本文主要是介绍对 Android 的 LiveData 网传的数据倒灌做一个深层次的解释,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
描述问题
你们所说的数据倒灌其实根本不是一个问题或者 bug.
LiveData 设计就是如此. 接受最近一个信号. 对应流的 Behavior 模式.
我们有知名度一点的流的实现有 RxJava 和 Kotlin 的 Flow. 在他们的实现中, 分别对应 BehaviorSubject 和 StateFlow
他们的图示如下, 你们可以看到, 在不同的时间点发生订阅, 你总是能收到最近的一个信号. 除非一开始就没发射过信号. 而 LiveData 正是类似于此种模式. 所以你们说它的数据倒灌, 其实根本不是问题, 人家设计本是如此.
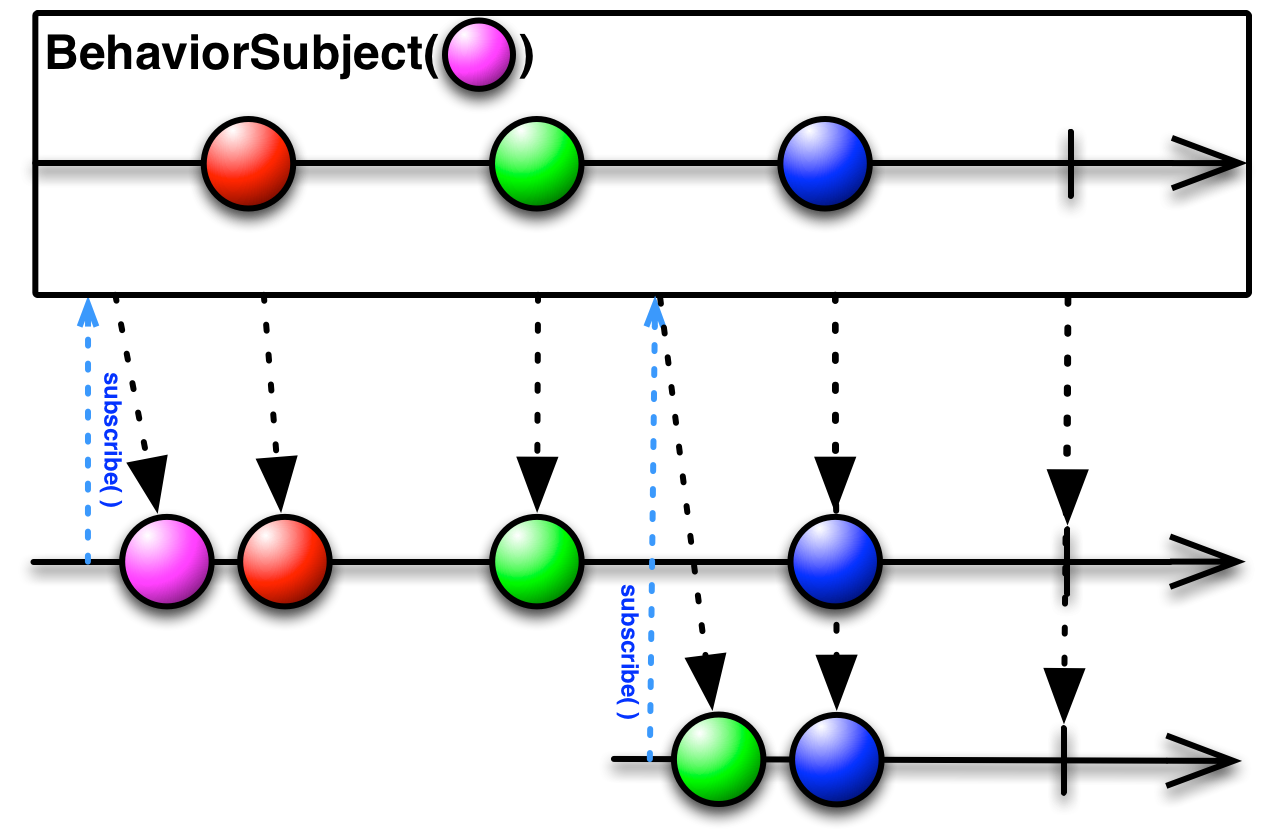
那你们说的数据倒灌根本原因是因为什么呢?
