本文主要是介绍SPSSMplus—潜在剖面分析/潜在类别分析的后续分析(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
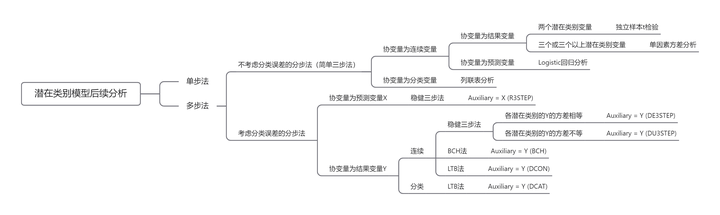
潜在类别模型的后续分析
单步法
多步法
不考虑分类误差的分步法(简单三步法)
方差分析
独立样本t检验
列联表分析
操作方法
考虑分类误差的分步法
Mplus语句
参考文献
思维导图
潜在类别模型的后续分析
潜在剖面分析(Latent Profile Analysis, LPA)/潜在类别分析(Latent Class Analysis, LCA)(统称为潜在类别模型)的后续分析就是纳入协变量(也成为辅助变量,Auxiliary Variable),分析协变量与潜在类别变量之间的关系。
协变量可以充当潜在类别变量的预测变量(Predictor)或者结果变量(Distal Outcome)。
引入协变量的方式可以分为单步法和多步法。
单步法
单步法(One-Step Method)就是直接建立带有协变量的潜在类别模型,一次分析就获得潜在类别分组、潜在类别变量与协变量关系的信息。
例如:想要探究不同性别的青少年攻击行为类型是否存在显著差异,可将性别直接纳入潜在类别模型中,一次建模就可获得攻击行为的潜在类别和不同攻击类别组的性别差异情况。
但单步法存在实际操作性差、建模困难等缺陷,因此不推荐使用。
多步法
单步法是一次就获得所有信息,多步法,显而易见,需要通过一些步骤才能得到潜在类别分组、潜在类别变量与协变量关系的信息。
那分为几步呢?
分为三步:
-
构建潜在类别模型:不纳入协变量,只是根据观测指标/外显变量,构建潜在类别模型。
-
得到潜在类别变量:通过模型比较,确定最佳分类个数和潜在类别模型。
-
纳入协变量分析。
构建潜在类别模型和得到潜在类别变量这两步的具体操作方法,可点击下方链接查看。
Mplus—潜在剖面分析(Latent Profile Analysis, LPA)_Kunle~的博客-CSDN博客![]() https://blog.csdn.net/m0_54401011/article/details/132917597?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_54401011/article/details/132917597?spm=1001.2014.3001.5501
