = env("LOGURU_INFO_NO", int, 20)
LOGURU_INFO_COLOR = env("LOGURU_INFO_COLOR", str, "<bold>")
LOGURU_INFO_ICON = env("LOGURU_INFO_ICON", str, "ℹ️") # Information
LOGURU_SUCCESS_NO = env("LOGURU_SUCCESS_NO", int, 25)
LOGURU_SUCCESS_COLOR = env("LOGURU_SUCCESS_COLOR", str, "<green><bold>")
LOGURU_SUCCESS_ICON = env("LOGURU_SUCCESS_ICON", str, "✔️") # Heavy Check Mark
LOGURU_WARNING_NO = env("LOGURU_WARNING_NO", int, 30)
LOGURU_WARNING_COLOR = env("LOGURU_WARNING_COLOR", str, "<yellow><bold>")
LOGURU_WARNING_ICON = env("LOGURU_WARNING_ICON", str, "⚠️") # Warning
LOGURU_ERROR_NO = env("LOGURU_ERROR_NO", int, 40)
LOGURU_ERROR_COLOR = env("LOGURU_ERROR_COLOR", str, "<red><bold>")
LOGURU_ERROR_ICON = env("LOGURU_ERROR_ICON", str, "❌") # Cross Mark
LOGURU_CRITICAL_NO = env("LOGURU_CRITICAL_NO", int, 50)
LOGURU_CRITICAL_COLOR = env("LOGURU_CRITICAL_COLOR", str, "<RED><bold>")
LOGURU_CRITICAL_ICON = env("LOGURU_CRITICAL_ICON", str, "☠️") # Skull and Crossbones分别对日志级别进行说明 :
-
日志共包括7个级别,分别是 :TRACE(5) < DEBUG(10) < INFO(20) < SUCCESS(25) < WARNING(30) < ERROR(40) < CRITICAL(50) .每个日志都用一个默认数字代替,说明它们的基本的高低 。
-
每个级别代表一个数字 ,数字越小级别越小 ;同时数字越小 ,输出的日志越多 。输出的日志越多,代码运行速度越慢,故并非是越详细越好 。因为它们是包含的关系 ,若日志级别设置为>=5将会输出所有日志 。
-
分别对以下几个日志的用途说明 :
-
TRACE : 程序每运行一步,都要记录一条日志 ,几乎不会用到。
-
DEBUG :主要用来调式bug使用,既然是调试bug,就必须记录的详细,一般可以理解每一步中的若个小步记录的日志
-
INFO : 可以理解为记录运行的流程步骤 。
-
SUCCESS : 可以理解为某个流程完成以后记录的成功日志 。
-
WARNING :记录潜在的错误 ,可以理解为标准之外的情况
-
ERROR :记录运行过程中出现的错误 。
-
CRITICAL :非常严重的错误事件, 相对来说用的较少。
-
2.2 日志内容参数化
# 3. 进行字符串参数化
logger.info("{}班有{}位同学".format('一',52)) # 使用format进行格式化
logger.info("{}班有{}位同学",'一',52) # 使用日志中的参数化# 以上两种写法都输出
