本文主要是介绍CTR模型:WideDeep 网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
0. 简介
Wide and Deep网络(Wide & Deep Learning for Recommender Systems)是2016年被提出的。
出发点:
推荐系统需要同时实现 memorization 和generalization。
memorization, 学习 item 或者 feature的共现关系,并基于历史数据中的这种相关性来推荐。
通过特征交叉可以实现 memorization, 比如 性别 和是否购买汽车作为交叉特征。
generalization: 探索过去从未发生后者很少发生的新特征组合。
提升泛化能力,需要提升特征的粒度, 比如,性别+ 曾经购买汽车的价格<= 10万。
这种方式的限制无法推广到训练集没有出现过的query-item或者 feature pair。
解决方案:
(1)基于Embedding的模型,为query 和item学习一个低维的dense Embedding, 通过Embedding向量来泛化训练集未见过的 query-item feature pair。
当query-item 矩阵非常稀疏,且矩阵的秩较高时,很难学到有效的query-item的低维表达。
Wide网络,通过大量的人工构建交叉特征来提高memorization;缺点是模型表达能力不强,容易欠拟合。
Deep网络:通过特征工程,可泛化未出现的特征组合。即generalization。优点是泛化能力强,缺点是容易过拟合。缺点是表达能力太强,容易过拟合。
1. 总体网络
一个典型的推荐系统整体架构是:

当用户访问 app store 时产生一个query, 包含用户特征(如用户画像)和上下文特征(如 当前时刻LBS信息,设备信息,页面信息)。
检索retrieval 模块根据用户query 返回一组相关app 组成的app list. (召回阶段)
精排 ranking 模块对候选 app list 根据用户的行为(如下载等)概率进行排名,返回概率最高的10几个app组成的推荐结果。
Wide&Deep 模型主要用于ranking 精排模块,包含一个 线性模型和一个神经网络模型。
Wide & Deep模型结合了LR和DNN,其框架图如下所示。

2. Wide网络
这部分特征包括原始的输入特征和转换后特征。
ϕ k ( x ) \phi_k{(x)} ϕk(x) 定义:
设 x = [ x 1 , x 2 , … , x d ] \mathbf{x}=\left[x_{1}, x_{2}, \ldots, x_{d}\right] x=[x1,x2,…,xd] 是一个特征维度为d的向量(经过one-hot),仅包含原始特征。
定义交叉积转换函数(cross-product transformation)
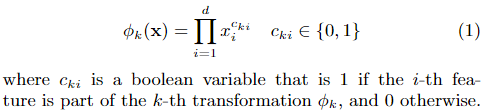

特征交叉
假设将所有categorical特征都按照One-Hot-Encoding(OHE)展开后,一共有n个特征,根据经验对特征进行两两交叉,并和原始特征,作为Wide部分的输入。
所以,Wide 网络输入了one-hot的类别特征,及交叉特征,以及原来的一些连续特征(连续特征可能不需要输入?)。
3. Deep网络
Deep网络使用了 类别特征 + 连续特征!
输入层:DNN的所有离散特征,未经过one-hot.
第一层Embedding层:将高维稀疏的类别特征转换成低维的Embedding向量,Embedding向量维度是32维。(一般是10-100之间)
第二层特征拼接层:将所有的Embedding向量拼接成一个dense feature 向量。 论文是 1200 维。
后续是全连接层。

4. Wide&Deep整体
Wide & Deep model structure for apps recommendation:
Wide网络:以类别特征为主,输入到 LR进行学习;
Deep网络:以连续特征以及类别特征的Embeddings表示为输入,最后,和Wide网络连接同一个LR。
两个网络联合训练。
在共同的LR模型中:
y ^ = P ( Y = 1 ∣ x ) = σ ( w w i d e T [ x , ϕ ( x ) ] + w d e c p T a ( l f ) + b ) \hat y = P(Y=1 | \mathbf{x})=\sigma\left(\mathbf{w}_{w i d e}^{T}[\mathbf{x}, \phi(\mathbf{x})]+\mathbf{w}_{d e c p}^{T} a^{\left(l_{f}\right)}+b\right) y^=P(Y=1∣x)=σ(wwideT[x,ϕ(x)]+wdecpTa(lf)+b)
Wide 线性模型可以有效地通过叉乘的转换记住稀疏特征的交叉,Deep 神经网络可以通过低维的Embedding获得无法看到的特征交叉,具有泛化性能。
模型使用负的对数似然,并用随机梯度下降来训练,和LogisticRegression 模型相似,可以得到损失函数:
loss ( θ ) = − log ( L ( θ ) ) = − 1 N ∑ i = 1 N y ( i ) log P ( Y = 1 ∣ x ) + ( 1 − y ( i ) ) log ( 1 − P ( Y = 1 ∣ x ) ) \operatorname{loss}(\theta)= - \log (L(\theta))=-\frac{1}{N} \sum_{i=1}^{N} y^{(i)} \log P(Y=1 | \mathbf{x})+\left(1-y^{(i)}\right) \log(1-P(Y=1 | \mathbf{x})) loss(θ)=−log(L(θ))=−N1i=1∑Ny(i)logP(Y=1∣x)+(1−y(i))log(1−P(Y=1∣x))
4.1 模型细节
在 Wide&Deep 模型中,每个子模型在训练期间就结合在一起,共同训练。
在 Wide&Deep 模型中,每个子模型都可以比较小,尤其是 wide 部分只需要少量的特征交叉即可
数据生成
- 离散的字符串特征(如app name)映射成为整数ID ,同时生成映射字典vocabulary 。对于出现次数低于指定阈值(如 10此)的字符串直接丢弃,这能够丢弃一些长尾的、罕见的字符串,降低字典规模。
- 连续特征离散化:
首先将连续特征归一化到 0~1 之间,它通过累积分布函数来归一化,计算特征的整体排名(1.0表示排名最高,0.0表示排名最低)

