本文主要是介绍足球公平盘、实力盘和盘口合理性的模型探讨,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 公平盘模型事件
9月份,突然间好多人加我vx问及公平盘模型能否依靠下图做出来,几年没有人提及公平盘,突然好多人这么一问应该是从同一个讨论群过来的。
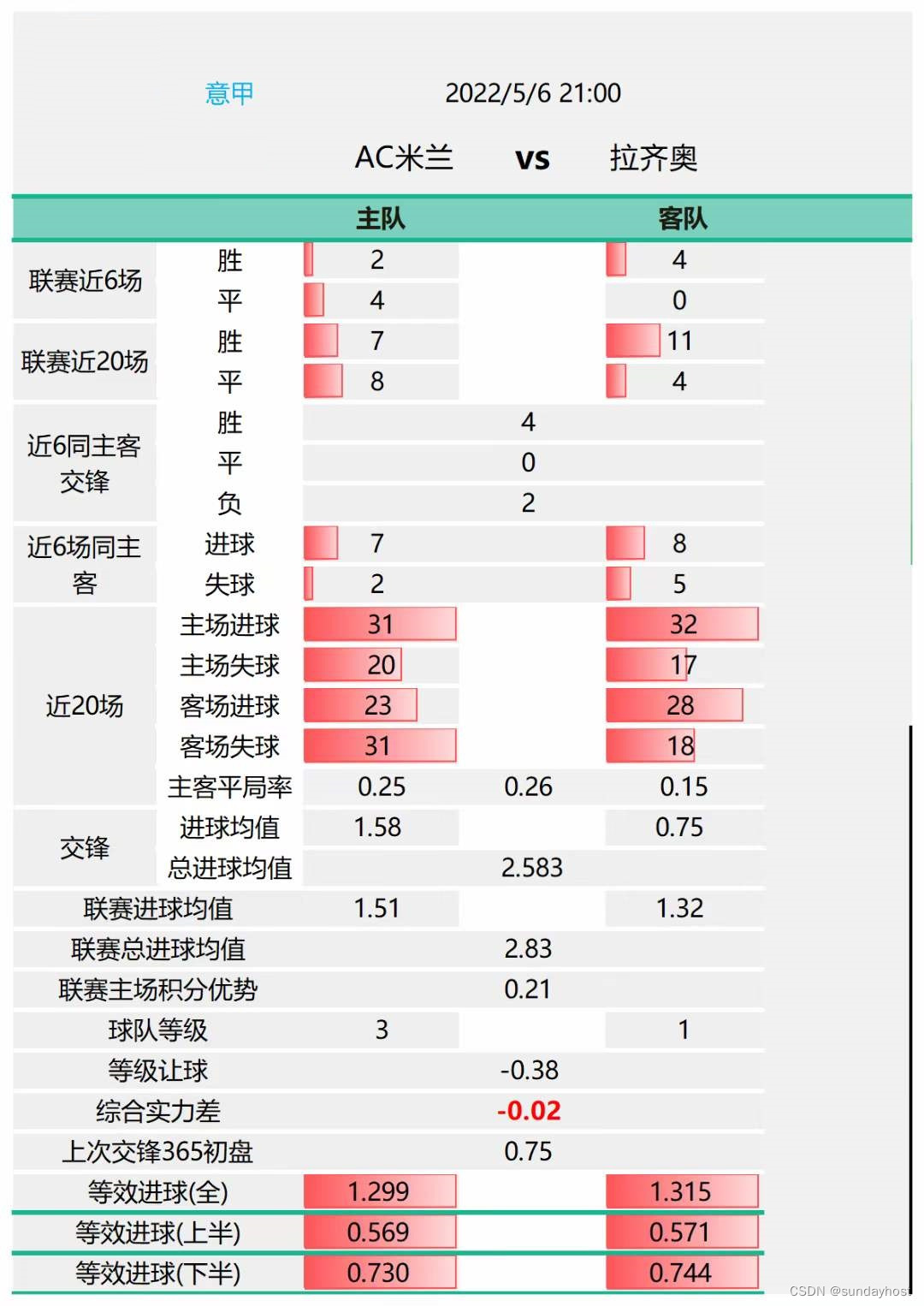
1.1 公平盘介绍
按照字面意思:真实反应即将开赛的两支球队在主客场时的让球盘口,又叫实力盘。
1.2 公平盘应用
利用模型计算出一场比赛的公平盘盘口与公司开出的盘口进行比较,相对应的差异行内叫做深盘、浅盘和一致。当盘口不一致时,可能出现冷门的概率大(ps:以上是网络上的总结,能吸引到一部分群体的研究,结果对不对先不讨论)
2. 公平盘模型和个人观点
根绝表图的指标,此类模型的思路比较简单,按照常见技术统计数据最有效的方法就是回归模型,线性回归(Linear Regresssion)或非线性回归(NonLinear Regresssion)。
机器学习中,线性回归是一种用于建立自变量与因变量之间线性关系的回归分析方法,通过最小化残差平方和来估计自变量与因变量之间的线性关系。而非线性回归是一种用于建立自变量与因变量之间非线性关系的回归分析方法,通过拟合非线性函数来估计自变量与因变量之间的关系。
考虑到足球比赛不同赛事的巨大差异,球队之间的进球数、胜负关系的稳定性差异很大。比如:某个联赛或杯赛,主客场优势不分、进球数时而0~1球,时而2~3球,时而又5+球。故采用非线性回归模型较好。运用时非线性回归时,参数估计通常使用最小二乘法或者最大似然法来求解,通过最小化的残差平方和或者最大化的似然函数来估计回归系数。
公平盘的研究是否对比赛结果预测有效首先直接说出个人结论:有心里安慰意义但无实际操作意义。
3. 观点依据
公平盘的叫法也好,实力盘的称呼也罢,都不是国内主流的叫法。这类型名字多少有些误导人,感觉不是那么正经。公平盘或者实力盘计算出来也没有一个评判对错的标准,在这种情况下,称呼为“合理性盘口”更客观真实。做模型和算法还是严谨些好。依据上图做出的模型在实际应用中是无效的原因在于:
1. 上图在6年前个人做过类似的,计算出的合理性盘口与公司开出的实际盘口相比较,无论是深盘、浅盘,都有打出盘口的上盘和下盘,这点直接可以否认此类指标用于计算实力盘是有问题的。
2. 自行搜索:国外有输入对阵双方球队给出模拟盘口的网页,其水平(盘口、大小、让球)还不如国内。
3. 上图指标的制定者对实力盘的研究停留在基础认知上,采用的都是基础平均数据。选用近6场数据 / 近20场数据 是人云既云的方式。而影响盘口最大因素是近1、2场数据(比如双方进丢球对盘口的修正 这条重要原因没有考虑)。
4. 国内没有个人和团体 能把握 赛前信息真假、球员信息、教练战术等非数字化指标对比赛走势的影响。
4. 结论
综上所述,研究公平盘只是解决预测问题时能想到的一种方法, 实际上计算出的盘口与公司开出盘口即使有很大的差异,也有许多上盘和下盘的不同结果,它不能作为一种有效判断上下盘方法,至少国内外的个人或小团队做不到。很多时候研究者认为这种方法有效,是因为:当比赛结果按照自己所想打出来时强化了这种方法的正确性,而没按所想打出来时确认为是有些细节没处理好并不是方法自身不足导致。
后期,我将从影响盘口最大因素——近1、2场数据(双方进丢球与盘口的修正 )介绍主流赛事盘口合理性的判断方法。
这篇关于足球公平盘、实力盘和盘口合理性的模型探讨的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