2023-07-09 17:28:55.263 | INFO | __main__:<module>:39 - 一班有52位同学可以看到,在日志内容中进行数据参数化,可以使用日志本身带的功能,只需要将数据作为参数传入即可。
2.3 输出到文件
输出到文件,主要使用到的方法就是add ,它有好几个参数 ,可以支持日志文件切割、备份、清理等操作 。
# add 方法说明 :
"""
add(filename,level,format,serialize,rotation,retention,compression):filename : 输出的日志文件名level : 日志级别 ,传递7个日志级别中的1个format : 支持传递的格式化参数有:time level file module line message name funcation processretention : 定期清理rotation : 保留时长 comproession : 压缩 ,格式支持:"gz", "bz2", "xz", "lzma", "tar", "tar.gz", "tar.bz2", "tar.xz", "zip"
"""参数演示 :
flname = 'a.log' # 将日志输出到a.log中
logger.add(flname,level='DEBUG',format="{time:YYYY-MM-DD HH:mm:ss} | {level} | {file} | {module}|{line}|{process}|{message}",rotation='10Kb',compression='zip') # 设置日志级别、日志压缩、压缩格式。logger.debug("这是一条debug日志")
logger.info("这是一条info日志")
logger.success("这是一条success日志")
logger.warning("这是一条warning日志")
logger.error("这是一条error日志")
其它参数
logger.add("file_1.log", rotation="500 MB") # 文件过大就会重新生成一个文件
logger.add("file_2.log", rotation="12:00") # 每天12点创建新文件
logger.add("file_3.log", rotation="1 week") # 文件时间过长就会创建新文件
logger.add("file_X.log", retention="10 days") # 一段时间后会清空
logger.add("file_Y.log", compression="zip") # 保存zip格式3.如何记录日志
学习日志模块其实并不能 ,难的是如何让记录的日志发挥它的价值 。个人认为,要写记录日志,就要从三个方面入手,分别是如何记 ? 如何更好的阅读 ,如何做好日志留存 。
3.1 记录日志
做好日志记录是为了更方便、更高效的查看 ,所以第一步完全是为了第二步服务的 。该如何记录日志呢 ?这个应该跟你的业务系统有很大关系 。比如,我的日志记录就是为了自动化框架所使用 。为了在自动化运行报错后能很快速的定位到问题。所以,我设计的日志完全是为了适应这套框架 。
为了能使日志更易读 ,主要从以下的三个方面入手设计 ,分别是 :
-
用例与用例之间的分界线,在用例之间输出分割线,能快速识别到每条用例的中间日志 。同时在开始处输出要运行用例的文件名和用例名,在结束处输出运行结果 。
-
给系统中的日志级别设定一套规则 ,什么日志输出debug 、什么日志输出info ,必须给出明确定义 ,提高辨识度 。
-
日志内容具有上下文识别, 同时相同类型的内容一定要使用相同关键字 。
