本文主要是介绍QCOW2和RBD快照克隆原理对比,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 简介
- 快照实现原理
- QCOW2
- 快照原理图
- 快照过程
- 快照之后的写入
- 元数据状态图
- 还原快照
- QCOW2查找当前镜像的数据和快照数据有什么区别?
- RBD
- 快照原理图
- 快照过程
- 快照之后的写入
- 快照镜像重建
- 还原快照
- 克隆前为什么要做快照保护?
- 快照机制对比
- 相同点
- 不同点
- 克隆实现原理
- QCOW2
- RBD
- 克隆实现对比
- 相同点
- 不同点
前言
- RBD和QCOW2作为存储虚拟化中两个重要的磁盘格式,在概念和使用上都有很多相似的地方,但其内部实现原理稍有差别。RBD是ceph对外提供的虚拟化块设备,其实现依赖ceph的对象存储技术;QCOW2是qemu提供的本地虚拟化块设备,其实现基于QCOW2的文件格式,本质上是文件。快照,克隆等高级特性基于底层技术的实现,因此在原理上多有不同,本文主要分析这种差异
简介
- qemu模拟磁盘供虚拟机读写,原则上,只要qemu能将虚拟机下发的指定偏移和大小的写请求数据保存,并在读请求时正确返回,就可以保证虚拟机IO正常工作。
- qemu拿到虚拟机的IO数据后怎样保存到介质上,可以由不同的思路来实现,而最终的每种实现就对应一种虚拟的磁盘格式。这个磁盘格式又分了两类,一类是基于本地文件系统的实现,不同的元数据格式对应不同的磁盘格式,比如qemu实现的:qcow,qcow2,raw(特殊情况:没有元数据),其它厂商或者开源
hypervisors实现的:VMWare厂商的VMDK(VMWare Virtual Machine Disk Format),开源软件VirtualBox的VDI(Sun xVM VirtualBox Virtual Disk Images)等等。另一类基于分布式文件系统来实现,比如基于ceph的RBD和GlusterFS的gluster等,qemu对这类磁盘的读写操作和高级特性操作(快照,克隆)需要使用分布式文件系统提供的库接口 - qcow2和rbd分别是本地文件系统实现存储虚拟化和分布式文件系统实现存储虚拟化的代表
