本文主要是介绍独家采访 | 智能源于自发产生而非计划:进化论拥趸,前OpenAI研究经理、UBC大学副教授Jeff Clune...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

导读:
“通用智能的发展依赖于构建能够自行生成算法的AI,只有这样才能让AI摆脱人类的手工规划,真正地走向自主发展的道路。”
对于如何实现通用智能,前OpenAI研究经理、英属哥伦比亚大学副教授Jeff Clune认为,达尔文进化论已经给了我们答案——从单细胞生命到人类文明,智能的发展似乎暗示着一个规律——智能或许并不是被计划好的。它诞生于智能体自身的不断迭代和进步。在这个过程中,智能体自身会产生有利于其发展的进化方法(算法)。
作为进化论的拥趸,Clune早年为了探究智能的本质,完成了哲学的学习。之后又因为阅读了美国进化算法科学家Hod Lipson的报道,毅然投入到人工智能的学习和研究中。之后他与同事们联合成立了Uber AI Lab,并担任过OpenAI研究团队的负责人。近日在AI学界引起关注的VPT(Video Pretrained)模型便有Clune的贡献。
此外,Clune教授还在2022年智源大会上做了题为“Improving Robot and Deep Reinforcement Learning via Quality Diversity, Open-Ended, and AI-Generating Algorithms”演讲,回看详见文末。
近日,智源社区采访了Clune教授,请他谈谈自己早年的科研经历,并为读者解读AI-GAs的核心思路。

(图片来源:智源大会官网)
Jeff Clune
前OpenAI研究经理、英属哥伦比亚大学副教授
Jeff Clune主要研究深度学习,包括深度强化学习。此前,他是OpenAI研究团队负责人,Uber人工智能实验室的高级研究经理和创始成员,怀俄明大学计算机科学的哈里斯副教授,以及康奈尔大学的研究科学家。他获得了密歇根州立大学(博士、硕士)和密歇根大学(学士)的学位。自 2015 年以来,他获得了白宫颁发的科学家和工程师总统早期职业奖,在《Nature》发表了两篇论文,在PNAS发表了一篇论文,获得了NSF CAREER奖,十年杰出论文和杰出青年研究员奖,并在顶级机器学习会议(NeurIPS、CVPR、ICLR 和 ICML)上获得了最佳论文奖、口头报告和邀请讲座。他的研究经常被媒体报道,包括《纽约时报》、NPR、NBC、《连线》、BBC、《经济学家》、《科学》、《自然》、《国家地理》、《大西洋》和《新科学家》。
采访撰稿:戴一鸣
编辑:李梦佳
从哲学生到计算机博士,孜孜追求解答进化与智能两大问题
1. 达尔文进化论的忠实拥趸,想通过哲学理解智能本源
Jeff Clune并非一开始就进入计算机科学的领域。在本科阶段,他在密歇根大学学习哲学。根据Uber Engeering在2019年的采访文章[1],Clune一直对于两个问题非常痴迷:
地球上如此复杂的生命形式是如何演化出来的?比如说,自然界为何有美洲豹、鹰、海豚、鲸鱼等各种各样不同形式的生命?什么样的方式能够诞生出如此无穷无尽的生命工程奇迹?达尔文的进化论回答了一些问题,但还有很多人类没有理解的地方。
“思考”是如何发生的?我们是否能够构建一个有思想的机器?
