本文主要是介绍孤立森林学习笔记,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
孤立森林学习笔记
前言
「孤立森林」是一种常用于检测异常数据的算法,它具有线性时间复杂度以及较优的性能。作为一种「无监督」的算法,它在深度学习泛滥的今天,仍有着较好的表现。
算法简介
separating an instance from the rest of the instances
作为一种异常检测算法,我们希望的就是在一些正常的数据中,找到那些异常值。
可以预见的是,我们想要找到的这些异常数据点在某种程度上应该是「孤立的」,否则大量聚集的孤立点本身就不能称之为孤立,而应该是属于正常值,异常点本身就是 「few and different」,这也正是算法实现的基础。
回到算法本身,孤立森林的基本思想也很简单:不断地对一个数据集进行随机二分,直到所有数据点都变成孤立的,或者数到达了指定高度。
In a data-induced random tree, partitioning of instances are repeated recursively until all instances are isolated.
你可以把他理解成一颗二叉树,数据经过不断划分,最后每一个节点中都只剩下一个值。

网上也有例子把孤立森林比喻成切蛋糕,随机切蛋糕,切一次可以生成两个子空间,以此循环下去,直到每子空间里面只包含一个数据点为止。
可以想象的是,在随机划分的过程中,孤立点容易被更早的划分出去;对于那些密集的点,往往可能到最后才划分完成。在上面的图中,对于 a, b, c, d 四个数据点,d 最早被划分出去,那么它是孤立点的可能性也就最大。
当然,一棵树肯定是不够的,我们需要重复上面的过程,生成 t 棵树,对于每一个数据点,计算它在孤立树中的平均高度,以此得到一个最后的分数:
s ( x , n ) = 2 − E ( h ( x ) ) c ( n ) s(x, n) =2^{-\frac{E(h(x))}{c(n)}} s(x,n)=2−c(n)E(h(x))
其中 c(n) 为查找失败的平均长度。
s 越接近 1 越可能为异常数据,离 0 越近越可能是正常点。当大部分数据的 s 为 0.5,则表示数据无异常值。
算法示例
我们可以通过 sklearn 简单的实现孤立森林
>>> from sklearn.ensemble import IsolationForest
>>> X = [[-1.1], [0.3], [0.5], [100]]
>>> clf = IsolationForest(random_state=0).fit(X)
>>> clf.predict([[0.1], [0], [90]])
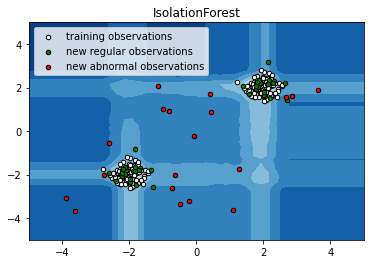
下面是 sklearn 上的一个简单案例:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.ensemble import IsolationForestrng = np.random.RandomState(42)# Generate train data
X = 0.3 * rng.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# Generate some regular novel observations
X = 0.3 * rng.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# Generate some abnormal novel observations
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))# fit the model
clf = IsolationForest(max_samples=100, random_state=rng)
clf.fit(X_train)
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)# plot the line, the samples, and the nearest vectors to the plane
xx, yy = np.meshgrid(np.linspace(-5, 5, 50), np.linspace(-5, 5, 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)plt.title("IsolationForest")
plt.contourf(xx, yy, Z, cmap=plt.cm.Blues_r)b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c='white',s=20, edgecolor='k')
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c='green',s=20, edgecolor='k')
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c='red',s=20, edgecolor='k')
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([b1, b2, c],["training observations","new regular observations", "new abnormal observations"],loc="upper left")
plt.show()
参考文献
- Liu FT, Kai MT, Zhou Z H Isolation Forest: Eighth IEEE International Conference on Data Mining, 2008C
- 【异常检测】孤立森林(Isolation Forest)算法简介
这篇关于孤立森林学习笔记的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







