本文主要是介绍LiveData“数据倒灌“解决方案,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前言
最近在项目中通过LiveData订阅首页数据和加载更多数据,正常情况下没啥问题,结果当我点击了旋转噩梦开始了
样例说明
- 两个接口,一个用于加载首页,一个用于上拉加载,分别通过两个不同的livedata进行订阅,添加数据到同一个RecyclerView中
- 加载一次首页后上拉一次
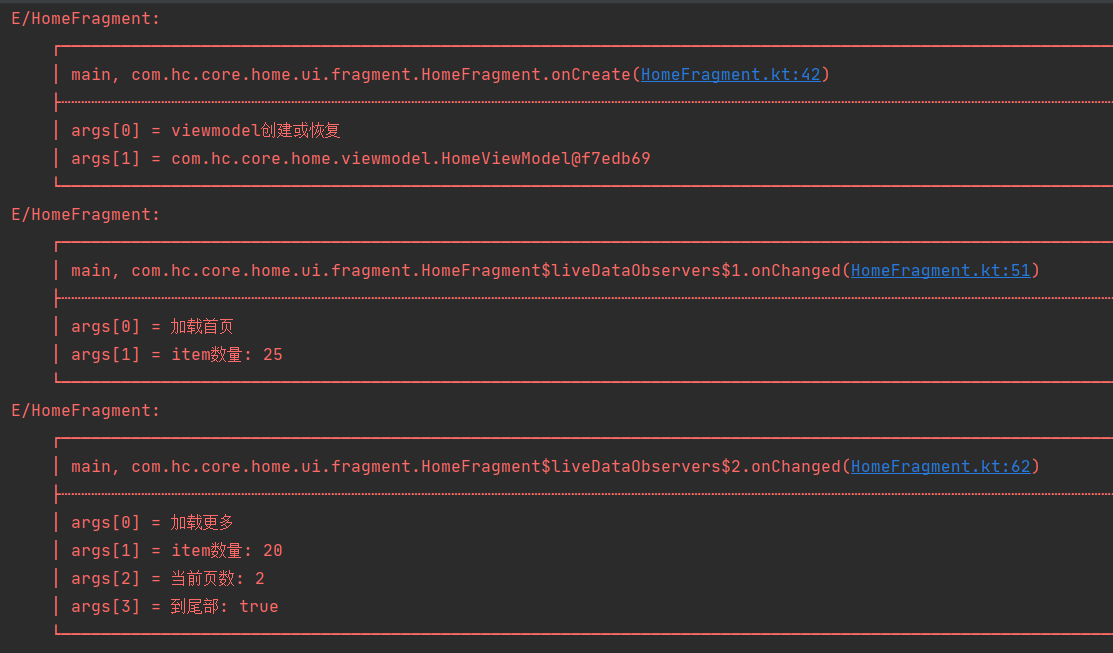
正常情况
旋转后
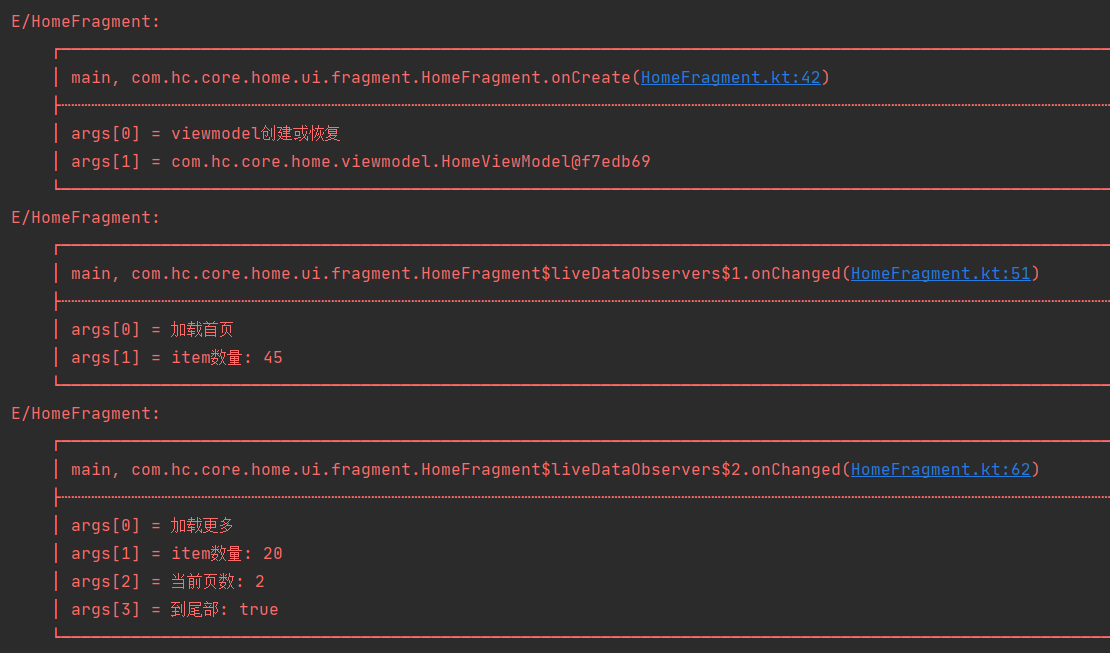