为此,Clune选择哲学作为大学专业。令他感到失望的是,尽管哲学非常有趣,他却无法检验自己的观点是否正确并通过迭代的方式改进。[1]
2000年代初,Clune阅读了一篇介绍时任康奈尔大学教授Hod Lipson[7]使用进化算法开发机器人的文章[2]。他深受影响,打算选择研究机器学习和计算机科学,因为他终于有机会能够通过构建智能系统,从而来理解它。Clune认同美国理论物理学家Richard Feynman的名言:“What I cannot create, I do not understand.”(我所不能创造的,我便不能理解。)在Clune看来,人工智能研究是可以解答进化和思考问题的绝佳途径。
2. 跨专业申请博士屡遭拒绝,八年求学为与偶像共事
怀着一腔热情的Clune首先联系了Hod Lipson,希望能够加入他的实验室。遗憾的是,实验室需要申请者具有计算机博士学位,而Clune当时仅仅本科毕业。之后在申请博士的过程中,由于他只有哲学背景,因此遭到了广泛的拒绝[1],而申请计算机PhD项目,需要有一个本科的计算机学位。
机会来自密歇根州立大学,Clune发现有一位教授与使用进化算法领域的研究者一起研究生物系统复杂性的进化进程。Clune于是在密歇根州立大学完成了哲学硕士的学业,并申请了计算机博士项目。终于,在读到Lipson的文章近8年后,Clune获得博士学位并跟Lipson取得了联系。“我现在有博士学位了,可以加入你的实验室吗?”[1]

Hod Lipson教授
(图片来源:维基百科[7])
Lipson教授爽快地答应了。Clune加入实验室后非常激动。据形容,那里就像是小说《查理与巧克力工厂》中眼花缭乱的威利旺卡巧克力工厂一样。[1] 两年后,Clune在怀俄明大学成立了自己的实验室。现在,他几乎每周都能收到学生的邮件,他们也像当年的自己一样,渴望进入人工智能的领域,但不知道应该怎么去做。

Clune在康奈尔大学Hod Lipson教授的Creative Machine Lab,使用3D打印机打印由人工智能设计的物体[10]。特别的是,这些物体是基于发展生物学(Developmental Biology)启发的编码设计生成的,这种思路被称为CPPNs[11],由 Kenneth Stanley提出。
(来源:作者本人提供)
3. 伟大无法被计划:影响Clune的重大思想
Clune表示,对他职业生涯影响最大的是前中佛罗里达大学计算机科学教授Kenneth Stanley。Stanley教授是Geometric Intelligence的联合创始人,Clune曾经也在这家创业公司,后来被Uber收购,成为创建Uber AI Labs的一部分(Stanley教授也是该实验室的创始成员)。Stanley于2020年加入OpenAI,他以神经进化方面的许多突破而闻名,包括 NEAT [9]、HyperNEAT、CPPNs、Novelty Search、POET和Go-Explore(最后两个与Jeff Clune合作)等。

(图片来源:https://www.goodreads.com/book/show/25670869-why-greatness-cannot-be-planned)
Stanley与Joel Lehman合著了学术著作——《为什么无法计划伟大:目标的神话》(Why Greatness Cannot Be Planned: The Myth of the Objective)。该书提出了“目标悖论”的观点,指出:“一旦创造了一个目标,我们就毁掉了实现它的能力”。这本书中的许多想法都体现在Stanley和Clune在质量多样性算法(Quality Diversity Algorithms)和开放式算法(Open-ended Algotithms)方面的工作中,例如在POET[3]和Enhanced POET(https://arxiv.org/abs/2003.08536)。