然后将 f(x) 映射到 q 分位。如映射到10分位时,假设 f(x)=0.95 (即排名在最高的 5%),则映射为 9 这个等级。
模型训练阶段:
wide 部分的特征由:用户已经安装的 app 、给用户曝光的 app 的两个特征的交叉组成。
deep 部分从每个离散特征中学习。
增量学习:
每次有新的训练数据到达时,模型会利用该部分数据重新训练。
由于重新训练模型的代价太大,因此我们实现了一个 warm-starting 系统:基于前一个模型的 embedding 和 w w i d e w_{wide} wwide参数来初始化当前模型的这两个参数。
模型预测阶段
将模型部署到服务器上来提供预测服务。
为满足 10ms 量级的响应速度,采用多线程并行来优化性能。方法为:
假设一个 batch 有 500 个候选 app,先将其拆分为更小的一组 batch:如 50 个 batch,每个 batch 有 10 个候选 app。
每个子线程并行的执行推断;
将所有子线程的推断结果收集在一起,拼接成整个 batch 的推断结果并返回。

实验
谷歌应用商店 app下载量:

性能评估:

5. 代码
class WideDeep(nn.Module):def __init__(self,wide_dim,embeddings_input,continuous_cols,deep_column_idx,hidden_layers,dropout,encoding_dict,n_class):super(WideDeep, self).__init__()self.wide_dim = wide_dimself.deep_column_idx = deep_column_idxself.embeddings_input = embeddings_inputself.continuous_cols = continuous_colsself.hidden_layers = hidden_layersself.dropout = dropoutself.encoding_dict = encoding_dictself.n_class = n_class# Build the embedding layers to be passed through the deep-sidefor col,val,dim in self.embeddings_input:setattr(self, 'emb_layer_'+col, nn.Embedding(val, dim))# Build the deep-side hidden layers with dropout if specifiedinput_emb_dim = np.sum([emb[2] for emb in self.embeddings_input])self.linear_1 = nn.Linear(input_emb_dim+len(continuous_cols), self.hidden_layers[0])if self.dropout:self.linear_1_drop = nn.Dropout(self.dropout[0])for i,h in enumerate(self.hidden_layers[1:],1):setattr(self, 'linear_'+str(i+1), nn.Linear( self.hidden_layers[i-1], self.hidden_layers[i] ))if self.dropout:setattr(self, 'linear_'+str(i+1)+'_drop', nn.Dropout(self.dropout[i]))# Connect the wide- and dee-side of the model to the output neuron(s)self.output = nn.Linear(self.hidden_layers[-1]+self.wide_dim, self.n_class)def compile(self, method="logistic", optimizer="Adam", learning_rate=0.001, momentum=0.0):"""Wrapper to set the activation, loss and the optimizer.Parameters:----------method (str) : regression, logistic or multiclassoptimizer (str): SGD, Adam, or RMSprop"""if method == 'regression':self.activation, self.criterion = None, F.mse_lossif method == 'logistic':self.activation, self.criterion = F.sigmoid, F.binary_cross_entropyif method == 'multiclass':self.activation, self.criterion = F.softmax, F.cross_entropyif optimizer == "Adam":self.optimizer = torch.optim.Adam(self.parameters(), lr=learning_rate)if optimizer == "RMSprop":self.optimizer = torch.optim.RMSprop(self.parameters(), lr=learning_rate)if optimizer == "SGD":self.optimizer = torch.optim.SGD(self.parameters(), lr=learning_rate, momentum=momentum)self.method = methoddef forward(self, X_w, X_d):"""Implementation of the forward pass.Parameters:----------X_w (torch.tensor) : wide-side input tensorX_d (torch.tensor) : deep-side input tensorReturns:--------out (torch.tensor) : result of the output neuron(s)"""# Deep Sideemb = [getattr(self, 'emb_layer_'+col)(X_d[:,self.deep_column_idx[col]].long())for col,_,_ in self.embeddings_input]if self.continuous_cols:cont_idx = [self.deep_column_idx[col] for col in self.continuous_cols]cont = [X_d[:, cont_idx].float()]deep_inp = torch.cat(emb+cont, 1)else:deep_inp = torch.cat(emb, 1)x_deep = F.relu(self.linear_1(deep_inp))if self.dropout:x_deep = self.linear_1_drop(x_deep)for i in range(1,len(self.hidden_layers)):x_deep = F.relu( getattr(self, 'linear_'+str(i+1))(x_deep) )if self.dropout:x_deep = getattr(self, 'linear_'+str(i+1)+'_drop')(x_deep)# Deep + Wide sideswide_deep_input = torch.cat([x_deep, X_w.float()], 1)if not self.activation:out = self.output(wide_deep_input)else:out = self.activation(self.output(wide_deep_input))return outdef fit(self, dataset, n_epochs, batch_size):"""Run the model for the training