本文主要是介绍pytorch代码实现注意力机制之SGE,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
SGE注意力机制
SGE注意力机制是一种轻量attention模块,其亮点就是同时几乎不增加参数量和计算量的情况下也能让分类与检测性能得到极强的增益。同时,与其他attention模块相比,它是首个利用local与global的相似性作为attention mask的generation source,同时具有非常强的语义表示增强的可解释性。
SGE注意力模块通过在在每个group里生成attention factor,这样就能得到每个sub feature的重要性,每个group也可以有针对性的学习和抑制噪声。这个attention factor仅由各个group内全局和局部特征之间的相似性来决定,所以SGE非常轻量级。经由训练之后发现,SGE对于一些高阶语意非常有效。
论文地址:https://arxiv.org/pdf/1905.09646.pdf
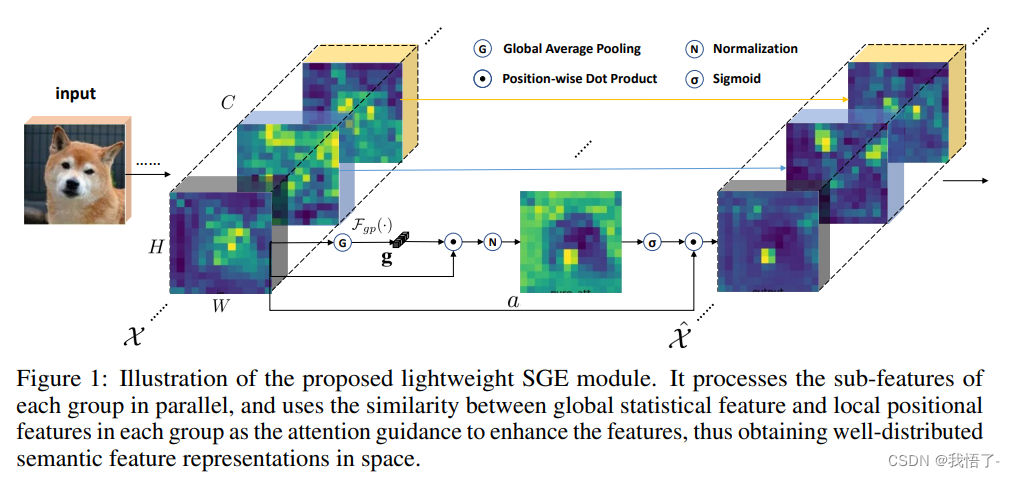](https://img-blog.csdnimg.cn/74c042d1ceec4038a81066f5f635a58a.png)
代码如下:
import numpy as np
import torch
from torch import nn
from torch.nn import initclass SpatialGroupEnhance(nn.Module):def __init__(self, groups=8):super().__init__()self.groups=groupsself.avg_pool = nn.AdaptiveAvgPool2d(1)self.weight=nn.Parameter(torch.zeros(1,groups,1,1))self.bias=nn.Parameter(torch.zeros(1,groups,1,1))self.sig=nn.Sigmoid()self.init_weights()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):b, c, h,w=x.shapex=x.view(b*self.groups,-1,h,w) #bs*g,dim//g,h,wxn=x*self.avg_pool(x) #bs*g,dim//g,h,wxn=xn.sum(dim=1,keepdim=True) #bs*g,1,h,wt=xn.view(b*self.groups,-1) #bs*g,h*wt=t-t.mean(dim=1,keepdim=True) #bs*g,h*wstd=t.std(dim=1,keepdim=True)+1e-5t=t/std #bs*g,h*wt=t.view(b,self.groups,h,w) #bs,g,h*wt=t*self.weight+self.bias #bs,g,h*wt=t.view(b*self.groups,1,h,w) #bs*g,1,h*wx=x*self.sig(t)x=x.view(b,c,h,w)return x if __name__ == '__main__':input=torch.randn(50,512,7,7)sge = SpatialGroupEnhance(groups=8)output=sge(input)print(output.shape)
这篇关于pytorch代码实现注意力机制之SGE的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