Kenneth Stanley教授
(图片来源:https://www.youtube.com/watch?v=dXQPL9GooyI)
在近期,Clune及其研究团队提出了视频预训练模型VPT[8],能够帮助AI从无监督的视频数据中学习完成任务的行动。智源社区请Clune教授对此进行了解读。
VPT:用视频做预训练,学的则是行动
1. 序列任务:巧妇难为无米之炊
序列任务是人类日常生活中场景的一种任务形式,可以被定义为需要多个步骤、工序或行动才能完成的工作,如按照步骤完成烹饪食材、浏览网页寻找正确的信息、进行化学实验、根据说明步骤组装家具等。这种任务对于人类而言较为简单。人们只需要根据说明书、指示图、视频教程或其他资料进行模仿学习,在相对较短的时间内就可以掌握行动,完成任务。
然而,这种看似简单的任务,对于AI则比较困难。Clune和他的同事们认为,最重要的原因在于当前公开的数据都缺乏标注标签。例如,在视频教程中,没有对每一帧的行动进行监督学习标注,所以AI仅看视频去学习这些行动是非常困难的。
强化学习往往是序列任务方面常用的方法,但根据VPT论文[4],这种方法的采样效率较低。而且来自环境的奖励非常稀疏,但有些步骤需要AI去重复多次才能完成,甚至还有欺骗性的hard-exploration,对于强化学习的成本很高。在包括浏览网页,使用PS软件,订机票等任务上,强化学习的性能表现不佳。因此,如何探索一种小样本、利用好大规模无监督数据的解决方案,成为研究者思考的重点。
2. VPT:基于伪标签的大规模无监督训练
当前主流的半监督模仿学习的目标就是让模型能够从少量或者没有明确行动的标签(即伪标签)中学习。VPT采用了基于少量标签进行无监督训练的思路。研究者采用了视频作为数据模态。
首先,在VPT项目中,众包人员需要录制完成某个任务的视频,并记录完成这个任务过程中的动作,以及其对应的键鼠操作(点按、拖拽等)作为视频帧对应的标签。当然,标注数据量相比整个无监督数据集而言规模很小。
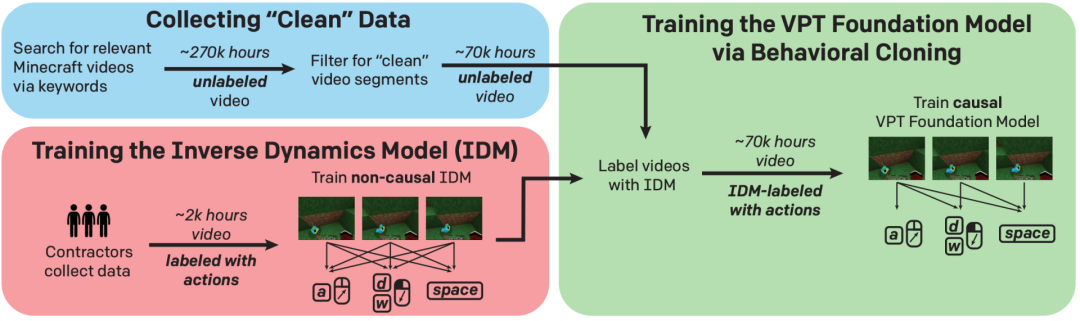
VPT的训练过程
(图片来源:VPT论文[4])
研究者选择了风靡全球的沙盒模拟游戏MineCraft(MC)作为任务场景。在网络上,已经有大量的MC游戏视频作为无监督数据。MC集建造、养成、冒险等特性于一身,包含大量的序列行动任务。在MC中,玩家按照一定的顺序收集、组合原料,制造更为复杂的道具。
想要在MC游戏中成功,智能体需要用和人类一样的方式采取行动(如移动鼠标、点按正确的键盘快捷键、拖拽获取物品、对游戏中的动植物发起攻击等)。MC也有很多简单的图形交互界面让AI来学习操作。最后,MC本身已经是测试AI学习能力的一个重要的平台,而且提供了丰富的组件,例如模拟的3D世界,有科技树等,对于AI的训练而言足够友好,但也具有一定的挑战性。
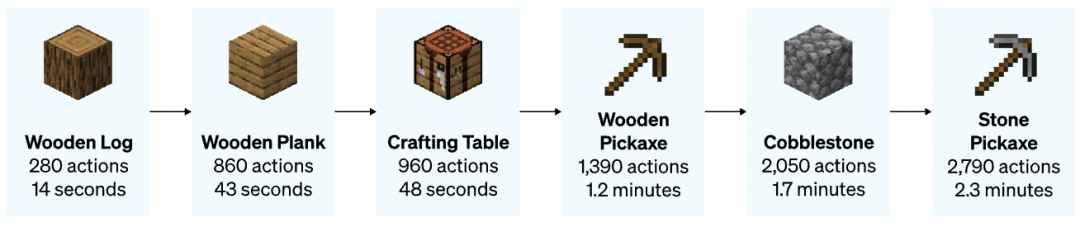
MC游戏中制作石镐需要经过的流程、动作数量和人类需要完成的中位数时间
(图片来源:VPT博客[8])
