本文主要是介绍Python-泰坦尼克号生存率预测,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
链接: kaggle算法泰坦尼克号生存率预测.
1. 准备工具
# 导入包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
import warnings#准备前置工作
sns.set(style='darkgrid') #使用画图风格
warnings.filterwarnings('ignore') #忽略警告
%matplotlib inline
2. 读取数据
train_data = pd.read_csv(r'titanic\train.csv')
test_data = pd.read_csv(r'titanic\test.csv')
3. 先观察数据内容
先观察训练集数据:
train_data.head()

- PassengerId:旅客序号,对生存率无影响
- Survived:生存(目标值)(“0”代表死亡,“1”代表生存)
- Pclass:阶层,社会地位 (分为1,2,3阶层,1阶层地位最高)
- Name:旅客姓名
- Sex:性别
- Age:年龄
- SibSp:船上的兄弟姐妹和配偶数量;
- Parch:船上的父母子女数量;
- Ticket:船票
- Fare:票价
- Cabin:船舱
- Embarked:登船点
查看数据基本描述
train_data.describe()

训练集一共有891人,很明显“年龄”存在缺失值,再具体查看哪些特征值还包含缺失值。
train_data.isnull().sum()
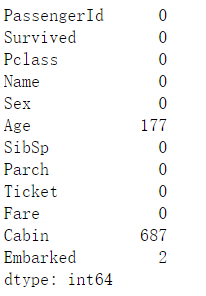
训练集:“Age”缺失177个,“Cabin”缺失687个,“Embarked”缺失2个。由于“Cabin”缺失数量比较多,该特征值难以填补,预测时将会删除。
再看看测试集特征值缺失情况(方便分析中一起填补):
test_data.isnull().sum()
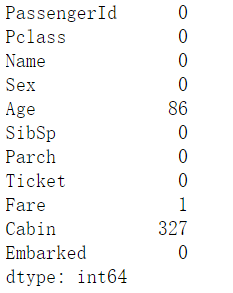
测试集:“Age”缺失86个,“Cabin”缺失327个,“Fare”缺失1个。
4. 观察各特征值因素对生存率的影响
4.1 幸存者总体情况
fig,ax=plt.subplots(1,2,figsize=(16,7))
train_data.Survived.value_counts().plot.pie(explode=[0,0.1],autopct='%1.1f%%',ax=ax[0],shadow=True,fontsize=13)
ax[0].set_title('Survived',fontsize=13)
ax[0].set_ylabel('')
sns.countplot('Survived',data=train_data,ax=ax[1])
ax[1].set_title('Survived',fontsize=13)
for y, x in enumerate(train_data.Survived.value_counts()):plt.text(y, x , x, fontsize=13)
plt.xticks(fontsize=13)
plt.yticks(fontsize=13)
plt.show()

训练集中总人数为891人,其中幸存者342人,占比38.4%,生存率比较低。
4.2 性别因素影响的情况
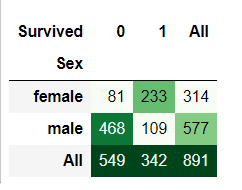
pd.crosstab(train_data['Sex'],train_data['Survived'],margins=True).style.background_gradient(cmap='Greens')
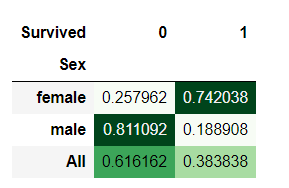
pd.crosstab(train_data['Sex'],train_data['Survived'],normalize=0,margins=True).style.background_gradient(cmap='Greens')
fig,ax = plt.subplots(1,2,figsize=(18,8))
train_data[['Sex','Survived']].groupby(['Sex']).mean().plot.bar(ax=ax[0])
ax[0].set_title('Survived vs Sex',fontsize=13)
sns.countplot('Sex',hue='Survived',data=train_data,ax=ax[1])
ax[1].set_title('Sex:Survived vs Dead',fontsize=13)
plt.show()

登船人数中,女性一共314人,男性577人,女性生存率为74.20%,男性为18.89%,女性生存率远高于男性。该特征值为重要特征值。
4.3 社会地位因素影响的情况
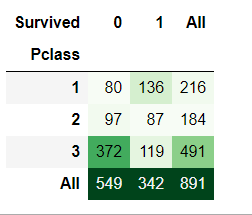
pd.crosstab(train_data['Pclass'],train_data['Survived'],margins=True).style.background_gradient(cmap='Greens')
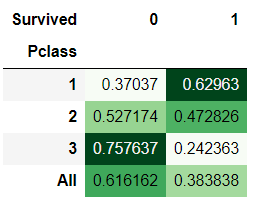
pd.crosstab(train_data['Pclass'],train_data['Survived'],normalize=0,margins=True).style.background_gradient(cmap='Greens')
fig,ax=plt.subplots(1,2,figsize=(18,8))
train_data['Pclass'].value_counts().plot.bar(color=['darkgreen','lightseagreen','skyblue'],ax=ax[0])
ax[0].set_title('Number of Passengers By Pclas',fontsize=13)
ax[0].set_ylabel('Count')
sns.countplot('Pclass',hue='Survived',data=train_data,ax=ax[1])
ax[1].set_title('pclas:Survived vs Dead',fontsize=13)
plt.show()

1阶层生存率最高,约63%;3阶层人数最多,生存率最低,约24%;2阶层比较均衡。特征值为重要特征值。
4.4 性别与社会地位因素共同影响的情况
pd.crosstab([train_data.Sex,train_data.Survived],train_data.Pclass,margins=True).style.background_gradient(cmap='Greens')

sns.factorplot('Pclass','Survived',hue='Sex',data=train_data)
plt.show()

无论处于哪个阶层,女性的生存率始终比男性高,两因素相比,“性别”特征值的重要性大于“阶层”。(女士优先)
4.5 年龄因素影响的情况
年龄存在缺失值,先观察年龄的基本情况。
train_data.Age.describe()
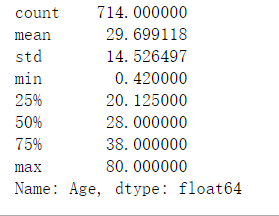
最小值为0.42岁(5个多月?),最大值为80岁。缺失177个数据。
fig,ax=plt.subplots(1,2,figsize=(18,8))
sns.violinplot('Pclass','Age',hue='Survived',data=train_data,split=True,ax=ax[0])
ax[0].set_title('Pclass and Age vs Survived',fontsize=13)
ax[0].set_yticks(range(0,110,10))
sns.violinplot('Sex','Age',hue='Survived',data=train_data,split=True,ax=ax[1])
ax[1].set_title('Sex and Age vs Survived',fontsize=13)
ax[1].set_yticks(range(0,110,10))
plt.show()
这篇关于Python-泰坦尼克号生存率预测的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