其实是因为你们监听了 Behavior 模式的流或者 LiveData 去做了相应的操作.
比如你监听一个 LiveData 去做了网络请求
当你界面第一次进入, LiveData 中产生了一个信号, 你收到之后做了一次请求, 后来由于系统配置更改引起界面重建, 但是 ViewModel 还是原先那个, 所以在界面重建后你去监听 LiveData, 就会立马收到一个信号, 导致你又做了一次请求.
这里说明的场景, 是由于错误使用了 LiveData 引起的. 如果你要监听一个信号做一定的行为, 这类通常是需要监听 Publish 模式的流. 而 LiveData 设计之初就是 Behavior 模式, Publish 模式的行为示意图如下, 你只能收到你订阅点之后的信号.
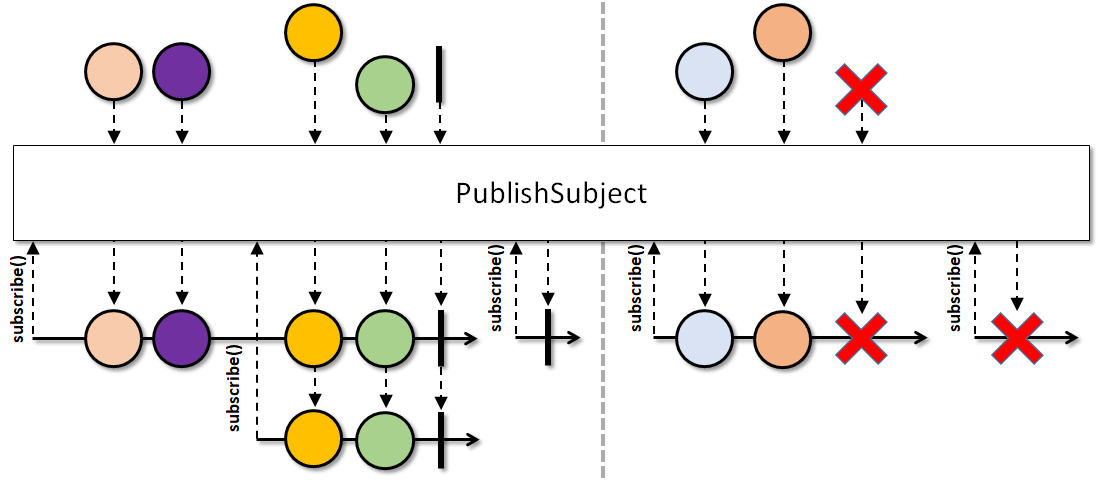
总结
- Behavior 模式可选的方案
- RxJava 的 BehaviorSubject
- Kotlin Flow 的 StateFlow
- LiveData
- Publish 模式可选的方案
- RxJava 的 PublishSubject
- Kotlin Flow 的 SharedFlow
- 我们自定义的 Listener 等
综上所述, 在响应式编程中, 由于你接受的信号源有不同的模式实现. 所以在平常的业务需求中, 我们也要合理的进行选择.
比如我们用于显示界面的场景, Behavior 模式是最适合不过了, 这也是为什么 LiveData 出现的原因. 本就为了显示页面的数据去的. 在界面重建也能重新进行显示.
再比如我们用于执行某些行为的场景, 比如你收到一个信号进行一次网络请求、数据库操作、跳转等等. 这些其实都是需要使用 Publish 模式的.
希望我在这里的长篇大论, 能很好的解释你们出现的所谓的数据倒灌的问题. 在项目中能合理的选择对应的实现去解决问题. 并且对一个响应式的数据源进行监听的时候, 需要先知道它的实现模式是 Behavior 还是 Publish, 以便于你做出判断, 可以用作哪些场景的使用
这篇关于对 Android 的 LiveData 网传的数据倒灌做一个深层次的解释的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