接着,研究者设计了一个逆动态模型(Inverse Dynamics Model,IDM),使其学习标注数据视频中行动的序列。训练的目标是:给定视频中每一个时间步,根据其前后时间的行动,来预测当前时间步正在进行的行动。传统上研究者往往采用的是行为克隆(Behavioral Cloning,BC)模型,这种模型是根据对于过去的观察(包括行动和环境的改变等),对下一个时间步的意图和分布进行预测,这需要大量的数据进行训练。IDM模型则是非因果(Non-causal)的,其可以看到被预测的行动过去和未来的行动。[4]
同时,在大多数设置下,环境中发生的改变远远小于人类行动的变化,所以IDM模型只需要关注行动本身,对于环境的改变进行一定程度的忽略,这就只需要更少量和简单的标注数据进行训练。
训练好IDM之后,研究者令其对大规模的无标注训练数据生成伪标签,然后再次训练一个BC模型,使其模仿学习。训练完成后,该模型便可以进行精调从而用于下游任务,采用行为克隆和强化学习的方式。
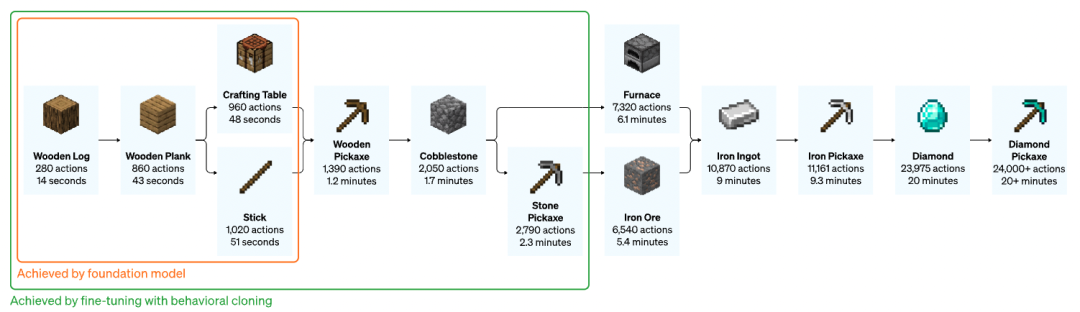
经过预训练的模型通过微调和强化学习的方式学会了制作石镐和钻石镐
(图片来源:VPT博客[8])
如上图所示,研究者让模型学习如何制作木棍和建造台(Crafting Table)后,然后让模型完成了制作钻石镐的任务。相比采用随机初始化的强化学习模型,VPT成功实现了制作钻石镐(在10分钟的视频中有2.5%完成),而且在成功率(以是否能够收集到所有的制作材料评价)上达到了人类同等的水平,这是第一次实现了智能体在MC游戏中完成制作钻石镐的任务。而对于这个任务,人类平均需要进行24000个动作,花费超过20分钟的时间。[8]
为何不让模型直接生成视频帧?Clune认为,这次的研究是让AI根据视频学习执行某个任务的动作和操作顺序。更为高效的方法是让模型学习如何去行动,而不是学习生成未来视频的表示。他举例说,想象在一个游戏中可能有很多复杂的云朵模式,但是这些云的形状本身对于玩家完成游戏是没有任何影响的。然而,需要玩家渡河时,河中的每一块石头的精确位置则更为关键。一个视频生成模型可能会试着同时建模游戏中的云朵和石头位置,但是人类,以及VPT模型则会关注石头的位置本身,忽略云朵的存在。
关注模型“学习到的行动”本身,对于将模型应用在下游任务上更为重要。论文中[4]提到:
“VPT甚至可能是一种更好的通用表示学习方法,可以在没有学习过的下游任务中采取行动——例如,通过微调,让模型来解释视频中发生的事情。可以说,在任何给定场景中,最重要的信息都被能够预测未来人来行动分布的特征所表示了。”
从“指导模型行动”的角度而言,生成视频是没有必要且成本较高的。
3. VPT的启示:AI的进步要站在巨人的肩膀上
问及VPT相比强化学习的优势时,Clune认为,近两年预训练模型的快速发展告诉我们:要提升AI的性能,需要站在巨人的肩膀上(特别是站在巨大人类数据集的“肩膀”上)。传统的强化学习方法需要从头开始让智能体进行探索,对于更为普遍的场景来说,这种做法是困难且低效的。如果有行为先验(Behavioral Priors),对于模型的提升就很大。这不仅适用于NLP和视觉,在机器人领域,这种规律同样使用。
当然,Clune也表示,要将预训练模型和强化学习等方法结合,其面临的挑战和NLP等类似——模型的规模会变得很大,训练成本也较高,特别是在获得和存储高质量的数据方面成本也很高。同时,模型有可能从数据中学习到人们并不希望获得的东西,比如偏见。
而在机器人领域,Clune指出了一个领域独有的挑战:运行模拟器的代价十分高昂,对于机器人来说,要让预训练模型得到应用,需要跨越模拟和现实之间的鸿沟。
AI-GAs:摆脱手工“计划”,让AI自己产生“伟大”,通向通用智能的另一条道路?