Mplus—潜在类别分析(Latent Class Analysis, LCA)-CSDN博客![]() https://blog.csdn.net/m0_54401011/article/details/132918545?spm=1001.2014.3001.5501
https://blog.csdn.net/m0_54401011/article/details/132918545?spm=1001.2014.3001.5501
因纳入协变量分析这一步不同,分步法被分为不考虑分类误差的分步法和考虑分类误差的分步法。
不考虑分类误差的分步法(简单三步法)
潜在类别模型中,个体在归入潜在类别时并非概率为1,而是归入概率最大的那个类别中。
不考虑分类误差,就是将归类概率当作1,相当于将个体的潜在类别当作显在类别进行分析,采用SPSS进行。
由于没有考虑分类误差,因此后续分析结果也会存在一定的误差。
当协变量为连续结果变量时,可通过独立样本t检验或方差分析检验不同类别之间的差异。
当协变量为连续预测变量时,可采用Logistic回归分析。
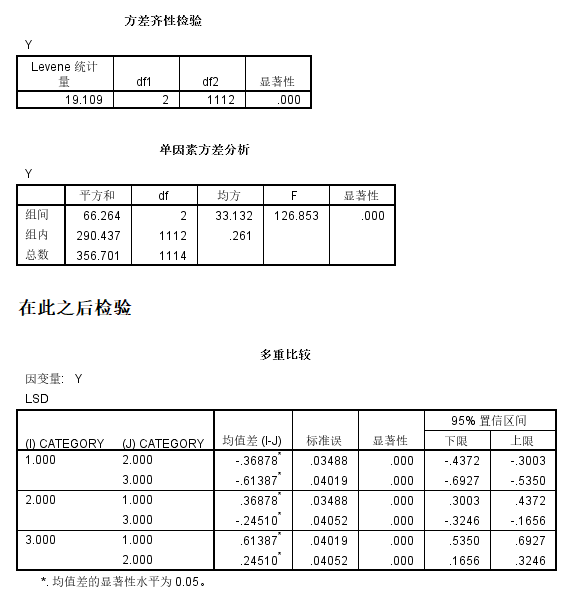
方差分析
当三个或三个以上潜在类别变量时,采用方差分析。
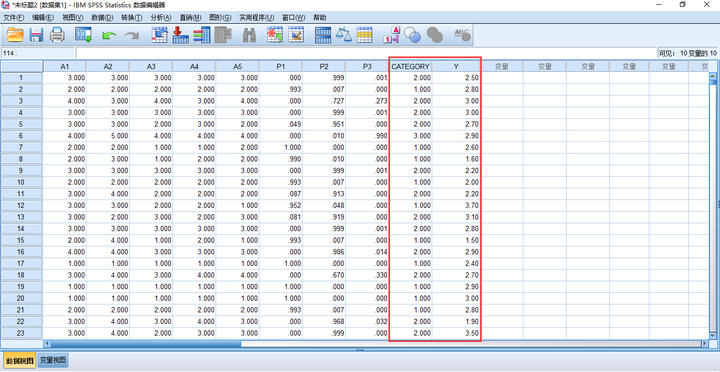
假设以A1-A5这5个连续观测指标/外显变量进行潜在剖面分析,发现三分类模型各项指标最佳,在此基础上,纳入连续结果变量Y进行方差分析。
在进行潜在剖面分析时,分类结果通过命令“SAVEDATA”存放在TXT文件中,该文件的最后一列便是个体属于哪一类别的结果,将该数据导入SPSS中,同时纳入每个个体连续变量Y的数据。依照单因素方差分析的操作方法(下方链接)进行,即可得这三个类别在Y上是否存在显著差异。
SPSS—单因素方差分析 - 知乎之前的文章分别介绍了SPSS菜单栏中“ 分析”下“比较均值”中的“均值”、“单样本t检验”、“独立样本t检验”和“配对样本t检验”的适用情况与操纵方法等,详细内容可点击下方对应链接查看。Kunle:SPSS—均值Kun…![]() https://zhuanlan.zhihu.com/p/632440866
https://zhuanlan.zhihu.com/p/632440866



独立样本t检验
当两个潜在类别变量时,采用独立样本t检验。
假设以A1-A5这5个连续观测指标/外显变量进行潜在剖面分析,发现二分类模型各项指标最佳,在此基础上,纳入连续结果变量Y进行独立样本t检验。
