本文主要是介绍DPDK之fib库源码分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
前言
1. Fib数据结构说明
2. Create功能
2.1 rib表的创建
2.2 fib表的创建
3. Add功能
3.1 Add第1条路由
3.2 Add第2条路由
3.3 Add第3条路由
3.4 Add第4条路由
4. Del功能
5. Free功能
6. Lookup功能
前言
文档分析的是DPDK 20.11版本,暂时只分析fib库ipv4部分的代码逻辑,ipv6部分后续分析;
Fib库主要有create、add、del、free、lookup等功能,下面以这几个功能为入口来分析fib库的主要逻辑;
读者需要对dir_24_8算法、rib表、fib表等有一定的了解,本文只对代码的主要逻辑进行分析,旨在帮助读者在阅读后可以更好的分析理解源码,更详细的代码逻辑请参看源码;
1. Fib数据结构说明
Fib数据结构最大的特点就是trie树和dir_24_8算法(数据结构)的结合,trie树主要是用来管理rib表,dir_24_8数据结构主要是用来管理fib表,rib表可以认为是路由表,主要用来存储路由信息,fib表是转发表,也存储路由信息,但是主要功能是用来做路由查找完成转发信息(下一跳)的获取,其中的dir_24_8数据结构,为空间换时间的数据结构类型,即查找型数据结构,大部分情况只需1次查找,最多只需2次查找,比查找trie树要快,故trie树和dir_24_8的结合非常巧妙;
可能有个疑惑就是为啥不只使用dir_24_8数据结构,因为它也可以存储路由信息,并完成快速查找,其实dpdk有个lpm(最长前缀匹配)库,就是这么做的,可以先看下面的代码分析,看完分析可能就知道一些原因了;
2. Create功能
对应函数:rte_fib_create
2.1 rib表的创建
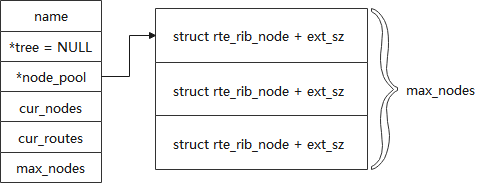
首先是调用rte_rib_create函数创建rib表,其中最主要的数据结构是struct rte_rib和struct rte_rib_node,如下:
struct rte_rib {char name[RTE_RIB_NAMESIZE];struct rte_rib_node *tree;struct rte_mempool *node_pool;uint32_t cur_nodes;uint32_t cur_routes;uint32_t max_nodes;
};先简单介绍一下各个变量的意思:
name:rib表的名字
tree:指向trie树,trie树是由rte_rib_node类型的节点组成的
node_pool:trie树的节点池,即从节点池申请树的节点,节点存储了路由信息
cur_nodes:当前trie树的节点数
cur_routes:当前trie树存储的路由数(节点和路由数并不是一直相等的,具体见下面的分析)
max_nodes:trie树允许挂接的最大节点数(通过指定节点池大小进行数量限制)
struct rte_rib_node {struct rte_rib_node *left;struct rte_rib_node *right;struct rte_rib_node *parent;uint32_t ip;uint8_t depth;uint8_t flag;uint64_t nh;__extension__ uint64_t ext[0];
};
left:该节点的左孩子节点
right:该节点的右孩子节点
parent:该节点的父节点
ip:该节点存储的路由ip
depth:该节点存储的路由ip子网掩码长度(1-32)
flag:该节点是否可用标志(后续会详细说明用途)
nh:该节点存储的路由下一跳
ext:扩展存储,用于存储用户自定义的数据
接下来就是对这些变量进行填充了,比较简单,具体可参看代码,其中创建好rib表后会把该表挂接到rte_rib_tailq链表,这也是dpdk惯用的套路,把创建的各个数据结构都挂接到全局的链表变量上,方便管理,如图、树等;
rte_rib_create函数执行完毕后的数据结构如下:
2.2 fib表的创建
下面开始创建fib表,同样先看一下fib表相关的数据结构:
struct rte_fib {char name[RTE_FIB_NAMESIZE];enum rte_fib_type type; /**< Type of FIB struct */struct rte_rib *rib; /**< RIB helper datastruct */void *dp; /**< pointer to the dataplane struct*/rte_fib_lookup_fn_t lookup; /**< fib lookup function */rte_fib_modify_fn_t modify; /**< modify fib datastruct */uint64_t def_nh;
};name:fib表的名字
type:fib表的类型,共两种,一种是fib表和rib表(trie树结构)共用,一种就是前面说的trie和dir_24_8结合
rib:指向rib表
dp:数据平台,指向fib表的数据结构,根据type有两种数据结构可选
lookup:函数指针,指向路由查找函数
modify:函数指针,指向路由修改(add和del)函数
def_nh:默认下一跳(默认路由)
同样开始对这些变量进行填充,具体可参看代码,这里重点分析一下dp的初始化,即init_dataplane函数,可以看到该函数会判断指定的type类型,如果为RTE_FIB_DUMMY类型,则fib表即是rib表,lookup和modify函数(该函数具体可参看后续的分析)指针均为trie树的操作函数,如果为RTE_FIB_DIR24_8类型,则表示使用dir_24_8数据结构作为fib表的存储结构,该结构的创建在函数dir24_8_create里,同样先看一下该数据结构struct dir24_8_tbl:
struct dir24_8_tbl {uint32_t number_tbl8s; /**< Total number of tbl8s */uint32_t rsvd_tbl8s; /**< Number of reserved tbl8s */uint32_t cur_tbl8s; /**< Current number of tbl8s */enum rte_fib_dir24_8_nh_sz nh_sz; /**< Size of nexthop entry */uint64_t def_nh; /**< Default next hop */uint64_t *tbl8; /**< tbl8 table. */uint64_t *tbl8_idxes; /**< bitmap containing free tbl8 idxes*//* tbl24 table. */__extension__ uint64_t tbl24[0] __rte_cache_aligned;
};
number_tbl8s:tbl8表可申请(创建)的总数
rsvd_tbl8s:预留tbl8表数,它的作用主要是用于判断tbl8表使用数量是否达到上限number_tbl8s的数量
cur_tbl8s:当前在用的tbl8表数量
nh_sz:下一跳变量的内存大小,有1、2、4、8B(1 << nh_sz)可选
def_nh:默认下一跳
tbl8:指向tbl8表
tbl8_idxes:bit位图,用于指示当前tbl8表的使用情况,每个bit位对应一张tbl8表,为1表示在用,为0表示空闲
tbl24:0长度数组,用于指向申请的tbl24表的内存
开始对以上变量进行填充,其中number_tbl8s取BITMAP_SLAB_BIT_SIZE(1<<6==64)的整数倍,因为tbl8_idxes指针指向类型为64位,所以以64为单位,tbl8表和tbl24表的内存结构都是连续地址内存空间,原因当然是dir_24_8算法决定的(以ip值为数组下标),这里注意一下,tbl8和tbl24表其实都是数组,而且数组内容是下一跳,所以每张表需要申请的内存大小是表下一跳数(tbl8:2<<8,tbl24:2<<24)和下一跳大小的乘积,tbl24表只有一张,tbl8表比较特殊,因为是二级表(类似页表),理论上应该有2<<24张表,但是由于大部分路由ip子网长度小于24(这就是dir_24_8算法的来源),并且为了节省内存空间,并没有创建这么多tbl8表,而是作为可配的形式指定;
同样fib表创建完成后也会挂接到全局链表rte_fib_tailq,rte_fib_create函数完成后数据结构(RTE_FIB_DIR24_8类型)如下:

后续分析主要是基于RTE_FIB_DIR24_8类型的fib表,因为RTE_FIB_DUMMY类型的fib表操作逻辑包含在了RTE_FIB_DIR24_8类型里,不再单独分析;
以上是路由表、转发表的创建流程,请注意这些数据结构,下面的分析会时不时用到这些结构,这也是理解表项操作复杂逻辑的基础。
3. Add功能
对应函数:modify函数指针
add功能主要是对路由信息进行添加,在创建fib表的时候对modify函数指针进行了初始化,该指针指向了dir24_8_modify函数,此函数有个op参数,用于指示add还是del操作,此处先分析RTE_FIB_ADD操作;
根据前面分析的数据结构大致可以看出,表的add操作应该是把路由信息(node)挂接到trie树上,并存储到fib表里,本文为了更好的解释add操作,会根据本人当时的分析思路来讲,这也符合读者阅读代码时的习惯,并且先分析add操作的好处是可以从空表开始用实际例子一点点的构建,慢慢的把trie树(rib表)和fib表构建出来,否则只会陷入混乱,无从下手;
说明:为了方便讲述,add路由顺序和下一跳的值对应节点标号,如add第一条路由对应第一个节点,并且下一跳为100;
3.1 Add第1条路由
首先调用rte_rib_lookup_exact在树中对要添加的路由信息进行搜索,看一下是否已经被添加到rib表里了,此时不用知道树的具体组织形式,因为是空表(还记得吧,tree = NULL),所以肯定搜索不到,不过根据此函数和前面的数据结构分析,大致可以看出树的每个节点有左右两个孩子节点和一个父节点,每个节点存储了路由ip、depth、flag等信息,在搜索过程中会对搜索路径上的每个可用节点进行路由信息匹配,以此来判断是否找到了相同的路由信息,搜索路径是怎么算出来的呢,get_nxt_node函数给出了答案:
static inline struct rte_rib_node *
get_nxt_node(struct rte_rib_node *node, uint32_t ip)
{return (ip & (1 << (31 - node->depth))) ? node->right : node->left;
}即根据当前节点的depth长度对应的搜索ip的下一位bit位取值来决定,取值1表示搜索该节点的右子节点,0表示搜索左子节点,节点是否可用是通过flag判断的,关于节点为什么有这个标志见后续分析,路由匹配当然是ip和depth结合判断;好了,先分析到这里,当前可能整个表项的结构还不是很清楚,但是大致可以画出树的蛛丝马迹来:

- 节点B和E有共同的部分A,共同部分是指A的ip(A的ip掩码A的depth),A为B和E的父节点,B和E分别为A的左右孩子节点;
- 节点B和E的ip在A的depth之后的一个bit位肯定不同,且分别为0和1;
- 树的同一分支的层级越深对应的depth越大,如节点D > B > A
- 节点C和D有共同的部分A和B,而且最长的共同部分是它们的父节点B,同样节点B、C、D、E、F有共同的部分A;
如前所述rte_rib_lookup_exact返回NULL,接着往下分析,遇到了:
if (depth > 24) {tmp = rte_rib_get_nxt(rib, ip, 24, NULL,RTE_RIB_GET_NXT_COVER);if ((tmp == NULL) &&(dp->rsvd_tbl8s >= dp->number_tbl8s))return -ENOSPC;}大致可以看出这个是针对tbl8表项的,先略过,弄清楚了tbl24的操作,再回过头来看它应该会容易很多;
接下来就是真正的add操作了,调用rte_rib_insert函数,把路由信息插入到rib表(trie树),同样该函数也会先在rib表中搜索一下有没有相同路由信息的节点,如果有则直接退出,否则申请一个新的节点,把路由信息等填充到该节点,因为此时trie树是空的,所以该节点是树的第一个节点,它的父节点、左右孩子节点应该均为NULL,看一下代码:
new_node->left = NULL;new_node->right = NULL;new_node->parent = NULL;new_node->ip = ip;new_node->depth = depth;new_node->flag = RTE_RIB_VALID_NODE;/* traverse down the tree to find matching node or closest matching */while (1) {/* insert as the last node in the branch */if (*tmp == NULL) {*tmp = new_node;new_node->parent = prev;++rib->cur_routes;return *tmp;}会进入到该分支,prev为NULL,和猜想的一样,此时该节点成为了树的第一个节点,如下:

继续往下看代码:
rte_rib_set_nh(node, next_hop);parent = rte_rib_lookup_parent(node);if (parent != NULL) {rte_rib_get_nh(parent, &par_nh);if (par_nh == next_hop)return 0;}填充节点里的下一跳信息,然后寻找该节点的父节点,如果父节点和要设置的下一跳相同则直接退出,因为目前节点还没有父节点,可以暂时不用考虑这个,至于为什么这么做,接着往下分析代码看看能不能找到原因,此时parent为NULL,接着运行下面的代码:
ret = modify_fib(dp, rib, ip, depth, next_hop);if (ret != 0) {rte_rib_remove(rib, ip, depth);return ret;}看名字应该是修改fib表了,根据前面的猜想应该是把路由信息添加到fib表,进入到该函数看一下:
首先调用rte_rib_get_nxt函数,看名字是获取下一个节点,具体还是进入该函数看一下:
逻辑比较复杂,如果只看代码就会陷入其中,所以还是按照前面说的,用实际的例子一点点的分析,函数会进入下面的分支:
if (last == NULL) {tmp = rib->tree;while ((tmp) && (tmp->depth < depth))tmp = get_nxt_node(tmp, ip);} 因为现在只有一个节点,并且要查找的路由信息就是刚刚挂接到树上的节点,所以tmp指向该节点,然后进入:
while (tmp) {if (is_valid_node(tmp) &&(is_covered(tmp->ip, ip, depth) &&(tmp->depth > depth))) {prev = tmp;if (flag == RTE_RIB_GET_NXT_COVER)return prev;}tmp = (tmp->left) ? tmp->left : tmp->right;}return prev;最终会返回该节点的左孩子节点,当然此时是NULL,这里也可以看出优先返回左孩子节点,为什么呢?这里先记着这个疑问,后面慢慢找答案;
费了半天劲,结果rte_rib_get_nxt返回的是NULL,所以modify_fib函数会进入下面的分支:
else {redge = ip + (uint32_t)(1ULL << (32 - depth));if (ledge == redge)break;ret = install_to_fib(dp, ledge, redge,next_hop);if (ret != 0)return ret;}前面有个ledge,这里有个redge,变量一般都是见名知义(给变量起个好名字的重要性!!!)的,这两个变量应该是左右边界的意思,有了这个概念再来看一下代码,ledge = ip,左边界是ip的值,右边界是ip的值(掩码末位)加1,如果两者一样则break掉,说明边界之间有ip值才可以add到fib表,现在才真正到了插入fib表的函数install_to_fib,进入该函数看一下:
依然无比复杂,乍一看毫无头绪,还是用法宝一点点分析,先捋一下当前的场景,rib表已完成add一条路由信息,trie树有了第一个节点,但fib表还是空的,所以有了前面rib表的分析经验,从空表开始分析应该是最简单的:
len = ((ledge == 0) && (redge == 0)) ? 1 << 24 :((redge & DIR24_8_TBL24_MASK) - ROUNDUP(ledge, 24)) >> 8;对于左右边界都为0的情况比较特殊先不考虑,而且先分析tbl24表,所以此时可以找个depth在1-24之间的例子,比如路由ip:192.168.0.0/16,下一跳:100,这里先说一下宏ROUNDUP的意思,主要是向上圆整ledge为256的整数倍,换个说法就是如果ip的最后8bit位不为0则向上(第24bit位)进一位,大致可以看出是tbl8要用到的,这里先忽略,目前ledge=192.168.0.0,redge=192.169.0.0,len就可以计算出来了:0.0.1.0,转换成整数就是256,可以看出这256个ip值是192.168.0.0-192.168.255.0,接着分析来验证一下:
根据当前的例子,会执行:
write_to_fib(get_tbl24_p(dp, ROUNDUP(ledge, 24), dp->nh_sz),next_hop << 1, dp->nh_sz, len);先看get_tbl24_p函数,看名字是获取tbl24表的地址:
static inline void *
get_tbl24_p(struct dir24_8_tbl *dp, uint32_t ip, uint8_t nh_sz)
{return (void *)&((uint8_t *)dp->tbl24)[(ip &DIR24_8_TBL24_MASK) >> (8 - nh_sz)];
}首先说明一下,为了方便理解,做一下变换(注:为了保证变换后值是相等的,右移的位没有消失,要做保留,左移时还会恢复,后面做类似的变换时都遵守这个原则):x >> (8 - nh_sz)相当于(x >> 8) << nh_sz,相当于(x >> 8) * (1 << nh_sz)

结合前面分析的tbl24的数据结构可知,ip作为数组下标,表示数组中第uint32_t(ip)(ip转换成整数)个下一跳的位置(如上图),注意是取ip的前24bit位,所以掩码后右移了8,为了方便这里把数组指针变量dp->tbl24强制转换成了uint8_t类型,但是需要考虑到下一跳的大小,所以再乘以下一跳的大小,这样就定位到了对应的下一跳在数组里的位置,取到了下一跳的值,然后取地址&,还有个地方需要注意,给get_tbl24_p函数传参ROUNDUP(ledge, 24),而不是ledge,可以假设ledge的depth不大于24的情况,则ROUNDUP(ledge, 24)和ledge相等,假设ledge的depth大于24并且最后8bit位不为0,则ROUNDUP(ledge, 24) > ledge,针对后面这种情况,可以回过头看看len的计算公式和进入改分支的条件:(ledge >> 8) != (redge >> 8),说明redge=ledge+1往24bit进了1位,所以redge & DIR24_8_TBL24_MASK和ROUNDUP(ledge, 24)是相等的,此时len为0,write_to_fib函数就不会往tbl24表插入路由了(避免了tbl8的路由插入tbl24表),所以这里传参ROUNDUP(ledge, 24)和ledge是一样的(但是为啥不直接写ledge?暂时没想明白);
获取到tbl24的写入起始地址、写入内容(下一跳)和个数(len),就可以开始往表里add路由信息了,write_to_fib函数比较简单,大致是从ledge(192.168.0.0)对应的地址开始写入256个下一跳,所以最终写入了路由信息范围为192.168.0.0-192.168.255.0(fib表的下标对应路由ip地址,fib表的内容为下一跳,那么depth在哪?答案就是dir_24_8的算法的特点:扩展depth到24,具体不再描述);
有个地方也需要注意一下,下一跳在插入fib表时左移了一位,说明fib表里的下一跳的第一个bit位不是下一跳的值,应该有其他用途,后面看看能不能得到答案,而且在dir24_8_modify函数里有个语句:
if (next_hop > get_max_nh(dp->nh_sz))return -EINVAL;
static inline uint64_t
get_max_nh(uint8_t nh_sz)
{return ((1ULL << (bits_in_nh(nh_sz) - 1)) - 1);
}也说明下一跳的值的范围少一个bit位;
终于第一条路由成功的add到了rib和fib表里,现在两个表格情况如下:

3.2 Add第2条路由
接下来插入第二条路由:192.168.2.0/24 200
基于前面的代码分析,后面主要分析一下前面例子没有涉及的地方,同样先进入dir24_8_modify函数,其中在rte_rib_insert函数里开始进入不一样的逻辑,此时会进入如下代码逻辑:
/** Intermediate node found.* Previous rte_rib_lookup_exact() returned NULL* but node with proper search criteria is found.* Validate intermediate node and return.*/if ((ip == (*tmp)->ip) && (depth == (*tmp)->depth)) {node_free(rib, new_node);(*tmp)->flag |= RTE_RIB_VALID_NODE;++rib->cur_routes;return *tmp;}d = (*tmp)->depth;if ((d >= depth) || !is_covered(ip, (*tmp)->ip, d))break;prev = *tmp;tmp = (ip & (1 << (31 - d))) ? &(*tmp)->right : &(*tmp)->left;如果找到了与目标路由信息一样的不可用节点,则把该节点的标志置为可用即可,无需再执行插入节点的操作,从这里可以看出节点不可用时也可以存在于树中,只是把标志位置为不可用即可,路由信息保留,这样做的好处是提高了效率;
注意tmp是个二级指针,此处主要用来操作节点的左右孩子指针的,最后一行其实是get_nxt_node函数,前面已经分析过,就是继续寻找下一个节点,最终会发现找不到满足条件的节点,进入:
/* traverse down the tree to find matching node or closest matching */while (1) {/* insert as the last node in the branch */if (*tmp == NULL) {*tmp = new_node;new_node->parent = prev;++rib->cur_routes;return *tmp;}这个就是第一个节点的逻辑了,不再分析,接下来就进入下面的逻辑,这个也是前面留下的疑问:
rte_rib_set_nh(node, next_hop);parent = rte_rib_lookup_parent(node);if (parent != NULL) {rte_rib_get_nh(parent, &par_nh);if (par_nh == next_hop)return 0;}此时应该可以得到答案了,先看看最终的结果,如下:

如果第二个的节点的下一跳和父节点一致,即也是100的话,就直接退出,不再填充fib表,因为本来192.168.2.0的下一跳就是100,所以此处是属于代码优化,提高性能(同时也可以回答前面提到的“为啥不只用dir_24_8数据结构”的疑问了,结合trie树的好处还有很多,后面分析慢慢体会吧),这里也可以看出子节点在fib表里是父节点的子集;
3.3 Add第3条路由
然后插入第三条路由:192.168.0.0/17 300
依然是在rte_rib_insert函数里开始进入不一样的逻辑,在if ((d >= depth):
/** Intermediate node found.* Previous rte_rib_lookup_exact() returned NULL* but node with proper search criteria is found.* Validate intermediate node and return.*/if ((ip == (*tmp)->ip) && (depth == (*tmp)->depth)) {node_free(rib, new_node);(*tmp)->flag |= RTE_RIB_VALID_NODE;++rib->cur_routes;return *tmp;}d = (*tmp)->depth;if ((d >= depth) || !is_covered(ip, (*tmp)->ip, d))break;prev = *tmp;tmp = (ip & (1 << (31 - d))) ? &(*tmp)->right : &(*tmp)->left;当寻找到第2个节点时会发现节点的depth(24)比目标depth(17)要大,break,进入下面的流程:
/* closest node found, new_node should be inserted in the middle */common_depth = RTE_MIN(depth, (*tmp)->depth);common_prefix = ip ^ (*tmp)->ip;d = __builtin_clz(common_prefix);common_depth = RTE_MIN(d, common_depth);common_prefix = ip & rte_rib_depth_to_mask(common_depth);if ((common_prefix == ip) && (common_depth == depth)) {/* insert as a parent */if ((*tmp)->ip & (1 << (31 - depth)))new_node->right = *tmp;elsenew_node->left = *tmp;new_node->parent = (*tmp)->parent;(*tmp)->parent = new_node;*tmp = new_node;} else {前面几行主要功能是找当前节点(第二个节点)和目标路由信息之间最长的共同部分,前面分析过共同部分的含义,这里还有个共同depth(两者ip共同部分的长度)的概念,根据当前的例子,common_depth = 17,common_prefix = 192.168.0.0,并且满足if的条件,再次联想一下前面对树的分析,当前节点和目标路由有共同部分,而且共同部分就是目标路由,所以目标路由就是当前节点的父节点,正如代码里的注释所说:/* insert as a parent */,如下:

接下来插入fib表时也会在modify_fib函数里的rte_rib_get_nxt函数里出现新的逻辑,如下:
while (tmp) {if (is_valid_node(tmp) &&(is_covered(tmp->ip, ip, depth) &&(tmp->depth > depth))) {prev = tmp;if (flag == RTE_RIB_GET_NXT_COVER)return prev;}tmp = (tmp->left) ? tmp->left : tmp->right;}tmp为第2个节点时满足if条件,返回第2个节点(return prev;),进入:
if (tmp != NULL) {rte_rib_get_depth(tmp, &tmp_depth);if (tmp_depth == depth)continue;rte_rib_get_ip(tmp, &tmp_ip);redge = tmp_ip & rte_rib_depth_to_mask(tmp_depth);if (ledge == redge) {ledge = redge +(uint32_t)(1ULL << (32 - tmp_depth));continue;}ret = install_to_fib(dp, ledge, redge,next_hop);if (ret != 0)return ret;ledge = redge +(uint32_t)(1ULL << (32 - tmp_depth));} else {可以看到以第2个节点的ip作为右边界,原来rte_rib_get_nxt是为了找右边界,所以优先返回左孩子节点的原因就是左孩子是离自己最近的节点(第3个节点的左孩子为第2个节点),可以作为第一个右边界;
后续插入fib表的逻辑就和之前的一样的,结果如下:

当然,还没完,看下面:
ledge = redge +(uint32_t)(1ULL << (32 - tmp_depth));在这次插入fib表完成后,ledge重新赋值了,为redge+1,然后执行do while循环再次进入rte_rib_get_nxt函数寻找新的右边界,这次rte_rib_get_nxt函数也有了新的逻辑了,如下:
} else {tmp = last;while ((tmp->parent != NULL) && (is_right_node(tmp) ||(tmp->parent->right == NULL))) {tmp = tmp->parent;if (is_valid_node(tmp) &&(is_covered(tmp->ip, ip, depth) &&(tmp->depth > depth)))return tmp;}tmp = (tmp->parent) ? tmp->parent->right : NULL;}此时tmp为第2个节点,然后按照此段代码逻辑分析,最终tmp会成为NULL,后续就一样了,先把最终结果展示出来再来看看这段代码的真实用意:

可以看到第3个节点在fib表里的位置,首先是其父节点(第1个节点)的子集,还要避开其左右两个子节点(左子节点为第2个节点,右子节点为NULL,读者可以接着加入子右节点看一下),那么子节点的子节点需要避开吗?这个已经避开了,因为子节点的子节点是子节点的子集,避开了子节点就避开了它们,所以这段代码就是找节点的右节点以避开;
到目前为止,基本分析了rib、fib表的大致插入流程,但是还缺少一些情况,如tbl8表的插入、节点flag怎么变为不可用的、右节点的插入等,为了覆盖到这些情况,接着用实际例子来进行分析;
3.4 Add第4条路由
接下来插入第四条路由:192.168.0.8/29 400
这个depth超过了24,所以会插入tbl8表;
依然分析和前面不一样的地方,如下:
if (depth > 24) {tmp = rte_rib_get_nxt(rib, ip, 24, NULL,RTE_RIB_GET_NXT_COVER);if ((tmp == NULL) &&(dp->rsvd_tbl8s >= dp->number_tbl8s))return -ENOSPC;}再看一下rte_rib_get_nxt函数里的语句:
if (is_valid_node(tmp) &&(is_covered(tmp->ip, ip, depth) &&(tmp->depth > depth)))rte_rib_get_nxt函数前面已经分析过,在前面的用途主要是用来获取fib表的右边界的,现在再来看一下这个函数,会发现在返回非空时都是返回的目标路由的子集或者子节点,这里传入的depth是24,如果返回非空,则返回的节点满足depth > 24,并且返回节点的ip和目标ip至少前24bit位相同,这说明什么呢?想一下前面分析的tbl24表,ip的前24bit位一样,则他们在tbl24表里的位置是一样的,如果了解了dir_24_8数据结构或者lpm库,则会知道tbl24表存储的路由ip如果超过了24bit,则tbl24表里存储的就不是下一跳,而是tbl8表的下标,也就是说目标ip和返回的节点ip是在同一个tbl8表里的,再回过头来看看这段代码的意思,如果返回NULL,需要判断rsvd_tbl8s和number_tbl8s的大小关系,返回NULL代表着目标ip还没有在当前的tbl24表里找到对应的tbl8表,如果把该目标ip插入fib表的话需要申请一个新的tbl8表,再看一下后面的一段代码:
if ((depth > 24) && (tmp == NULL))dp->rsvd_tbl8s++;需要新建tbl8表的话rsvd_tbl8s就增加1,可以看出来rsvd_tbl8s变量记录了当前fib表里的tbl8的数量,所以如果rsvd_tbl8s>=number_tbl8s时说明tbl8表用完了,不能再新建了,此时需要丢弃该目标路由,返回ENOSPC错误;
然后进入rte_rib_insert函数,出现新的逻辑:
} else {/* create intermediate node */common_node = node_alloc(rib);if (common_node == NULL) {node_free(rib, new_node);rte_errno = ENOMEM;return NULL;}common_node->ip = common_prefix;common_node->depth = common_depth;common_node->flag = 0;common_node->parent = (*tmp)->parent;new_node->parent = common_node;(*tmp)->parent = common_node;if ((new_node->ip & (1 << (31 - common_depth))) == 0) {common_node->left = new_node;common_node->right = *tmp;} else {common_node->left = *tmp;common_node->right = new_node;}*tmp = common_node;}当前tmp为第2个节点(192.168.2.0/24 200),目标路由:192.168.0.8/29 400,他们两个的共同部分为192.168.0.0/22,即common_node->ip = 192.168.0.0,common_node->depth = 22,以此为一个新的路由信息并申请节点common_node,目标路由节点和第2个节点分别为它的左右孩子节点,而原来的第2个节点的父节点成为了common_node的父节点,相当于common_node节点插在了中间:/* create intermediate node */,结果如下:

注意common_node节点的flag标志位,设置为了不可用,因为它是凭空产生的一个路由信息,所以为不可用很合理,这就是不可用的来源,那么怎么能变成可用的呢,当然是add一条一模一样的路由信息了,对应的逻辑如下:
/** Intermediate node found.* Previous rte_rib_lookup_exact() returned NULL* but node with proper search criteria is found.* Validate intermediate node and return.*/if ((ip == (*tmp)->ip) && (depth == (*tmp)->depth)) {node_free(rib, new_node);(*tmp)->flag |= RTE_RIB_VALID_NODE;++rib->cur_routes;return *tmp;}接下来会在install_to_fib函数里出现新的逻辑:
else if ((redge - ledge) != 0) {tbl24_tmp = get_tbl24(dp, ledge, dp->nh_sz);if ((tbl24_tmp & DIR24_8_EXT_ENT) !=DIR24_8_EXT_ENT) {tbl8_idx = tbl8_alloc(dp, tbl24_tmp);if (tbl8_idx < 0)return -ENOSPC;/*update dir24 entry with tbl8 index*/write_to_fib(get_tbl24_p(dp, ledge, dp->nh_sz),(tbl8_idx << 1)|DIR24_8_EXT_ENT,dp->nh_sz, 1);} elsetbl8_idx = tbl24_tmp >> 1;tbl8_ptr = (uint8_t *)dp->tbl8 +(((tbl8_idx * DIR24_8_TBL8_GRP_NUM_ENT) +(ledge & ~DIR24_8_TBL24_MASK)) <<dp->nh_sz);/*update tbl8 with new next hop*/write_to_fib((void *)tbl8_ptr, (next_hop << 1)|DIR24_8_EXT_ENT,dp->nh_sz, redge - ledge);tbl8_recycle(dp, ledge, tbl8_idx);}首先是get_tbl24,和get_tbl24_p差了一个p(呵呵哒),应该也是获取tbl24表的什么东西,进入该函数一探究竟吧:
static inline uint64_t
get_tbl24(struct dir24_8_tbl *dp, uint32_t ip, uint8_t nh_sz)
{return ((dp->tbl24[get_tbl_idx(get_tbl24_idx(ip), nh_sz)] >>(get_psd_idx(get_tbl24_idx(ip), nh_sz) *bits_in_nh(nh_sz))) & lookup_msk(nh_sz));
}把tbl24表也放到这里,方便分析:

可以看到是取tbl24的内容,就是下一跳的值;
函数里的语句各种嵌套,一层层给它剥开:
dp->tbl24[get_tbl_idx(get_tbl24_idx(ip), nh_sz)]这个语句是取tbl24存储的内容,即下一跳的值,从里往外分析:
get_tbl24_idx:取ip前24bit位转换成整数
get_tbl_idx:val >> (3 - nh_sz) => (val >> 3) << nh_sz => (val / 8) * (1 << nh_sz) => val * (1 << nh_sz) / 8
为什么这么做?前面插入tbl24数组时已经分析过,要定位ip对应的下一跳在数组中的位置,需要考虑到数组指针dp->tbl24的类型和下一跳的大小,这里没有对数组指针做类型的强制转换,所以还是uint64_t,指针每次加1代表移动了8Byte,首先ip值乘以下一跳大小,代表对应的下一跳前面有多少个字节,然后除以8,代表对应的数组下标是多少,因为下一跳的大小可能小于8,所以此处只是定位到了下一跳所在的uint64_t变量的值,如下图:
 接下来需要定位下一跳在该变量里的具体位置,然后取值,于是出现了下面的语句:
接下来需要定位下一跳在该变量里的具体位置,然后取值,于是出现了下面的语句:

如果直接分析代码会很困难,几乎会绝望,换个角度分析,首先可以看到是变量的值右移,说明后面的语句计算的是对应下一跳的最后一个bit位后面的bit位数,这样右移这些bit位才能使对应的下一跳的最后一个bit位移动到最右边,就可以直接取值了,但是左边的其他下一跳bit位怎么办,当然是用下一跳的位数掩码掩掉了,所以有了:

有了这个预分析再来看这两部分代码应该就简单点了:
get_psd_idx:以8除以下一跳大小的值减去1为掩码,掩上ip的值,比较绕,其实就是8个Byte的变量里有几个下一跳,就获取ip对应的bit位数,举个例子比较容易理解,比如下一跳大小为2Byte,则变量里有4个下一跳,则取ip的最后两个bit位,因为两个bit位可以表示4个位置,这么说只是让你知道这么做的用途,如果想知道为什么这么做,那就回过头再看看前面第一次定位时的算法:(val >> 3) << nh_sz,ip右移3bit,于是ip的右边3个bit位余下来了,没有参与定位,然后再左移nh_sz,这样右边3个bit位有nh_sz位参与定位了,剩下(3 - nh_sz)个bit位就只能在第二次定位时参与了,所以get_psd_idx就是执行一个反向操作,找出来第一次没有参与定位的bit位进行第二次定位,是不是明白了呢?
知道了在变量里的位置,然后就需要知道每个下一跳的bit位数了,bits_in_nh函数就很容易看懂了,两者相乘就是对应下一跳的最后一个bit位后面的bit位数了,这里有个地方需要注意一下,因为在插入时是按照uint8_t类型的数组算位置的,即下标越大地址越高,对应在uint64_t类型的变量里,地址越高(下标越大)在变量里越靠左,所以两者相乘在变量里就是右边的bit位数;
接下来看看lookup_msk函数:
static inline uint64_t
lookup_msk(uint8_t nh_sz)
{return ((1ULL << ((1 << (nh_sz + 3)) - 1)) << 1) - 1;
}1 << (nh_sz + 3):和bits_in_nh(nh_sz)函数是一样的功能,计算下一跳所占的位数,只是写法不同而已,可以参考前面的公式变换方法;
剩下的就很容易了,最后得到的结果就是下一跳所占的位数对应的掩码
吐槽:很多地方代码有同样的功能却有不同的写法,而且获取fib表里下一跳的代码有点炫技的嫌疑,完全可以对tbl24指针做强制类型转换为下一跳一样的类型,这样就简单多了。。。
get_tbl24函数搞这么复杂只是为了获取下一跳而已,函数返回后,接下来会做个判断:
if ((tbl24_tmp & DIR24_8_EXT_ENT) !=DIR24_8_EXT_ENT) {前面已经分析过,下一跳的最后一位有其他用途,这里就可以得到答案了,此bit位用于指示有没有对应的tbl8表,前面说过,如果有对应的tbl8表,则tbl24表里存储的就不是真正的下一跳了,而是tbl8表的地址(下标),所以如果还没有对应的tbl8表,需要申请tbl8表,并把tbl24的下一跳值改为tbl8的地址,如下:
if ((tbl24_tmp & DIR24_8_EXT_ENT) !=DIR24_8_EXT_ENT) {tbl8_idx = tbl8_alloc(dp, tbl24_tmp);if (tbl8_idx < 0)return -ENOSPC;/*update dir24 entry with tbl8 index*/write_to_fib(get_tbl24_p(dp, ledge, dp->nh_sz),(tbl8_idx << 1)|DIR24_8_EXT_ENT,dp->nh_sz, 1);} else这里需要分析一下tbl8_alloc函数,首先是获取一个空闲的tbl8表:
static int
tbl8_get_idx(struct dir24_8_tbl *dp)
{uint32_t i;int bit_idx;for (i = 0; (i < (dp->number_tbl8s >> BITMAP_SLAB_BIT_SIZE_LOG2)) &&(dp->tbl8_idxes[i] == UINT64_MAX); i++);if (i < (dp->number_tbl8s >> BITMAP_SLAB_BIT_SIZE_LOG2)) {bit_idx = __builtin_ctzll(~dp->tbl8_idxes[i]);dp->tbl8_idxes[i] |= (1ULL << bit_idx);return (i << BITMAP_SLAB_BIT_SIZE_LOG2) + bit_idx;}return -ENOSPC;
}tbl8_idxes数组记录了tbl8表的使用情况,所以通过for循环遍历tbl8_idxes数组来获取空闲的tbl8表,里面的条件分析:
dp->number_tbl8s >> BITMAP_SLAB_BIT_SIZE_LOG2:相当于dp->number_tbl8s/64,因为tbl8_idxes是uint64_t类型的,每个数组的值有64bit位,对应了64个tbl8表,所以tbl8表的总数除以64表示tbl8_idxes数组的元素个数,当然i要小于它了;
dp->tbl8_idxes[i] == UINT64_MAX:表示数组元素的64个bit位全1,对应的tbl8被占用,所以这种情况不可能找到空闲的tbl8表,当然要避开,其实这个条件是为了提高效率,每次判断64bit位(一个数组元素),如果不是UINT64_MAX,则里面肯定有空闲的tbl8表,而不是每个bit位循环一次,这样效率低而且不方便操作,这个其实也可以看成是达夫设备的算法;
在找到有空闲的tbl8表的数组元素后,进一步定位具体是哪个bit位,这个和前面定位tbl24有点类似:
__builtin_ctzll:返回变量对应的bit位从右边数有几个0bit位
~dp->tbl8_idxes[i]:取反,说明从变量右边bit位开始记录
dp->tbl8_idxes[i] |= (1ULL << bit_idx):从右边数直到找到不是1的bit位,此位对应的tbl8表是空闲的,现在要变为占用状态了
return (i << BITMAP_SLAB_BIT_SIZE_LOG2) + bit_idx:表示当前找到的空闲bit位前面有多少个bit位,也就是说当前空闲tbl8表前面有多少个tbl8表,因为tbl8表是存放在一块连续地址空间的,所以此处获取这个值就是位了定位到tbl8表的位置,然后结合这个值计算出tbl8表的地址:
tbl8_ptr = (uint8_t *)dp->tbl8 +((tbl8_idx * DIR24_8_TBL8_GRP_NUM_ENT) <<dp->nh_sz);主要是计算目标tbl8表前面的地址空间大小,因为是连续的,所以整个内存块的起始地址加上这些地址空间大小就得到了目标tbl8表的地址;
然后用tbl24表里的下一跳初始化tbl8表的下一跳:
/*Init tbl8 entries with nexthop from tbl24*/write_to_fib((void *)tbl8_ptr, nh|DIR24_8_EXT_ENT, dp->nh_sz,DIR24_8_TBL8_GRP_NUM_ENT);tbl8_alloc申请tbl8表完毕,并返回btl8表的位置,此时要把tbl8表的位置插入对应的tbl24表里(正如前述那样,tbl24在有对应tbl8表时,存放的就是tbl8表的位置了):
/*update dir24 entry with tbl8 index*/write_to_fib(get_tbl24_p(dp, ledge, dp->nh_sz),(tbl8_idx << 1)|DIR24_8_EXT_ENT,dp->nh_sz, 1);如果tbl24表已经有对应的tbl8表了,则取出来的tbl24的下一跳值就是对应tbl8表的位置(注意需要右移1位):
} elsetbl8_idx = tbl24_tmp >> 1;现在有了tbl8表的位置了,就可以把真正的下一跳插入tbl8了:
tbl8_ptr = (uint8_t *)dp->tbl8 +(((tbl8_idx * DIR24_8_TBL8_GRP_NUM_ENT) +(ledge & ~DIR24_8_TBL24_MASK)) <<dp->nh_sz);/*update tbl8 with new next hop*/write_to_fib((void *)tbl8_ptr, (next_hop << 1)|DIR24_8_EXT_ENT,dp->nh_sz, redge - ledge);注意这时和插入tbl24表是一样的,也有左右边界,所以需要在目标tbl8表里进一步定位到ledge对应的位置,大致意思是先定位出tbl8表的位置,再定位表里面左边界对应的位置(根据tbl24的定位分析,读者应该可以自行分析了,区别是tbl24只有一个表,所以没有定位表的操作,而是直接在表里定位左边界对应的位置),前面会得到左右边界的结果为:ledge = 192.168.0.8,redge = 192.168.0.16,最终结果如下:

最后一步:tbl8_recycle函数
这个函数主要功能是判断tbl8表的全部下一跳,如果都一样,则把该下一跳的值写回到对应的tbl24表,并把该tbl8表释放掉,这么做的目的其实是为了提高查找效率的,因为查找tbl24表命中的话就直接返回结果了,不用再二次查找tbl8表了;
好了,到目前为止,这四条路由基本把大部分的逻辑都包含了,还有一些没有涉及到的逻辑结合前面的分析应该比较容易理解了,读者可以自行举例分析;
4. Del功能
对应函数:modify函数指针
Del功能主要是对路由信息进行删除,在创建fib表的时候对modify函数指针进行了初始化,该指针指向了dir24_8_modify函数,此函数有个op参数,用于指示add还是del操作,del功能对应RTE_FIB_DEL操作;
对路由信息的删除就是删除fib表里的下一跳,删除trie树里的节点(rib表),跟add的顺序相反;
首先是搜索目标路由节点rte_rib_lookup_exact,找到后首先判断该节点是否有可用的父节点,如果有则判断是否和父节点的下一跳相同,如果不同则把fib表里的下一跳修改成父节点的下一跳,前面分析add功能的时候已经知道,子节点在fib表里是父节点的子集,如果要删除子节点,则需要把子集恢复成父节点的信息;如果没有父节点则直接修改成默认的下一跳:
parent = rte_rib_lookup_parent(node);if (parent != NULL) {rte_rib_get_nh(parent, &par_nh);rte_rib_get_nh(node, &node_nh);if (par_nh != node_nh)ret = modify_fib(dp, rib, ip, depth, par_nh);} elseret = modify_fib(dp, rib, ip, depth, dp->def_nh);然后就是删除树节点了:
if (ret == 0) {rte_rib_remove(rib, ip, depth);if (depth > 24) {tmp = rte_rib_get_nxt(rib, ip, 24, NULL,RTE_RIB_GET_NXT_COVER);if (tmp == NULL)dp->rsvd_tbl8s--;}}进入rte_rib_remove函数看一下:
--rib->cur_routes;cur->flag &= ~RTE_RIB_VALID_NODE;while (!is_valid_node(cur)) {if ((cur->left != NULL) && (cur->right != NULL))return;child = (cur->left == NULL) ? cur->right : cur->left;if (child != NULL)child->parent = cur->parent;if (cur->parent == NULL) {rib->tree = child;node_free(rib, cur);return;}if (cur->parent->left == cur)cur->parent->left = child;elsecur->parent->right = child;prev = cur;cur = cur->parent;node_free(rib, prev);}如果目标节点有左右孩子节点则暂时保留,只是置为不可用状态;否则开始执行删除目标节点的操作:修改孩子节点的父节点,如果目标节点父节点为空代表目标节点是树的第一个节点(顶层节点),这时需要把tree指针修改为孩子节点,也就是说孩子节点成为了一个节点,此时就完成了删除操作,如果目标节点不是第一个节点,则接着往下,判断目标节点是其父节点的左节点还是右节点,以此来决定孩子节点的位置,然后把该节点free,free操作就是把节点归还给节点池rib->node_pool,然后循环执行以上操作,循环的目的是为了删除尽可能多的不可用节点(不可用节点产生的原因又多了一个,就是前面说的左右孩子不为空的情况),用图来表示以上过程比较清晰:

最后还有个判断,如果depth大于24,说明此条路由是存放在tbl8表里的,如果是最后一个路由则需要删除掉tbl8表,所以需要跟着修改rsvd_tbl8s的值:
if (depth > 24) {tmp = rte_rib_get_nxt(rib, ip, 24, NULL,RTE_RIB_GET_NXT_COVER);if (tmp == NULL)dp->rsvd_tbl8s--;}5. Free功能
对应函数:rte_fib_free
首先从全局链表rte_fib_tailq里获取到目标fib,然后从链表里出列,接着挨个free在创建时申请的内存块,比较简单,不再详述;
6. Lookup功能
对应函数:lookup函数指针
在创建fib时调用了dir24_8_get_lookup_fn函数进行了lookup函数的选择,主要是针对不同的平台定义了不同的函数,进行了针对性的优化,但是查表时的主要逻辑是一样的,选择其中一个函数LOOKUP_FUNC进行说明:
此函数为宏函数,主要是批量对ip查找路由,使用了预取的技术提高速度:
rte_prefetch0(get_tbl24_p(dp, ips[i], nh_sz));然后先查tbl24表,如果下一跳指示有tbl8表,则继续查tbl8表,查表原理在add时已经分析过(根据ip定位位置),这里不再分析:
tmp = ((type *)dp->tbl24)[ips[i] >> 8]; \if (unlikely(is_entry_extended(tmp))) \tmp = ((type *)dp->tbl8)[(uint8_t)ips[i] + \((tmp >> 1) * DIR24_8_TBL8_GRP_NUM_ENT)]; \next_hops[i] = tmp >> 1;可以看到查找时没有用到rib表(trie树),而是直接在fib表里查找的,而且最多查两次就可以找到路由,效率很高,但是怎么知道是否查找成功,这里是通过下一跳的值判断的,创建fib表时下一跳被赋予了默认值0,当下一跳的值为默认值时说明路由查找失败。
本文主要讲了DPDK的fib库ipv4部分的代码逻辑,ipv6基本类似,后续有时间再分析,此库主要是管理fib表,利用dir_24_8算法保证了fib表的查找速度,但是也造成了fib表的规模庞大,如果有VRF功能,则内存空间将是个考验,可以参考linux内核3.6版本以后的fib表数据结构LC-trie树,在满足高速查找的同时也保证了空间的控制,当然这和本文是两种不同的算法和数据结构了;
这篇关于DPDK之fib库源码分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







