本文主要是介绍记录下如何用RNN 的LSTM 来生成评语吧,python应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 需求分析
- 实现逻辑
- 处理数据:
- 将数据数字化
- 构建训练集
- 构建模型
- x训练模型
- 预测句子方法
- 测试
- 总结:
- 完整代码:
需求分析
我们需要生成一个完整通顺的句子,用来点评书法的课程表现。
如图:
‘爱齐齐,是一个资质非常不错的男孩,多练字让他的手部控笔得到良好的训练,初期顿笔夸张异形也在练字中得到了改正。在小金熊培养出了对书写的兴趣,能够完全静心书写,很少被其他事情影响。让书写成为小齐齐最闪光的优点,一手漂亮的字能更让孩子更自信。相信再经过暑假的集训学习,到了一年级新班小齐齐的书写一定会惊艳全班、、’
实现逻辑
处理数据:

可以看到数据集中有很多垃圾的字符,运用正则去除。
content = re.sub('\[[^\]]*\]|\n', '', content)
- 再运用jieba库将中文分词
seg_list = jieba.cut(content, cut_all= False)str = " ".join(seg_list)
import pandas as pds
import re
from sklearn.feature_extraction.text import CountVectorizer
import jiebadata = pds.read_excel('./comment.xlsx')
arr = []
for content in data.content:char = '\n'list=[i.start() for i in re.finditer(char, content)]if len(list) > 3:content = content[list[2]:]content = re.sub('\[[^\]]*\]|\n', '', content)seg_list = jieba.cut(content, cut_all= False)str = " ".join(seg_list)arr.append(str)- 查看数据

将数据数字化
- 生成语料库:相当于字典
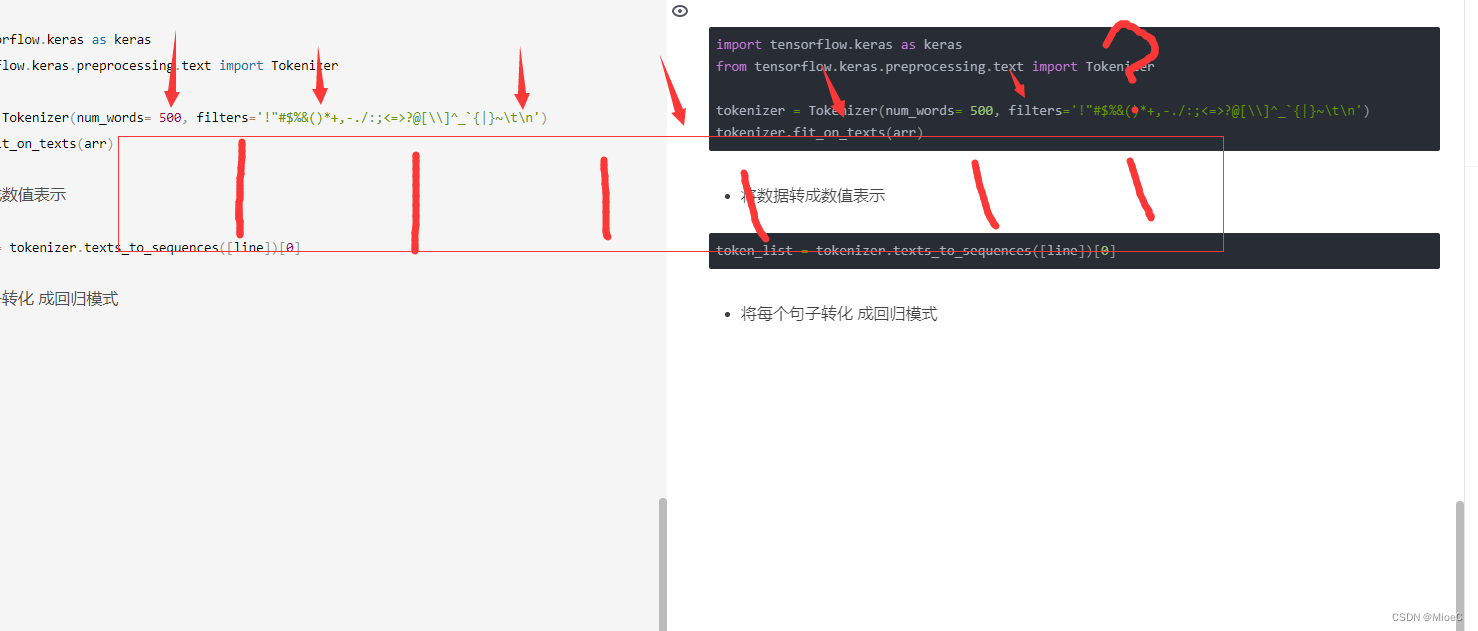
import tensorflow.keras as keras
from tensorflow.keras.preprocessing.text import Tokenizertokenizer = Tokenizer(num_words= 500, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n')
tokenizer.fit_on_texts(arr)
- 将数据转成数值表示
token_list = tokenizer.texts_to_sequences([line])[0]
- 将每个句子转化 成回归模式:所以要把句子转化成
32
12 32
1 12 32
用于训练 - 将数据长度归一化。运用pad_sequences
input_sentences = np.array(pad_sequences(input_sentences, maxlen=max_sentences_len, padding='pre'))
代码:
import numpy as np
from keras.preprocessing.sequence import pad_sequences
input_sentences = []
for line in arr:token_list = tokenizer.texts_to_sequences([line])[0]for i in range(1,len(token_list)):n_pre_sequences = token_list[:i+1]input_sentences.append(n_pre_sequences)
max_sentences_len = max([len(x) for x in input_sentences])
input_sentences = np.array(pad_sequences(input_sentences, maxlen=max_sentences_len, padding='pre'))
input_sentences
构建训练集
xs = input_sentences[:,:-1]
labels = input_sentences[:,-1]
- 将标签转成稀疏矩阵
from tensorflow.keras.utils import to_categorical
ys = to_categorical(labels, num_classes=total_words)
构建模型
model = keras.Sequential()
model.add(keras.layers.Embedding(total_words, 64, input_length=max_sentences_len - 1))
model.add(keras.layers.Bidirectional(keras.layers.LSTM(20)))
model.add(keras.layers.Dense(total_words, activation='softmax'))
model.compile(loss = keras.losses.categorical_crossentropy, optimizer='adam', metrics=['accuracy'])
x训练模型
history = model.fit(xs, ys, epochs=200, verbose=1)
预测句子方法
def pre_text(seed_text, next_words):for _ in range(1, next_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sentences_len - 1, padding='pre')predicted = model.predict(token_list, verbose=0)pre_index = np.argmax(predicted[0])for word, index in tokenizer.word_index.items():if index == pre_index:seed_text += " " +wordbreakreturn seed_text.replace(" ", '')
测试
print(pre_text('宝贝', 100))
pre_text('一学期', 100)