个人设计了一套规则 ,用于框架的日志记录 。比如 :在自动化用例运行过程中,主要包括流程、子流程和流程上的节点 。那么,日志也是针对这些流程来设计不同日志级别 。
比如,以下是针对日志级别设计的一套规则。
| 包括要素 | 说明 | 对应日志级别 |
|---|---|---|
| 流程 | 包括:setUp-执行用例-tearDown | 每成功运行一步都记录一个success级别的日志 |
| 子流程 | 主要是每个流程中包含的子步骤,比如测试用例包含的步骤有解析请求参数 ,发送请求数据,断言等操作 | 运行的每一步都记录一个info级别的日志。 |
| 流程中的节点 | 主要是针对每一步骤中调用函数内部的日志输出。 | 所调用函数的内部都记录为debug级别的日志 。 |
| 节点报错 | 执行的节点出现报错的情况 | 每一步都有报错的情况都记录为error级别。 |
| 不期望的值 | 在执行的流程中,出现一些不期望的值出现 | 出现不期望的值就可以记录warning级别的日志。 |
3.2 阅读日志
一份可读性强的日志能快速定位错误 ,从而提高解决问题的效率 。那么如何让日志更易阅读呢 ? 个人认为 ,要至少从以下三个方面入手 。
-
要有一套日志记录规则 ,并要有良好的记录日志习惯,严格按照日志规则来记录 ,这条就是第一点说的如何记录日志 ,故这里不再赘述 。
-
日志要按天分割,每天一个 ,按照日期也能快速找到是在那个文件中,每个日志文件中的内容不会太多,方便查找。
-
将最新的日志集成到测试报告中,以便在测试报告中也能打开日志文件,从而查找起来更加方便 。
其中第2点,日志按天分割,就是用到了rotation这个参数 。
logger.add("file_2.log", rotation="8:00") # 每天8点创建新文件其中第3点就是会用到allure中的@allure.attachment() 这个装饰器 ,将日志文件传入到这个装饰器中。
3.3 备份日志
日志备份主要跟记录日志的业务系统有关系 ,比如你是负责公司产品的开发 ,那么日志备份的周期一定要长 ,备份一年也不为过 。
但是 ,如果仅仅是为了自动化测试用例记录日志 ,一年的日志备份就有点太夸张了 。
可以采取的策略为 :
-
一周内的日志保留原样,每天生成一个日志文件 。
-
一周以上到一个月内的日志进行打包压缩 ,保留压缩文件 。
-
一个月的日志文件可以删除 ,因为对于自动化测试框架 ,这些日志文件已经没啥用了,可以删除释放空间。
4.项目集成日志
在项目中想要日志文件,只需要三步, 具体如下 :
-
在创建项目框架时,创建一个日志文件夹 。将日志文件写入该文件夹即可。
-
在入口脚本处,调用日志方法,将日志写入到具体文件中。
-
在项目的代码中,编写要实现日志 。
4.1 创建日志文件夹
4.2 入口中调用日志方法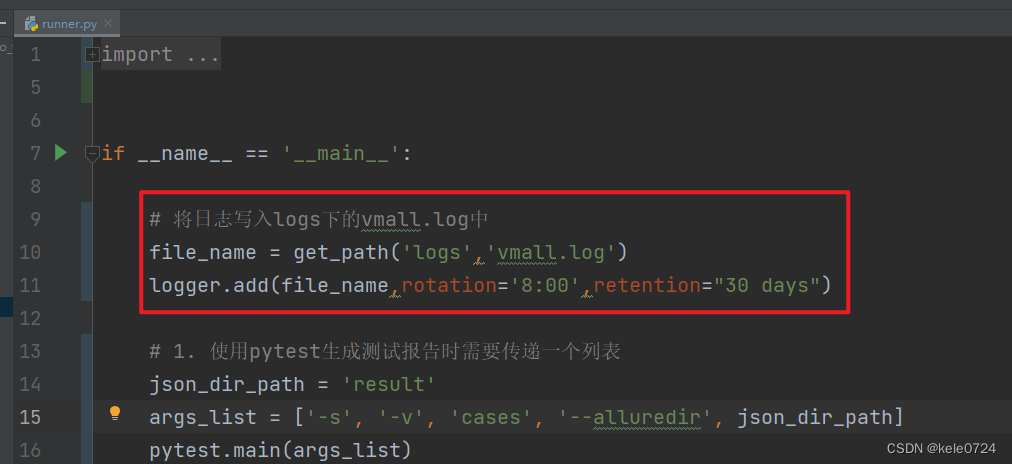
3.在项目中写入日志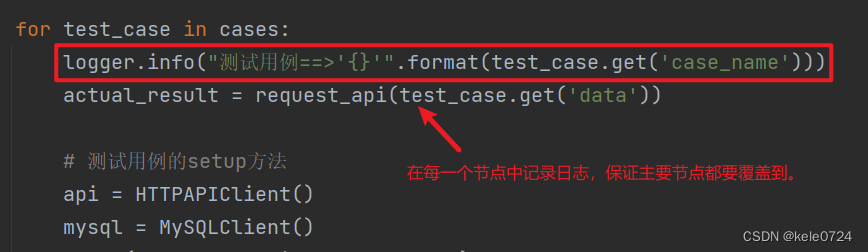
5.项目总结
至此,我们已经实现了五步了 ,分别是 :
第一 、如何编写一个接口自动化框架 ,在第一篇博文中介绍了 。
第二、如何编写测试用例 ,已经在第二篇博文中介绍了 。
第三、如何实现接口请求 ,并和测试用例如何对接 ,已经在第三篇博文中介绍了。
第四、如何使用yaml编写测试数据 ,已经在第四篇博文中介绍了 。
第五,如何使用allure生成测试报告,已经在第五篇博文中介绍了 。
第六 ,如何使用loguru记录日志 ,也就是本篇博文 。
这篇关于自动化测试框架中如何记录日志更加已读 ?一文介绍使用loguru来管理日志的心得。的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





