本文主要是介绍SPSS学习笔记 -- 二维组间方差分析,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
参考书籍:《SPSS其实很简单》
例子:
调查·物理治疗和放松锻炼·对治疗背伤的效果。
其中,物理治疗有两种方式:拉伸锻炼和力量锻炼;
放松锻炼有两种方式:肌肉放松和引导意象。
调查设计:参与调查的24个人分为4组选用以下4种情况的一种:
| 肌肉放松+拉伸 | 引导意象+拉伸 |
|---|---|
| 肌肉放松+力量 | 引导意象+力量 |
研究持续6周,参与者每周定期进行特定的训练。
结束时,每个参与者对当前疼痛水平做出打分:0分表示没伤,60分表示严重背伤。
二维组间方差分析的适用情况:
应用于·两个自变量估计一个连续因变量·的情况。
两个自变量都是·包含两个或是更多水平·的组间因素。
每个参与者只能接受每个因素的一个水平。
二维组间方差分析的假定:
- 观测是独立的;
- 每个单元的因变量总体服从正态分布;
- 每个单元的总体方差相等;
二维组间方差分析的目标:
- 检验主效应:
- ·拉伸和力量锻炼·对背伤的影响有显著差异么?
- ·肌肉放松和引导意象·对背伤的影响有显著差异么?
- 检验交互效应:
- 物理治疗对背伤的影响依赖于放松锻炼的类型么?
二维组间方差分析的数据要求: - 自变量:·具有两个或以上水平·的组间因素;
- 因变量:连续
在这里,自变量为物理治疗和放松锻炼(两因素各有两个水平),因变量为六周后的疼痛水平。
二维组间方差分析的原假设和备择假设:
检验三个不同的原假设。主效应检验:检验每个自变量对因变量的影响是否显著(这里,有物理治疗和放松锻炼两个自变量,故需要2次);
交互效应检验:检验两个自变量的混合效应对因变量的影响是否显著。
假设1:物理治疗检验
原假设:拉伸和力量锻炼带来的平均疼痛水平在总体上是一样的。
假设2:放松锻炼检验
原假设:肌肉放松和引导意象 带来的平均疼痛水平在总体上是一样的。
假设3 : 物理治疗和放松锻炼 交互效应的检验
原假设:物理治疗和放松锻炼 这两个自变量没有交互效应。 - 如果检验产生的结果在原假设正确时看起来不可能(结果发生的可能性小于5%),则拒绝原假设。
- 如果检验产生的结果在原假设正确时看起来是正确的(结果发生的可能性大于5%),则接受不拒绝原假设。
数据处理:


第一行记录表示:参与者1进行的物理治疗是拉伸(1),放松锻炼是肌肉放松(1),最终对当前疼痛的打分是30分。
-在二维组间方差分析中,在SPSS中的每一列表示 一个因素(在这一列中可以使用“1”,“2”等表示不同的水平)。
操作:
把自变量phyther 和 relax 的变量类型调成分类变量。
【分析(analysis)】–【一般线性模型(general linear model)】–【单变量(univariate)】;
在单变量对话框中,因变量为pain,自变量为phyther和relax(设置为固定因子)。

设置【EM平均值】:即设置估算边际平均值,选中·两个自变量和一个交互·点击箭头,拉入“显示下列各项的平均值”的框中,展示如下:

设置【选项(options)】:选中显示【描述统计(descriptive statistics)】、【齐性检验(homogeneity tests)】、【效应量估算(estimates of effect size)】;
设置【图(plots)】:选择phyther移到·horizontal axis·框中;选择relax移入·separate lines·框中;点击“添加”–交互效应phyther*relax显示在plots
对话框中;
【确定】–关闭单变量对话框;
此外,还可以生成一个条形图,用来代替显示交互效应的轮廓图(profile plot).(在上面的操作中,勾选条形图,应该也会生成,这里只是为了熟悉广泛的绘图操作)
在【数据视图】的菜单栏里,【图形】-【旧对话框】-【条形图】;
其中,个案组的摘要:summaries as groups of cases

类别轴:category axis;
聚类定义依据:define clusters by
【确定】,即可显示出条形图,如下:

结果解释:
- 表一:组间因素(between-subjects factos)、主体间因子
显示研究的所有因素(自变量),每个因素的水平数目,变量值标签,变量每个水平的样本量。

- 表二:描述统计量(descriptive statistics)
显示研究中每种情况(每个因素的每个水平)的均值、标准差和样本量。

- 表三:误差方差齐性Levene检验(Levene’s test of equality of error variances)
对研究中的四个单元(情况)的方差是否相等提供了检验,这是二位组间方差分析的一个假设。
Levene检验的原假设为
H 0 : σ 1 , 1 2 = σ 1 , 2 2 = σ 2 , 2 2 H_{0}:\sigma_{1,1}^{2}=\sigma_{1,2}^{2}=\sigma_{2,2}^{2} H0:σ1,12=σ1,22=σ2,22(四个单元的方差总体相等)
H 1 : 至 少 有 一 个 方 差 与 其 他 不 等 H_{1}:至少有一个方差与其他不等 H1:至少有一个方差与其他不等
检查p-值评价方差相等假设。
如果p<=0.05,拒绝原假设,认为四个总体方差不等;
如果p>0.05,不拒绝原假设,假设研究中的四个单元方差相等。