宝贝,是一个资质非常不错的男孩,多练字让他的手部控笔得到良好的训练,初期顿笔夸张异形也在练字中得到了改正。在小金熊培养出了对书写的兴趣,能够完全静心书写,很少被其他事情影响。让书写成为小齐齐最闪光的优点,一手漂亮的字能更让孩子更自信。相信再经过暑假的集训学习,到了一年级新班小齐齐的书写一定会惊艳全班、、。
‘一学期乐乐的进步不是一点点,感谢妈妈的信任与坚持,还记得第一次课一个笔画都歪歪扭扭,现在可以整张冒满泡泡,懿杰也更开心、更自信了建议,趁热打铁,赶紧多练。在我们在小金熊课程每次都开开心心,每次是她的机灵的,让他的。书写基础。书写的很小气、扭扭捏捏到现在字型结构正确、很大气,真的进步不小,熟能生巧,书写速度还有待提升多锻炼手部全班的力量’
总结:
基本功能实现,由于数据太少,所以预测的很多都是重复的,下一步就是收集更多的数据进行训练。
完整代码:
import pandas as pds
import re
from sklearn.feature_extraction.text import CountVectorizer
import jiebadata = pds.read_excel('./comment.xlsx')
arr = []
for content in data.content:char = '\n'list=[i.start() for i in re.finditer(char, content)]if len(list) > 3:content = content[list[2]:]content = re.sub('\[[^\]]*\]|\n', '', content)seg_list = jieba.cut(content, cut_all= False)str = " ".join(seg_list)arr.append(str)import tensorflow.keras as keras
from tensorflow.keras.preprocessing.text import Tokenizertokenizer = Tokenizer(num_words= 500, filters='!"#$%&()*+,-./:;<=>?@[\\]^_`{|}~\t\n')
tokenizer.fit_on_texts(arr)total_words = len(tokenizer.word_index) + 1import numpy as np
from keras.preprocessing.sequence import pad_sequences
input_sentences = []
for line in arr:token_list = tokenizer.texts_to_sequences([line])[0]for i in range(1,len(token_list)):n_pre_sequences = token_list[:i+1]input_sentences.append(n_pre_sequences)
max_sentences_len = max([len(x) for x in input_sentences])
input_sentences = np.array(pad_sequences(input_sentences, maxlen=max_sentences_len, padding='pre'))
input_sentencesxs = input_sentences[:,:-1]
labels = input_sentences[:,-1]from tensorflow.keras.utils import to_categorical
ys = to_categorical(labels, num_classes=total_words)
model = keras.Sequential()
model.add(keras.layers.Embedding(total_words, 64, input_length=max_sentences_len - 1))
model.add(keras.layers.Bidirectional(keras.layers.LSTM(20)))
model.add(keras.layers.Dense(total_words, activation='softmax'))
model.compile(loss = keras.losses.categorical_crossentropy, optimizer='adam', metrics=['accuracy'])history = model.fit(xs, ys, epochs=200, verbose=1)
# def pre_text(seed_text, next_words):for _ in range(1, next_words):token_list = tokenizer.texts_to_sequences([seed_text])[0]token_list = pad_sequences([token_list], maxlen=max_sentences_len - 1, padding='pre')predicted = model.predict(token_list, verbose=0)pre_index = np.argmax(predicted[0])for word, index in tokenizer.word_index.items():if index == pre_index:seed_text += " " +wordbreakreturn seed_text.replace(" ", '')
print(pre_text('宝贝', 100))
pre_text('一学期', 100)
这篇关于记录下如何用RNN 的LSTM 来生成评语吧,python应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