快照实现原理
- qcow2快照基于元数据
L1 table,L2 table,snapshot table和refcount table实现,快照创建实质是通过操作这些元数据增加对cluster的引用计数。qcow2在写cluster的流程中会先检查其上是否有引用计数,如果有就先拷贝一份再写,引用计数是判断是否对cluster写时复制(COW - Copy On Write)的依据,qcow2磁盘管理的基本单元是cluster,所以COW复制的基本单元是cluster - RBD镜像由
Rados对象组成,这些对象分为两类,一类是元数据对象:rbd_id,rbd_header和rbd_object_map,存放镜像的名字,id,快照信息以及父镜像快照信息等元数据;另一类是数据对象:rbd_data,存放RBD镜像的数据。Rados对象本身实现了快照功能,RBD快照基于此实现,RBD快照创建的实质是向服务端申请新的snap id,将其更新到元数据对象rbd_header的snap_seq字段,同时将创建的快照信息存放到snapshot_<snap_id>中。一个RBD镜像包含一个最近一次创建的快照的快照ID,和多个snapshot_<snap_id>,每个snapshot_<snap_id>存放的时id为snap_id的快照的基本信息,比如名字,id,镜像大小等。RBD镜像的快照只更新了镜像的元数据对象rbd_header,组成镜像的数据对象没有任何变化,因此速度也很快。RBD在写流程中,需要携带SnapContext,SnapContext是RBD镜像对自己最新的快照的快照 id和所有快照序列号的封装,服务端通过对比客户端的SnapContext和自己维护的SnapSet,来决定是否进行写时复制。服务端对每一个rados对象都维护一个快照信息,当RBD镜像在被写入时,只有写入区间包含的rados对象才进行写时复制,因此写入操作速度不会受拷贝操作严重影响。RBD镜像由Rados对象组成,所以COW复制的基本单元是Rados对象
QCOW2
快照原理图
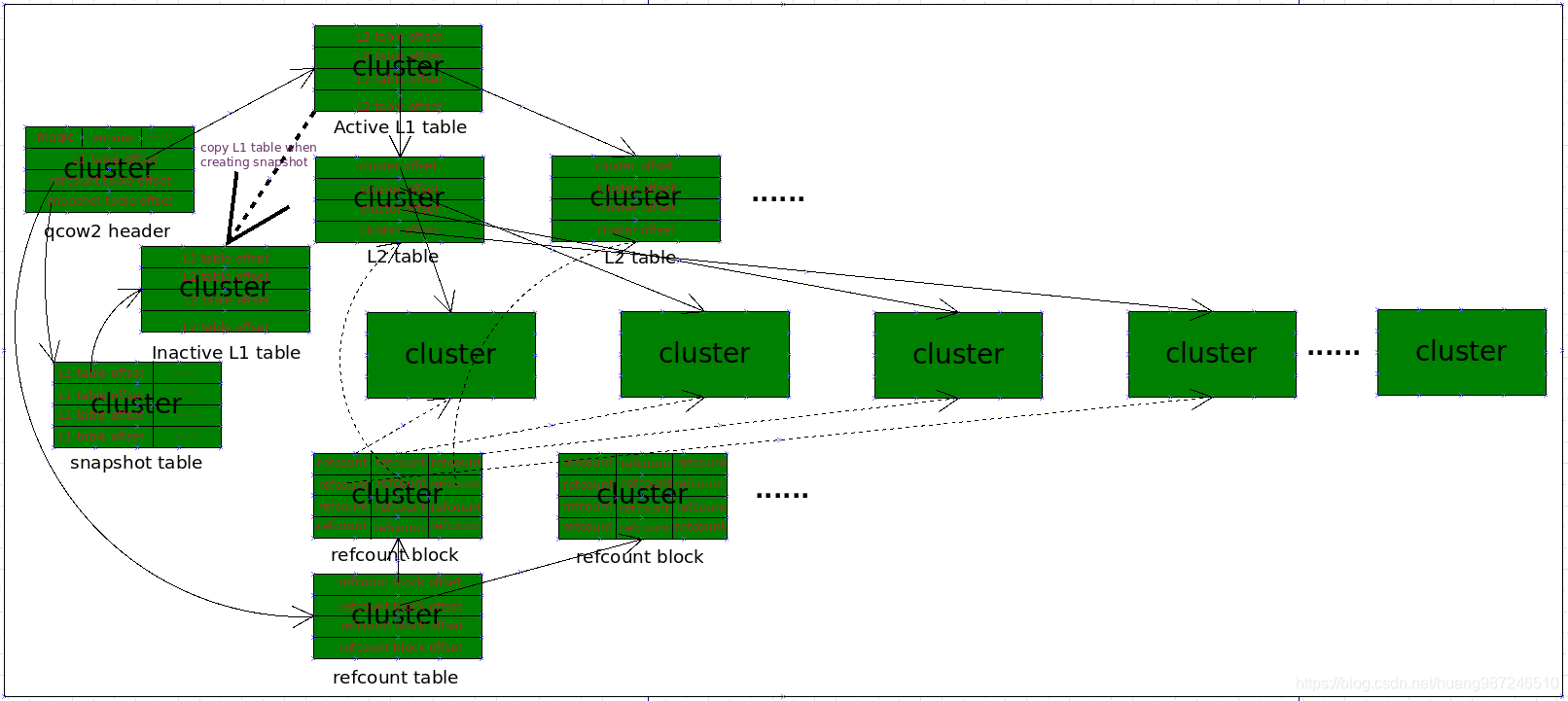
快照过程