1. 难以穷尽的模块与构建方式,人类手工方法已面临困难
最近一段时间,关于AGI路线的讨论更加激烈。在通用智能这个话题上,Clune则认为,最快通向人类级别的AI,方法很有可能是通过AI生成的算法(AI-Generating Algorithms, AI-GAs),而机器学习就是创造强有力AI的重要途径。
在2020年的论文中[5],Clune总结了两种构建AI的方式。
第一种是手工方法,通过两个阶段的达成。在第一阶段,人们需要探究构建智能需要的各种模块组件。
在第二阶段,人们通过各种方法,将这些模块组装成一个复杂的智能系统。这种模式为目前大多数机器学习研究所采用。
然而,Clune认为,这种方法实现智能非常困难。首先,人们需要花费大量的时间精力,探索能够实现智能的模块。这种智能模块几乎层出不穷,人们似乎无法穷尽其种类和形式。

Clune在论文中列举的研究者已经提出的很多构建智能系统的模块
(图片来源:AI-GAs论文[5])
即使人类能够找到各种有效的AI组件,构建智能的工作也远未完成,论文[5]指出:组合模块的方式非常多样,人们需要找到那种最为正确的组合方法;而组件之间会有很多非线性的交互效应,这使得了解整个系统的性能,以及对其进行调试变得非常困难;当构建拥有几十甚至上百的组件时,其面临复杂的科学和工程挑战。我们很难了解单个模块对于整个AI智能能力带来的影响,更不用说不同的组合和配置所带来的影响了。
此外,Clune还批判了构建大规模智能系统所需要的研究模式。传统的科研方式是由一个小团队完成研究工作。而大型的工程团队——类似阿波罗登月计划的团队,会将组织被单一大型项目“绑定”。
2. AI-GAs:三大支柱建立更自然的AI构建方式
考虑到第一种路径所带来的诸多问题。Clune提出了另一种实现人类能力AI的方法——让AI生成算法。其主要思路是让AI学习尽可能多的自动化方法,自动生成能够运行和适应环境的新算法,并不断迭代进化。回顾AI的发展历史,人类本质上也是这样构建AI的:从手工设计AI的系统架构,到手工编码一些组件后让机器去进行学习(通过梯度下降进行拟合)[5],最后应当发展到让AI自己去生成代码并进行学习。
这种方法设定的目标是让AI自己去学习提升其通用能力的方法,这需要AI具备发现、精炼和组合单独的智能机器中的组件的方法,这种手段是人类目前无法完成,但机器可以持续提升、改进的方法。[5]
AI-GAs也是自然界中智能生命进化方法。在达尔文进化论中,一种并不智能的算法就是让生命和环境相适应,然后通过大规模简单复制的方法进行迭代。这种模式到最后,终于形成了人类的意识。可以说,达尔文进化方法就是第一个通用智能生成算法。
Clune认为,要实现AI-GAs,需要三大支柱支撑。一是对架构进行元学习(Meta-learning the Architectures),二是对于学习算法的元学习(Meta-learning the Learning Algorithms Themselves);三是自动生成让AI进行挑战和学习的环境(Automatically Generating the Learning Challenges and Environments)。尽管前两者在过去数十年的时间中有了很多研究进展,但对于第三大支柱的探究还十分少见。[5]
当前AI的训练方式以人类提供合适的数据集为主。但如果要让AI自己能够进行学习,则需要为其设置适合学习的环境,而不仅仅是喂给模型一些数据。正如人类在孩童的教育阶段会设置恰当的课程大纲,实现AI的自主学习,就需要引导AI由易向难,按照一定的顺序的方法,学习到足够的知识和技能。AI-GAs论文指出[5],未来将有可能出现专门面向AI设计的“教学大纲”。而研究AI学习的环境,将是未来研究的新疆域,和可能诞生有重大影响力的领域。
Clune表示,他目前已经从OpenAI离职,之后将会更多地陪伴家人,并专注于在UBC和向量学院的研究,包括未来在AI-GAs相关的研究上。读者朋友如果有兴趣,可以观看Clune教授在2022智源大会上的主题报告,并在他的个人网站(JeffClune.com)上阅读相关研究。

参考资料:
[1] Advancing AI: A Conversation with Jeff Clune, Senior Research Manager at Uber: https://eng.uber.com/jeff-clune-interview/
[2] Scientists Report They Have Made Robot That Makes Its Own Robots:
https://www.nytimes.com/2000/08/31/us/scientists-report-they-have-made-robot-that-makes-its-own-robots.html
[3] POET: Endlessly Generating Increasingly Complex and Diverse Learning Environments and their Solutions through the Paired Open-Ended Trailblazer: https://eng.uber.com/poet-open-ended-deep-learning/
[4] Baker, Bowen, et al. "Video PreTraining (VPT): Learning to Act by Watching Unlabeled Online Videos." arXiv preprint arXiv:2206.11795 (2022).
[5] Clune, Jeff. "AI-GAs: AI-generating algorithms, an alternate paradigm for producing general artificial intelligence." arXiv preprint arXiv:1905.10985 (2019).
[6] A Path Towards Autonomous Machine Intelligence: https://openreview.net/pdf?id=BZ5a1r-kVsf
[7] Hod Lipson: https://en.wikipedia.org/wiki/Hod_Lipson
[8] Learning to Play Minecraft with Video PreTraining (VPT): https://openai.com/blog/vpt/
[9] Kenneth Stanley: https://en.wikipedia.org/wiki/Kenneth_Stanley
[10] https://dl.acm.org/doi/abs/10.1145/2078245.2078246
[11] https://link.springer.com/article/10.1007/s10710-007-9028-8
这篇关于独家采访 | 智能源于自发产生而非计划:进化论拥趸,前OpenAI研究经理、UBC大学副教授Jeff Clune...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







