本文主要是介绍Numpy文件交互:.npy和.npz有什么区别?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- save
- load
- savez
- savez_compressed
Numpy提供了以.npy为后缀的文件存储方案,与这种文件格式密切相关的读、写函数分别是np.load和np.save。通过savez可以一次性存储多个数组,并可通过load以键值对的形式读取出来;如果觉得文件太大,可以通过savez_compressed进行压缩。
save
save函数的定义为
numpy.save(file, arr, allow_pickle=True, fix_imports=True)
其中file为文件路径,若不以.npy为结尾,则自动添加.npy后缀;arr为待存储数据。allow_pickle为True时,允许通过Python自带的pickle来存储对象;fix_import为True时,pickle将为旧的Python2数据尽量匹配成Python3的。
import numpy as np
x = np.arange(10000)
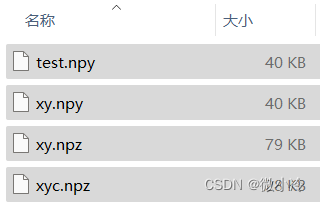
np.save("test", x)
# x被存储为`test.npy`
load
用于读取numpy文件的load函数定义如下
numpy.load(file, mmap_mode=None, allow_pickle=False, fix_imports=True, encoding='ASCII', *, max_header_size=10000)
其中file是文件名,encoding为编码方式,这没什么好说的;allow_pickle, fix_imports和save中相同。max_header_size为头文件尺寸,表示读取时跳过的内容。
map_mode为内存映射模式,可选r+, r, w+, c。
通过load,可以将刚刚存储的test.npy读取出来
y = np.load("test.npy")
(x==y).all()
# 返回True,说明x和y全等
savez
save只能存储一个数组对象,多了会忽略;savez则解决了这个问题
np.save("xy", x,y,y)
test = np.load('xy.npy')
print(test) #[ 0 1 2 ... 9997 9998 9999]
print(len(test)) # 10000np.savez("xy", x, y)
test = np.load('xy.npz')
print(test.files)
# ['arr_0', 'arr_1']
print(test['arr_0'])
# [ 0 1 2 ... 9997 9998 9999]
即savez将多个数组存入到了文件中。
savez在存储文件时,字典的键值是可以更改的
np.savez("xy", x=x, Y=y)
test = np.load('xy.npz')
print(test.files)
# ['x', 'Y']
savez的运行逻辑,是先将每一个数组存为npy之后,再将这些npy压缩为zip文件,最后在zip文件外面套一层npz的壳。所以通过savez存储的文件,在被load之后,得到的是一个NpzFile对象,其中包含了zip属性,在这个属性中,可以看到arr_0.npy和arr_1.npy的信息。
>>> print(test.zip.NameToInfo)
{'arr_0.npy': <ZipInfo filename='arr_0.npy' filemode='?rw-------' file_size=40128>, 'arr_1.npy': <ZipInfo filename='arr_1.npy' filemode='?rw-------' file_size=40128>}
savez_compressed
savez_compressed和savez的唯一区别就是,前者有压缩。
刚刚通过savez存储的文件有79kb,但x和y其实是相同的内容,这样存储十分奢侈,
np.savez_compressed('xyc', x, y)
最后得到的xyc只有28kb,可以说是很划算了。
这篇关于Numpy文件交互:.npy和.npz有什么区别?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