上图描述了一个qcow2文件镜像的布局,qcow2将镜像分为一块块cluster进行管理,cluster要存放虚拟机的数据,也要存放qcow2管理的元数据,qemu对qcow2镜像的IO操作最小单位就是cluster。每个cluster的地址由L2表里面的条目记录,L2表的地址由L1表记录,L1表地址由header记录,qcow2 header位于文件镜像起始处,因此通过Header->L1 table offset->L2 table offset->cluster就可以找到虚拟机存放的数据,原理上只要获取了L1 table,就获取了整个qcow2镜像的数据。所以qcow2的快照实际就是拷贝L1 table,然后将L1 table覆盖的所有cluster的引用计数+1,就完成了整个快照动作,快照完成后就有两个L1 table记录了同一个L2 table的地址。一个是快照表中记录的L1 table,一个是header中记录的L1 table
快照之后的写入
qemu写qcow2 cluster前会先检查引用计数,只有引用计数为1的才能直接写,反之需要拷贝一个cluster,并在新的cluster上写数据。新的cluster地址变了,数据写完后需要将新cluster的地址更新到L2 table中,更新前检查L2 table的引用计数是否为1,如果为1表示没有快照引用这个L2 table,可以直接写,反之同样拷贝一个新的L2 table,将新cluster偏移地址写到新的L2 table中,旧的L2 table表不变,仍旧指向旧的cluster。新的L2 table的地址变了,需要更新它在L1 table中记录的地址。旧的L2 table地址没有变,但它的地址不再被Active L1 table记录,只有快照时候拷贝的Inactive L1 table继续指向旧的L2 table地址。快照之后的写入,又会让之前指向同一个L2 table的两个L1 table分别指向不同的L2 table
元数据状态图
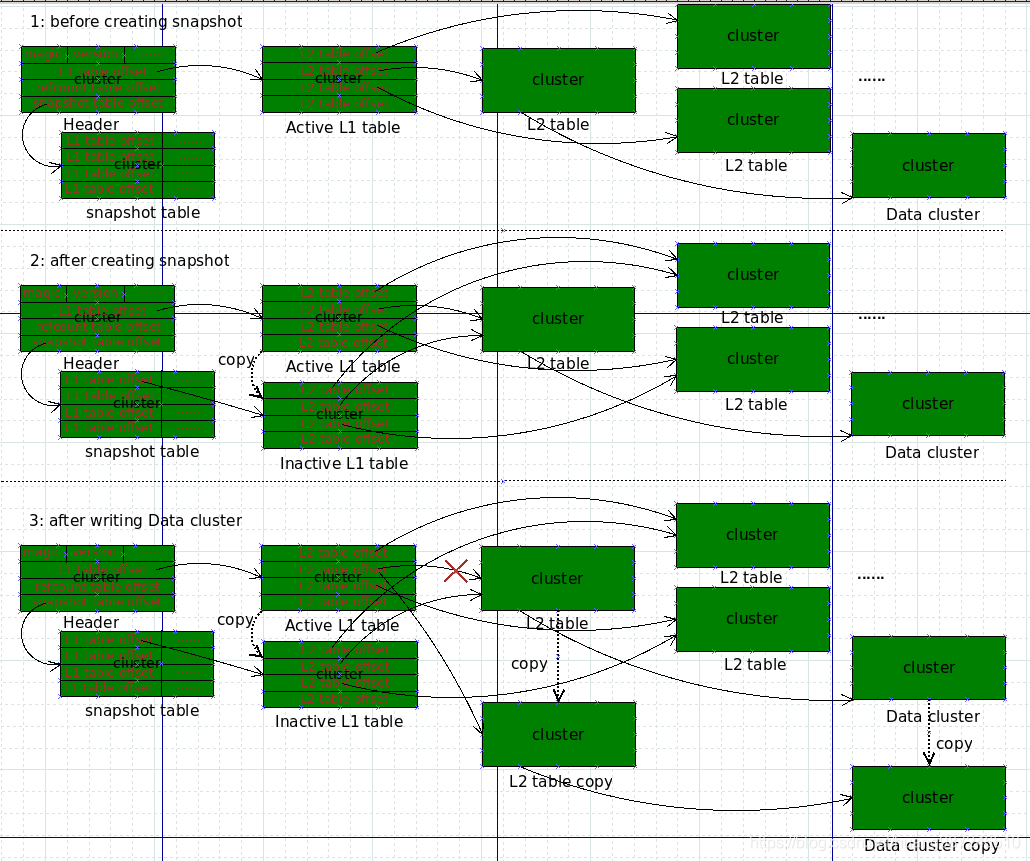
还原快照
qcow2还原快照原理很简单,将要还原的快照的L1 table设置为Active L1 table就可以了
QCOW2查找当前镜像的数据和快照数据有什么区别?