set at dataset.Parameters:----------dataset (dict): dictionary with the training sets -X_wide_train, X_deep_train, targetn_epochs (int)batch_size (int)"""widedeep_dataset = WideDeepLoader(dataset)train_loader = torch.utils.data.DataLoader(dataset=widedeep_dataset,batch_size=batch_size,shuffle=True)# set the model in training modenet = self.train()for epoch in range(n_epochs):total=0correct=0for i, (X_wide, X_deep, target) in enumerate(train_loader):X_w = Variable(X_wide)X_d = Variable(X_deep)y = (Variable(target).float() if self.method != 'multiclass' else Variable(target))if use_cuda:X_w, X_d, y = X_w.cuda(), X_d.cuda(), y.cuda()self.optimizer.zero_grad()y_pred = net(X_w, X_d)loss = self.criterion(y_pred, y)loss.backward()self.optimizer.step()if self.method != "regression":total+= y.size(0)if self.method == 'logistic':y_pred_cat = (y_pred > 0.5).squeeze(1).float()if self.method == "multiclass":_, y_pred_cat = torch.max(y_pred, 1)correct+= float((y_pred_cat == y).sum().data[0])if self.method != "regression":print ('Epoch {} of {}, Loss: {}, accuracy: {}'.format(epoch+1,n_epochs, round(loss.data[0],3), round(correct/total,4)))else:print ('Epoch {} of {}, Loss: {}'.format(epoch+1, n_epochs,round(loss.data[0],3)))def predict(self, dataset):"""Predict target for dataset.Parameters:----------dataset (dict): dictionary with the testing dataset -X_wide_test, X_deep_test, targetReturns:--------array-like with the target for dataset"""X_w = Variable(torch.from_numpy(dataset.wide)).float()X_d = Variable(torch.from_numpy(dataset.deep))if use_cuda:X_w, X_d = X_w.cuda(), X_d.cuda()# set the model in evaluation mode so dropout is not appliednet = self.eval()pred = net(X_w,X_d).cpu()if self.method == "regression":return pred.squeeze(1).data.numpy()if self.method == "logistic":return (pred > 0.5).squeeze(1).data.numpy()if self.method == "multiclass":_, pred_cat = torch.max(pred, 1)return pred_cat.data.numpy()def predict_proba(self, dataset):"""Predict predict probability for dataset.This method will only work with method logistic/multiclassParameters:----------dataset (dict): dictionary with the testing dataset -X_wide_test, X_deep_test, targetReturns:--------array-like with the probability for dataset."""X_w = Variable(torch.from_numpy(dataset.wide)).float()X_d = Variable(torch.from_numpy(dataset.deep))if use_cuda:X_w, X_d = X_w.cuda(), X_d.cuda()# set the model in evaluation mode so dropout is not appliednet = self.eval()pred = net(X_w,X_d).cpu()if self.method == "logistic":pred = pred.squeeze(1).data.numpy()probs = np.zeros([pred.shape[0],2])probs[:,0] = 1-predprobs[:,1] = predreturn probsif self.method == "multiclass":return pred.data.numpy()def get_embeddings(self, col_name):"""Extract the embeddings for the embedding columns.Parameters:-----------col_name (str) : column we want the embedding forReturns:--------embeddings_dict (dict): dictionary with the column values and the embeddings"""params = list(self.named_parameters())emb_layers = [p for p in params if 'emb_layer' in p[0]]emb_layer = [layer for layer in emb_layers if col_name in layer[0]][0]embeddings = emb_layer[1].cpu().data.numpy()col_label_encoding = self.encoding_dict[col_name]inv_dict = {v:k for k,v in col_label_encoding.iteritems()}embeddings_dict = {}for idx,value in inv_dict.iteritems():embeddings_dict[value] = embeddings[idx]return embeddings_dict
最近开通了个公众号,主要分享推荐系统,风控等算法相关的内容,感兴趣的伙伴可以关注下。

参考:
- zhihu Wide and Deep Network;
- 论文2016 Wide & Deep Learning for Recommender Systems;
- 论文笔记 - Wide and Deep Learning for Recommender Systems;
- wide and deep github;
- ctr模型汇总;
这篇关于CTR模型:WideDeep 网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