Levene检验得到F值为1.238,p-值为0.322>0.05,不能拒绝方差相等的原假设,即假设研究中的四个单元方差相等。 - 组间效应检验(Test of between-subjects effects)
显示主效应(phyther 和 relax)和交互效应(phyther*relax)的结果。
在二维方差分析中,对每个主效应和交互效应进行了独立的F检验。
F检验是两个方差的壁纸,每个方差在输出中表示均方(MS): F = M S . E f f e c t M S . E r r o r F=\frac{MS.Effect}{MS.Error} F=MS.ErrorMS.Effect,其中MS.Effect表示感兴趣检验的均方,MS.Error表示Test of Between-Subjects Effects表中的均方误差值。
示例说明:自变量phyther的MS值为1276.042,MS Error值为30.992,则phyther的F值为1276.042/30.992 = 41.174.
自变量的自由度=水平数-1;
误差的自由度 = 总样本量 - 研究中的单元数目;

·phyther·的p-值小于0.001,拒绝原假设,即拉伸和力量锻炼对背伤的影响是显著不同的。
·relax·的p-值小于0.001,拒绝原假设,即肌肉放松和引导意象对背伤的影响是显著不同的。
·phyther*relax·检验,自由度 = (phyther的水平数-1)*(relax的水平数-1),F=301.042/30.992=9.714,且交互检验的p-值为0.005(<0.05),拒绝原假设,即·phyther·和·relax·有显著的交互效应。 - 估计边际均值(Estimated Marginal Means)
均值比纳基表对显著结果的方向性有很好的解释。而,如果检验不显著,任何边际均值之间的差别被认为是处于样本误差,而将不被描述。