从上面可以看出,根据1个L1 table中的元数据可以重建出qcow2镜像在某个时刻的数据,Active L1 table是当前qcow2镜像的元数据,而snapshot table中记录的每一个Inactive L1 table地址,是qcow2镜像在某个时刻的元数据。因此qcow2使用Active L1 table就可以查找当前镜像的数据,使用Inactive L1 table可以查找某个镜像快照的数据。qemu-img covert操作就实现了qcow2镜像的数据重建,当命令不指定快照时,重建的是Active L1 table覆盖的所有数据,当命令指定快照时,重建的是在快照表中查到的该快照对应的Inactive L1 table覆盖的所有数据
RBD
快照原理图
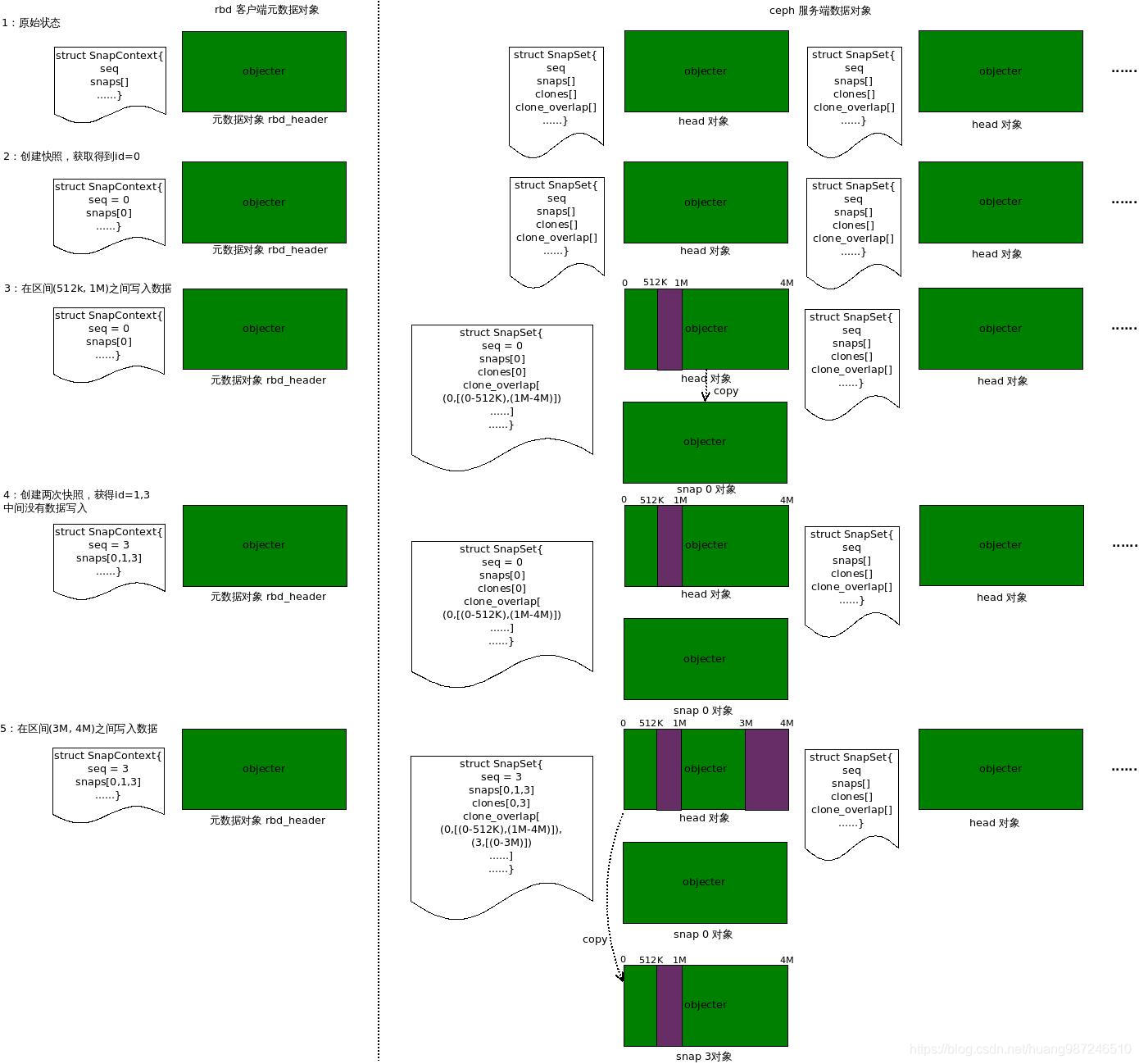
快照过程
RBD镜像由Rados对象组成,数据存储其中有三种方式:Rados对象的数据部分;Rados对象扩展属性(xattr);Rados对象omap。用户根据自己的数据形式选取合适的存储方式。RBD镜像包含的对象可以分成两类:保存RBD客户端元数据的对象和保存Ceph服务端数据的对象。
RBD镜像的元数据大多放在客户端元数据对象rbd_header中,包括存放镜像数据的存储池,镜像启用的功能特性,镜像大小,快照信息,父镜像快照信息等。其中快照相关信息:snap_seq和snapshot_<snap_id>列表,分别表示最近一次创建的快照的快照序列号和镜像所有快照信息的列表。这两个信息是实现RBD快照客户端的关键信息。