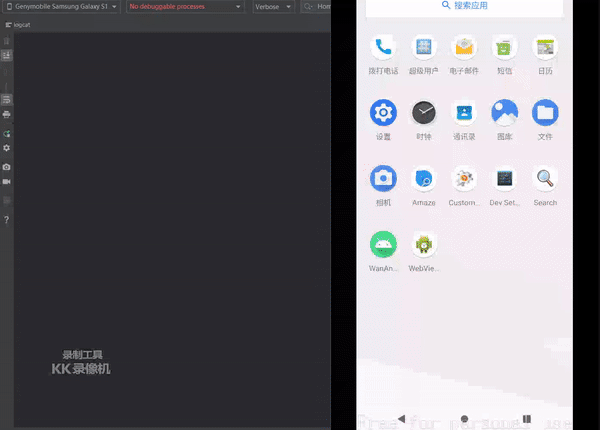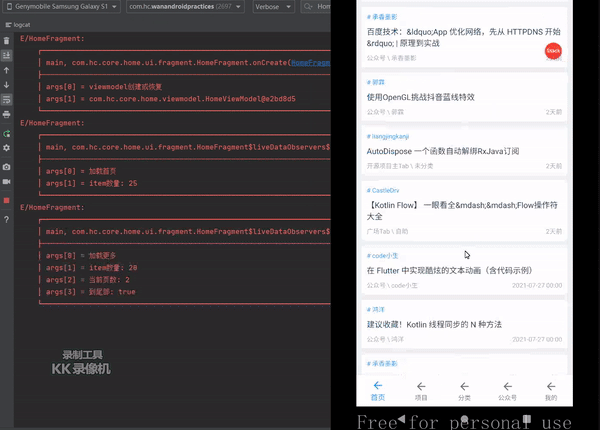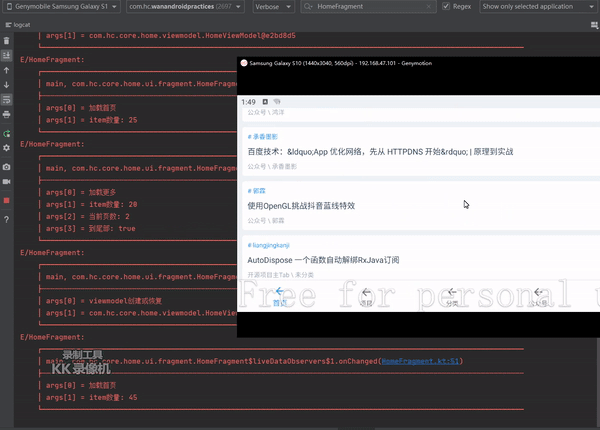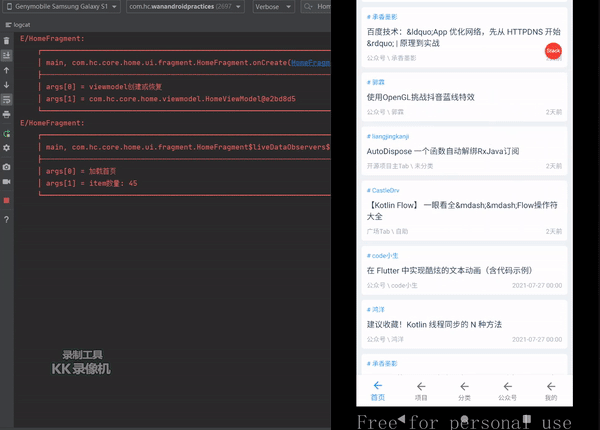
上面日志可以看出,加载首页有25条数据,上拉加载增加了20条,一共45条数据显示正常,但是旋转后发生了出人意料的情况界面出现了65条数据, 除去我们正常显示的45条,追加了重复的最后20条数据,这并不是我想要的结果,那这个是什么导致的呢?