在进行潜在剖面分析时,分类结果通过命令“SAVEDATA”存放在TXT文件中,该文件的最后一列便是个体属于哪一类别的结果,将该数据导入SPSS中,同时纳入每个个体连续变量Y的数据。依照独立样本t检验的操作方法(下方链接)进行,即可得这两个类别在Y上是否存在显著差异。
SPSS—独立样本t检验 - 知乎上一篇文章介绍“分析”下“比较均值”中的“均值”和“单样本 t检验”的用途、操作方法等。Kunle:SPSS—均值Kunle:SPSS—单样本t检验这篇文章将继续介绍“分析”下“ 比较均值”中的“独立样本t检验”。独立样…![]() https://zhuanlan.zhihu.com/p/631295216
https://zhuanlan.zhihu.com/p/631295216
列联表分析
当协变量为分类变量时,可通过列联表分析其与潜在类别的关系。
假设以A1-A5这5个连续观测指标/外显变量进行潜在剖面分析,发现三分类模型各项指标最佳,在此基础上,纳入分类变量Y进行分析。
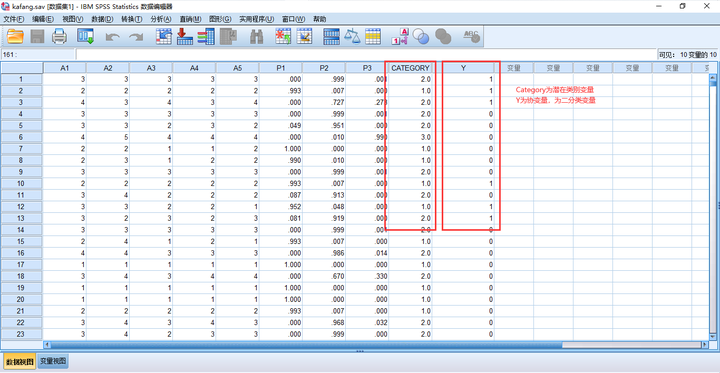
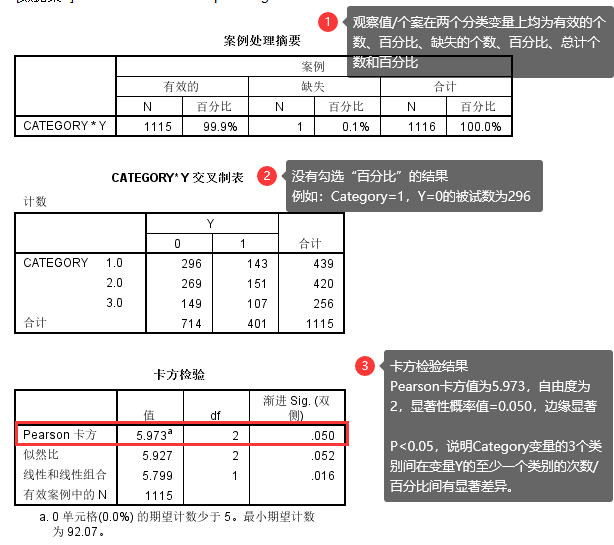
列联表分析是检验两个类别变量所构成的列联表中各单元格的次数或百分比间是否有所差异。
以上述数据为例的列联表如下图所示。
以一个分类变量为行,另一个分类变量为列组成的表格,行列交叉所在单元格存放同时具备行列所对应属性的个体/事物的次数或百分比。列联表分析便是检验具备不同属性个体的次数或百分比是否有所差异。

操作方法
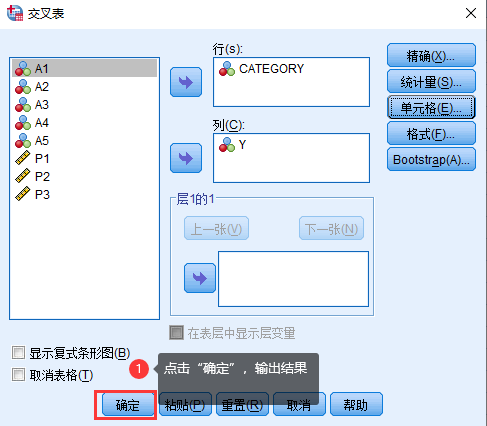
1. 分析>描述统计>交叉表。
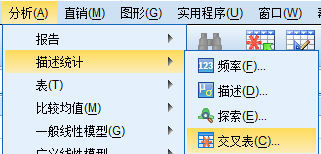
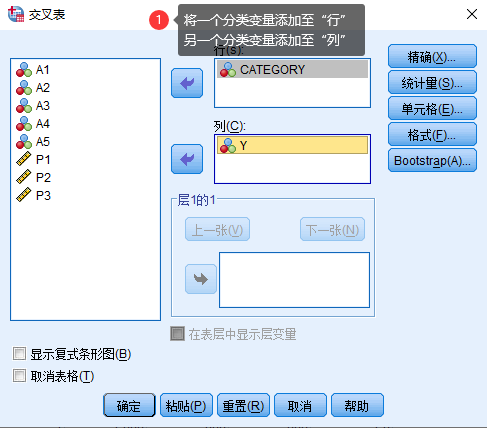
2. 在新出现的对话框中,将一个分类变量添加至“行”,另一个分类变量添加至“列”。
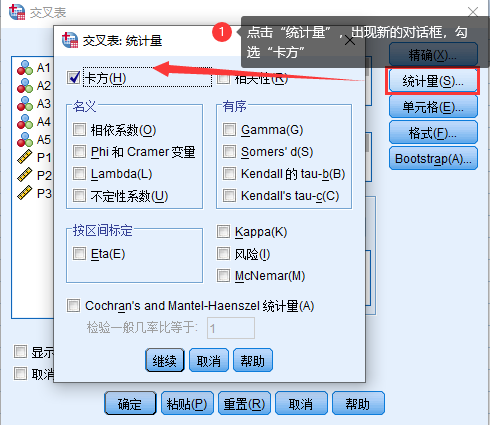
3. 点击“统计量”,出现新的对话框,勾选“卡方”,点击“继续”。
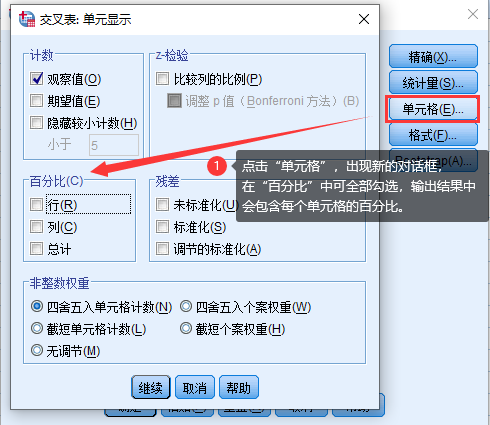
4. 可点击“单元格”,出现新的对话框,在“百分比”中可勾选“行、列、总计”,输出结果中会包含每个单元格的百分比。
5. 点击“确定”,输出结果。
6. 结果解读。
考虑分类误差的分步法
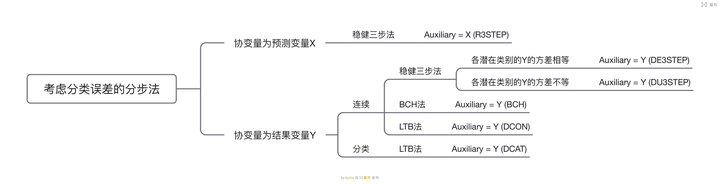