服务端的数据对象的扩展属性中保存了数据对象的属性,包括该对象的最新快照序列号,所有快照序列号列表,所有快照对象的序列号和所有快照对象间的重叠区域等。其中快照相关信息:seq和snaps列表,分别表示最新快照序列号和所有快照信息的列表。这两个信息是实现RBD快照服务端的关键信息。
RBD的快照操作就是向ceph服务端申请更新的快照序列号,然后更新rbd_header对象中保存的snap_seq,并将快照信息添加到以快照序列号为索引的snapshot_<snap_id>列表中。
快照之后的写入
快照之后的写入操作会携带SnapContext信息,负责Rados对象写入的Rados层会对比客户端SnapContext中快照信息和自身元数据信息SnapSet中的快照信息,如果客户端的快照序列号更新,在写入前就需要做拷贝(COW),Rados称镜像的原对象为head对象,通过cow拷贝出来的对象为snap对象。Rados对象通常存储数据的区间为4M,只有落在写入区间的Rados对象,才会被写入数据,因此也之后这些对象才会发生cow,所以RBD镜像快照之后的写入,只有写入区间内的Rados对象才进行拷贝,将整个镜像的数据拷贝尽量延后。
将head对象拷贝之后,就可以进行写入操作了,写入完成,会用客户端的快照信息更新服务端数据对象的快照信息,因此客户端下一次在没有做快照的情况下再发起写入操作,就会正常的进行对象写入。