在表·phyther·中,显示两种物理锻炼方法的边际均值。由上述分析,我们已经知道了phyther是显著的,而在这张边际均值表中,还可以知道拉伸情况报告的疼痛水平显著低于力量锻炼情况。
在表·relax·,同样地,在已知ralex显著的情况下,肌肉放松情况报告的疼痛水平显著低于引导意象。
边际均值的最后一张表·phyther*relax·显示显著交互效应的均值。主要看均值之差:在物理治疗:拉伸的情况下,肌肉放松 和 引导意象 的带来的疼痛水平之差为16.666分;而在物理治疗:力量 的情况下,肌肉放松 和 引导意象 带来的疼痛水平之差为2.5分;
交互效应即差距(16.666 vs 2.50)存在显著不同。
说明:放松锻炼的差异依赖于物理治疗类型。
肌肉放松 和 拉伸锻炼 一起进行的患者有较低的疼痛水平(是四个单元中最低的)。 - 交互效应的图像显示
可以使用轮廓图、条形图显示交互效应
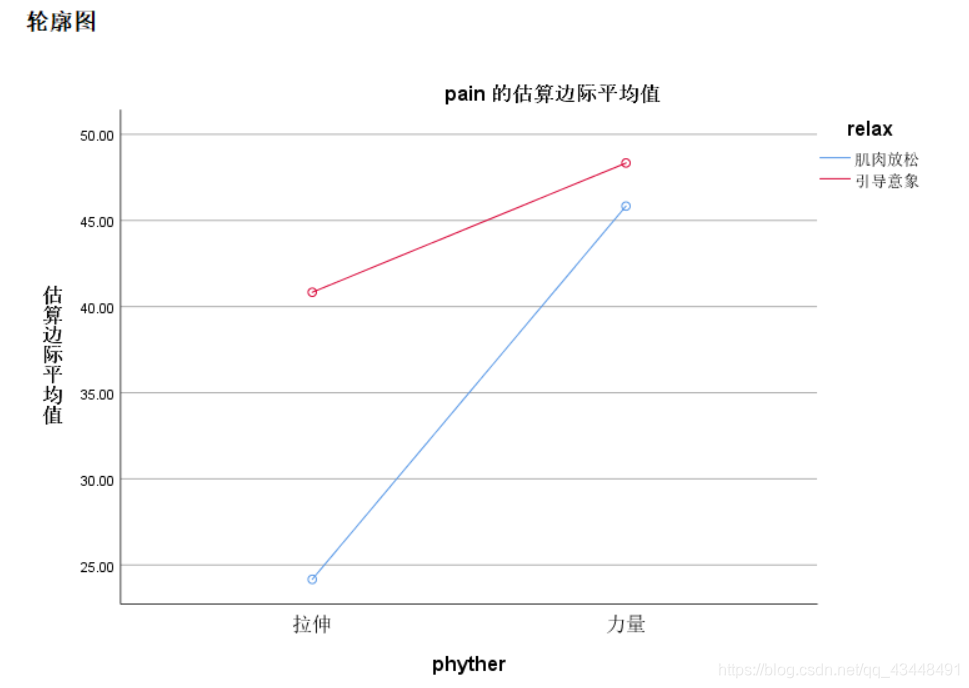
容易看出:在拉伸情况下,肌肉放松和引导意象带来的疼痛水平差别很大;而在力量锻炼的情况下,二者的差异并不很明显。
当对均值作图时,差异导致明显不平行的两条线,这时交互的另一种表现形式。
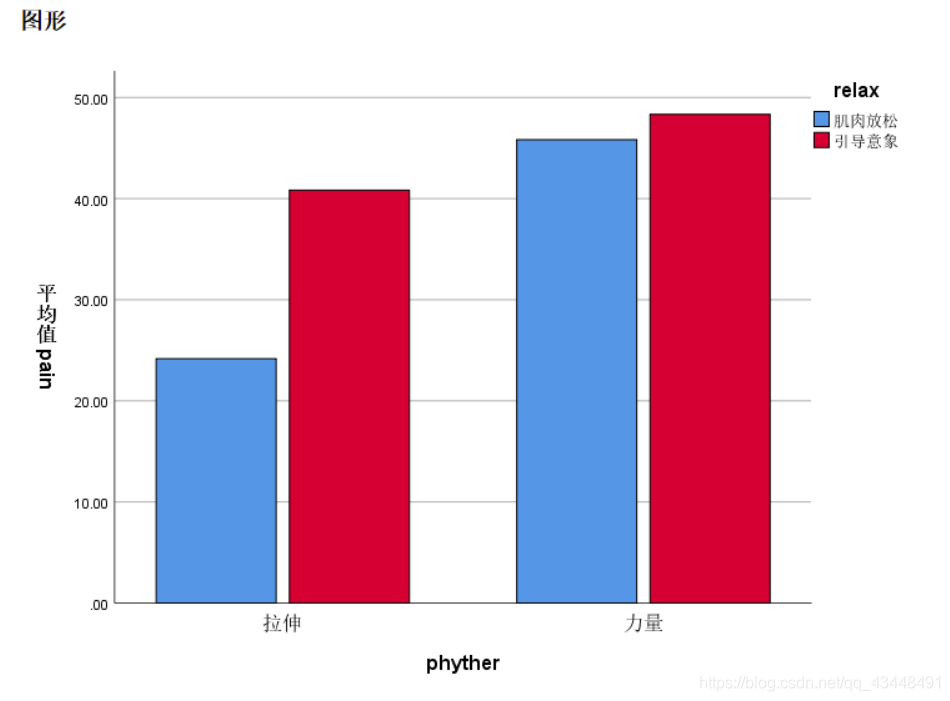
- 轮廓图和条形图应该怎么选择呢?
当至少有一个自变量时区间或是比例变量时,使用轮廓图;
当两个自变量时名义变量时,使用条形图。
- 当交互效应显著时,分析主效应
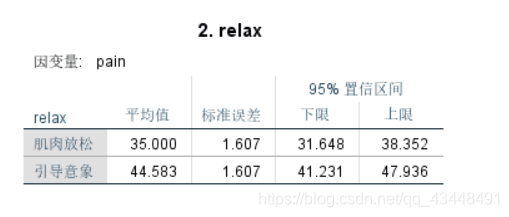
当交互效应是显著时,显著的主效应可能会被误解。
relax的显著主效应说明肌肉放松和引导意象是显著不同的;
relax主效应预测的差,也就是边际均值之差,即44.583-35 = 9.583(也可以通过(16.666+2.5)/2 = 9.583 得到);
但是,对于拉伸锻炼,这个差异大于其主效应预测的值(16.666>9.583);
对于力量锻炼,这个差异小于其主效应预测的值(2.5 < 9.583);
因此,使用主效应描述放松锻炼的差异,会低估了拉伸锻炼的差异,高估了力量锻炼的差异。
如果没有显著的交互效应,主效应将恰当地表现组之间的差异。
效应量:
二维组间方差分析的效应量通常使用偏 η 2 \eta^{2} η2度量。
使用Test of between-subjects effects表中的平方和 S S SS SS:
偏 η 2 = S S E f f e c t S S E f f e c t + S S E r r o r 偏\eta^{2} =\frac{SS_{Effect}}{SS_{Effect}+SS_{Error}} 偏η2=SSEffect+SSErrorSSEffect
其中, S S E f f e c t SS_{Effect} SSEffect对应感兴趣效应的平方和, S S E r r o r SS_{Error} SSError对应误差的平方和。
示例:计算·phyther·的偏 η 2 \eta^{2} η2值为 1276.04 1276.04 + 619.83 = 0.67 \frac{1276.04}{1276.04+619.83} =0.67 1276.04+619.831276.04=0.67.
该值的取值范围是0~1,值越大,表示因变量的方差被效应解释得越多。
APA格式结果表达:



这篇关于SPSS学习笔记 -- 二维组间方差分析的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