考虑分类误差,即个体在归入潜在类别时带有概率水平,有多种方法,采用Mplus进行。
协变量为预测变量X,由命令“AUXILIARY = X (R3STEP)”来设定。
协变量为连续结果变量Y,有三种方法:
1. 稳健三步法
-
各潜在类别的Y的方差相等时,由命令“AUXILIARY = Y (DE3STEP)”来设定。
-
各潜在类别的Y的方差不等时,由命令“AUXILIARY = Y (DU3STEP)”来设定。
2. BCH法,由命令“AUXILIARY = Y (BCH)”来设定。
3. LTB法,由命令“AUXILIARY = Y (DCON)”来设定。
协变量为分类结果变量Y,采用LTB法,由命令“AUXILIARY = Y (DCAT)”来设定。
Mplus语句
TITLE: This is an example of an LCM;
DATA: FILE IS dataLCM.dat;
VARIABLE: NAME ARE A1-A5 B; ! A1-A5为观测指标,B为协变量
USEVARIABLES ARE A1-A5 B;
MISSING ARE ALL (99); CLASSES = C(3); ! 根据确定的最佳类别数修改此处的数字
CATEGORICAL = A1-A5; ! LCA需要此命令,LPA不需要
AUXILIARY = B (R3STEP/DE3STEP/DU3STEP/BCH/DCON/DCAT); ! 根据协变量是预测变量还是结果变量,是连续变量还是分类变量,选择相应的方法
ANALYSIS: TYPE = MIXTURE;
STARTS = 200 50;
PROCESSOR = 4;
OUTPUT: TECH11 TECH14;
SAVEDATA: FILE = dataLCM.TXT;
SAVE = CPROB;
PLOT: TYPE IS PLOT3;
SERIES = A1-A5 (*);
参考文献
本文内容来源于下面这篇文献,更多内容,大家可自行查看文献。
温忠麟, 谢晋艳, 王惠惠. (2023). 潜在类别模型的原理、步骤及程序. 华东师范大学学报(教育科学版), 41(01), 1-15
希望上述介绍可以帮助到你!也欢迎大家在评论区多多交流分享。
你的关注/点赞 /收藏★/分享,是最大的支持!
这篇关于SPSSMplus—潜在剖面分析/潜在类别分析的后续分析(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