通过上面的介绍,可以知道,RBD镜像在做了快照之后再写入,会触发部分head对象的拷贝动作,有两种情况:当数据对象没有在写入区间内,不会进行拷贝,当数据对象在写入区间,才进行拷贝。因此如果根据快照重建RBD镜像,只需要将序列号小于或等于快照序列号的对象包含进来,就能重建快照时的镜像
快照镜像重建
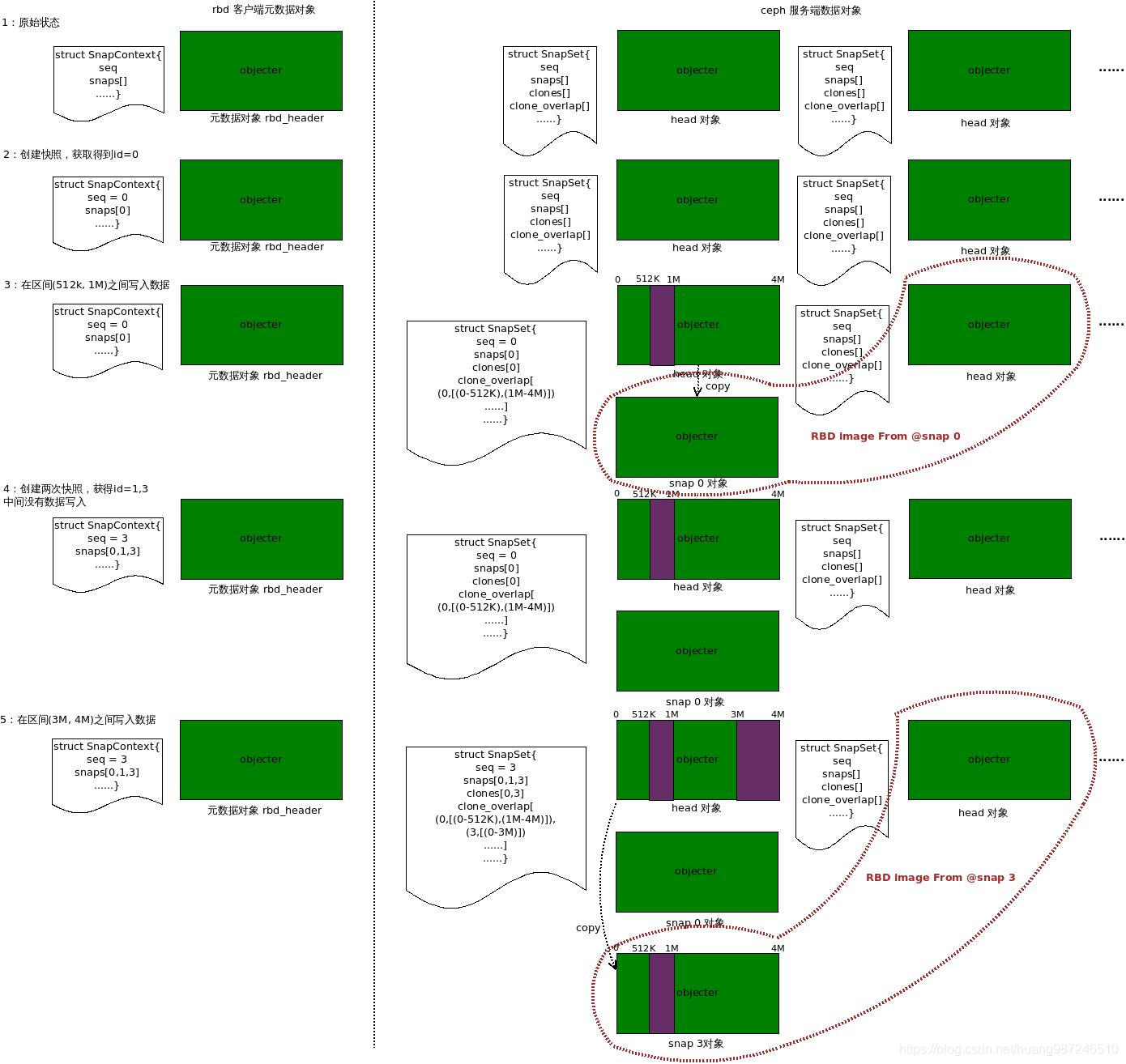
如上图,在步骤3写入数据后,如果想重建快照snap 0,由于整个镜像由两个Rados对象组成,所以只需要在这两个对象中获取"合适"的对象就行,因为第一个对象的所有快照对象中,有序列号为0的快照对象,表明这是创建snap 0之后head对象有写入触发了cow拷贝的对象,选取snap 0 对象作为区间(0-4M)的数据对象,第二个对象没有快照对象,表明在创建snap 0 后还没有写操作,这个对象数据没有变,因此直接选取head对象作为区间(4M-8M)的数据对象。两个对象一起组成了一个8M的RBD镜像,这个镜像还原了创建snap 0时的RBD镜像数据。同样可以重建snap 3快照时的RBD镜像。
RBD镜像的克隆操作,就是变相地重建快照镜像,因为镜像的head对象会因为数据写入而频繁变化,因此克隆不能基于RBD的原对象,需要指定基于哪个快照进行,也就是上面所说的根据快照重建RBD镜像
还原快照
RBD的快照回滚操作就是删除当前head对象的数据,将snap对象中的数据拷贝到head对象中
克隆前为什么要做快照保护?
