本文主要是介绍中国年轻人的欠债数据大统计,你的财务健康吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在疫情防控常态化后的首个春节,“就地过年”催生了云上互动、娱乐、消费的大爆发,线上派红包增长近270%。不知道今年过年期间,小伙伴们都收到了多少红包呀?近日有数据显示,有人竟然一天收200多个红包!真是实属令人羡慕呀!我身边有广东的小伙伴跟我吐槽,他过年期间收到的红包,刚好都用来还花呗、信用卡了,红包还没捂热,就都又全给出去了。
以前的老人家曾说道:手中有粮,心中不慌。但当代年轻人好像正一步步摒弃了老一代人的优良传统,根据尼尔森发布的《中国年轻人负债状况报告》,18 到 29 岁的年轻人中,有 86.6% 都在使用信贷产品,也就是说,只有 13.4% 的年轻人零负债。而且在2020年人口分布数据来看,代际人口进入衰减周期,60后全面进入退休周期,有信贷消费观念的90后正慢慢进入家庭生活,未来5-10年,他们将成为家庭的中坚力量。

中国年轻人受到西方“超前消费”的观念影响,与此同时,各大商家的更是经常大力宣传“花明天的钱,圆今天的梦”“梦想难以实现,但它买了就能拥有”等相关诱导性消费观念,年轻人正在慢慢地“透支”自己,这仿佛成为了当代年轻人的生活常态,而市场为了迎合这些具有“超前花费”观念的年轻人,许多借贷产品新鲜出炉,花呗、信用卡、借呗等等产品应声而出。
负债,逐渐成为了一些年轻人生活中不可承受之重。
之前苏宁金融研究院曾通过抽取400万个1980-1999年出生的贷款申请人作为分析样本,80、90后真实负债被揭开,真实的数据将告诉你年轻人的负债情况。
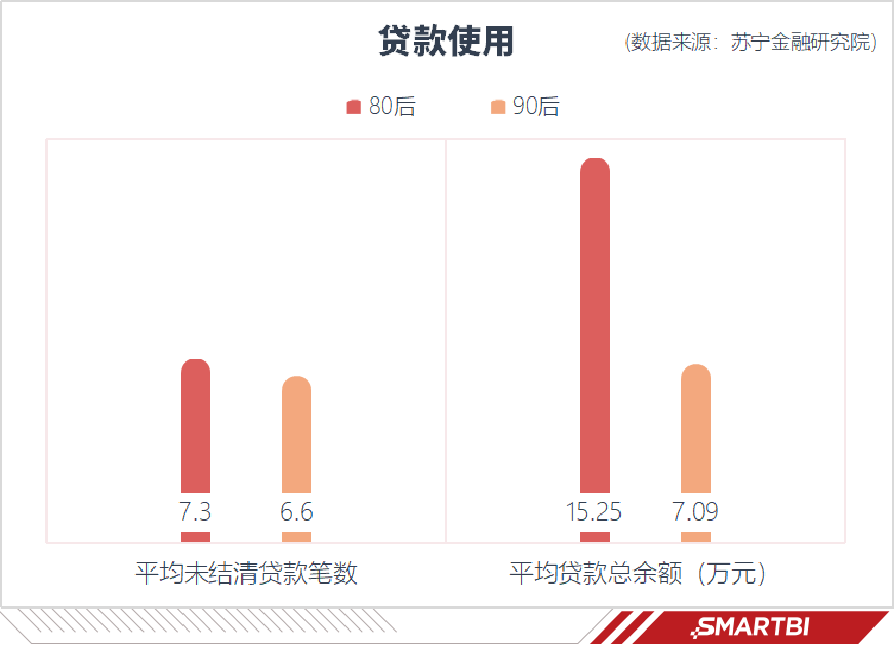
由此可见,年轻人负债已成为现实,“一入网贷深似海,却禁不住诱惑买买买”大家开始开始购买超出能力的商品,再加上支付方式的改变,很多人会感觉花的不是钱,而是数字。同时数据也告诉我们,90后似乎比80后更爱透支信用卡。

相对而言,80后还款压力更大,毕竟大多数80后已经成家立业,身负重担,而90后负债更多是表现在“享乐式”消费,不过当大家没钱还时只能以贷养贷,债务就这样越滚越大。也有数据总结了80、90后的负债情况,可以发现80后欠款金额较高导致其每月还款压力更大,90后在信用卡透支率和违约次数上都要高于80后,但是资金紧张程度不相上下。

不得不说,超前消费正在慢慢摧毁新一代年轻人。当欲望跟不上赚钱的速度,最终等来的唯有被债务压得喘不过气。有意思的是,许多负债的年轻人都有一个共同特征:学历高,挣得也多。

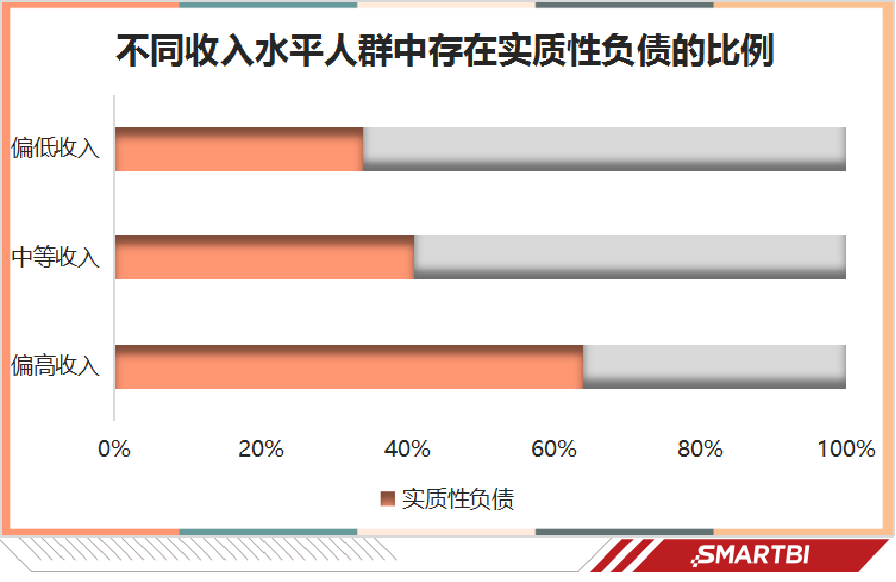
(实质性负债指当月无法还清的债务)
由此可见,年轻人负债已经成为现实,高薪、高知的年轻人负债更多,并不意味着他们是陷入债务危机的主力军,他们有一定的偿还能力,对未来更有信心,也更倾向于负债消费。
负债也并非就是万恶之源,对于贷款的合理利用也是能让部分人可以实现资金价值的最大化的。
但是经过疫情的风浪后,我们要切记,个人应有适当的固定存款也是应该的,学会财务管理也是必须的,有充足的现金流才能让我们在遭受风浪时,有更强大的资金支持。但如果你是一个自控力不足的年轻人,还是趁早还清债务,关闭所有的借贷平台吧!
这篇关于中国年轻人的欠债数据大统计,你的财务健康吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