数据倒灌
LiveData天生就是粘性的,当我们重复订阅的时候,会返回最后一次结果,这也是产生上面现象的原因
LiveData粘性特性有利也有弊,还是以上面的例子举例
- 首页恢复
对于需要长期保存的数据,通过viewmodel和LiveData结合使用,我们在特定的场景重建后能快速恢复界面,避免接口的频繁调用
- 分页恢复
对于用完即走的数据,我们应该避免重复订阅,例如上面的分页结果,我们没有必要保存它在内存中,数据已经添加到list中了,没必要多存一份在livedata中,浪费资源
重学安卓:LiveData 数据倒灌 背景缘由全貌 独家解析
解决方案
推荐使用KunMinx大佬的UnPeekLiveData
implementation 'com.kunminx.arch:unpeek-livedata:6.1.0-beta1'特性
- 一条消息能被多个观察者消费(since v1.0)
- 消息被所有观察者消费完毕后才开始阻止倒灌(since v4.0)
- 可以通过 clear 方法手动将消息从内存中移除(since v4.0)
- 让非入侵设计成为可能,遵循开闭原则(since v3.0)
- 基于 "访问权限控制" 支持 "读写分离",遵循唯一可信源的消息分发理念(since v2.0,详见 ProtectedUnPeekLiveData)
- ...
相关代码
private var _homeLiveData = MutableLiveData<DataResult<List<BaseHomeUI>>>()val homeLiveData: LiveData<DataResult<List<BaseHomeUI>>>get() = _homeLiveData//修改前,存在数据倒灌
//val _loadArticleMoreLiveDa = MutableLiveData<PageResult<List<BaseHomeUI>>>()//修改后val _loadArticleMoreLiveDa = UnPeekLiveData<PageResult<List<BaseHomeUhomeViewModel.homeLiveData.observe(viewLifecycleOwner, Observer {when (it) {is DataResult.Success -> {LogUtils.eTag("HomeFragment", "加载首页", "item数量: " + it.data!!.size)homeItemAdapter?.setNewInstance(it.data!! as MutableList<BaseHomeUI>)}else -> {}}})//TODO 存在数据倒灌homeViewModel._loadArticleMoreLiveDa.observe(viewLifecycleOwner, Observer {when (it) {is PageResult.Success -> {LogUtils.eTag("HomeFragment","加载更多","item数量: " + it.data!!.size,"当前页数: " + homeViewModel.currentPage,"到尾部: " + it.hasMore)homeItemAdapter?.addData(it.data!!)if (it.hasMore == true) {homeItemAdapter?.loadMoreModule?.loadMoreComplete()} else if (it.hasMore == false) {homeItemAdapter?.loadMoreModule?.loadMoreEnd()}}else -> {}}// homeViewModel._loadArticleMoreLiveDa.clear()})效果展示
这篇关于LiveData“数据倒灌“解决方案的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