克隆就是基于快照的镜像重建,暂且称为快照镜像,如果快照镜像中包含head对象,原镜像进行删除镜像操作时,如果检查到head对象有快照在引用,为了不让克隆镜像就失去对该head对象的引用,不会允许对原镜像的删除操作
快照机制对比
相同点
qcow2和rbd的快照原理相同:在镜像写入前检查落在写入区间的数据块是否标记COW,如果有标记,拷贝一份后写入。qcow2检查的区间是cluster,只要一个cluster标记了cow,这个cluster在被写入时需要先拷贝;rbd检查的区间是Rados object,一个被标记了cow的object被写入时也需要先拷贝
不同点
- 做快照标记cow的实现不同,qcow2标记cow,在快照的时候就完成了,快照时会更新
Active L1 table覆盖的所有cluster的引用计数,写入数据的时候没有cow的相关操作,只是纯粹的检查cow标记;rbd在快照的时候,把cow标记在了客户端身上,这个操作只完成了cow标记的前半部分,在客户端写数据时还会携带cow标记,因此cow标记的后半部分在写数据时才完成 - 快照信息描述的粒度有差别,qcow2的快照信息描述的整个镜像,一个镜像只有一张快照表,通过
cluster的元数据无法知道自己的快照历史;rbd的快照信息有两个,客户端的快照信息描述整个镜像,服务端的快照信息描述一个对象,通过object的元数据可以知道自己的快照历史
克隆实现原理
QCOW2
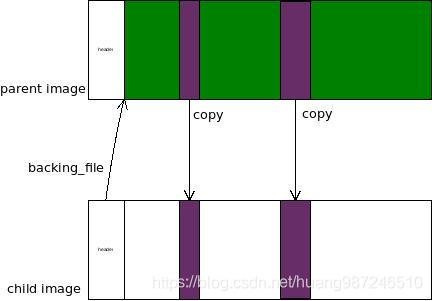
qcow2是文件实现的磁盘格式,克隆原理比较简单。qcow2 header里面的backing_file_offset存放了其父镜像的名字,利用这个就可以实现克隆:新建一个镜像,将父镜像的名字记录在新镜像header的backing_file_offset处。
读镜像数据时,如果子镜像中没有数据,就查看是否有父镜像,如果有就从父镜像中读取数据返回给用户。
写镜像数据时,查看落在写入区间的cluster是否已经分配,如果没有,新分配一个cluster,但其内容需要从父镜像中拷贝,然后再写入到子镜像的cluster。
因此,从一个镜像克隆新镜像很快,只需要创建一个没有数据的空qcow2镜像,然后将把父镜像的名字保存到克隆镜像的header中,就完成了克隆,之后的读写操作,只要按照上述规则来就可以了。
RBD
RBD是分布式的镜像,由于分布式的特性,克隆原理比qcow2要复杂一些。
因为存在多个客户端读写一个rbd镜像的情况,让所有客户端都创建新的空镜像从而实现克隆比较复杂,因此原镜像继续承载客户端的读写,镜像里面的head对象继续作为数据最终写入的地方。由于有数据的变化,head对象没法作为子对象的"backing object",因此rbd用snap对象组成的镜像数据,作为子镜像的backing ,所以rbd在做克隆时需要指定基于哪个snap,如果没有快照,需要提前创建,然后将快照保护起来。
RBD镜像克隆的实现:新建一个镜像,将父镜像的名字和它基于快照信息记录到新镜像rbd_header元数据的parent字段中。
读镜像时,如果读区间中不存在数据对象,读操作就会检查是否有parent,如果有,从关联的快照image中读取数据,这里返回读取区间的数据。
写镜像时,如果当前镜像不存在数据对象,写操作会迭代查找其parent,直到找到存在数据对象的parent为止,然后将整个对象的数据拷贝到克隆对象中。
RBD克隆一个镜像也非常快,实际就是创建一个空的rbd镜像,然后将其关联的parent镜像的快照信息写入rbd_header中,建立父子关系,就可以了。
克隆实现对比
相同点
- qcow2和rbd克隆实现原理类似,都是新建一个精简镜像,通过镜像的元数据保存其parent的信息。在真正读写镜像,如果数据区间不在当前镜像中,就去
parent中查找,这个查找时迭代的,直到找到为止。对于读,直接返回数据,对于写,会拷贝数据区间所属的cluster或者object到子镜像中,下一次读写就可以在当前镜像中找到。
不同点
- qcow2克隆的镜像,读写基于一个镜像,rbd克隆的镜像,读写基于一个镜像的快照镜像。rbd的克隆,有点儿像qcow2的qemu-img基于快照的convert操作,读写是基于快照。
附:外部快照实现方案

这篇关于QCOW2和RBD快照克隆原理对比的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




