本文主要是介绍StoneDB 2.0 调研:架构解析内存引擎详细设计,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
StoneDB 官方介绍:StoneDB 是一款支持行列混存+内存计算的 HTAP 数据库。其采用完全自主研发的存储和计算引擎,可将 MySQL 的分析性能提高100倍;其创新的一体化 HTAP 架构,打破传统 TP 型数据库能力边界,为用户提供一站式 OLTP+OLAP 解决方案。
一句话概括:StoneDB 一体化实时 HTAP 开源数据库。
最近stonedb官方发布了内存引擎详细设计的视频,打算调研一下。
找到了官方发布在b站的视频解说:
StoneDB 2.0 架构解析:内存引擎详细设计(一)_哔哩哔哩_bilibili
StoneDB 2.0 架构:内存引擎设计(二)_哔哩哔哩_bilibili
stonedb的次引擎
在stonedb1.0之中,只支持基于磁盘的列存引擎 Tianmu。同 InnoDB 角色一样,可以作为 MySQL 的另外一个主引擎。在 StoneDB 2.0 版本中,我们将引入 MySQL 8.0.2 中的新特性:次引擎。
StoneDB 2.0 版本中,将推出基于内存计算的列存引擎,该版本将基于 MySQL 8.0 构建,基于此引擎我们将实现 AP 负载的全内存计算。
使用次引擎的原因?
- 次引擎是一个 MySQL 框架,用于提供多引擎的能力。基于通用的接口和框架,MySQL 可以根据每个工作负载的类型将不同的工作负载路由到相应的引擎,发挥其优势以提供优质的服务。次引擎也可以使 MySQL 拥有增强多模能力的机会,例如让 ClickHouse 成为一个次引擎来提供分析服务。
- 逻辑上讲,将子任务路由到次引擎,主任务放到主引擎去执行,比较自然能想到。
- 业内也有一些样例,Oracle 已经将次引擎的特性用在了它们的在线服务中。比如说MySQL HeatWave: 一个内置机器学习的内存查询加速器。
ps:启用 HeatWave能将分析和混合负载的性能提高几个数量级。启用 HeatWave 后,MySQL HeatWave 比 Amazon Redshift 快 6.5 倍,成本只有一半,比 Snowflake 快 7 倍,成本只有五分之一,比 Amazon Aurora 快 1,400 倍,成本只有一半。客户对存储在 MySQL 数据库中的数据进行分析,无需单独的分析数据库和 ETL 复制。
为什么要使用基于内存的列式引擎?
首先从当前分析处理系统存在的一些挑战来讲,好的分析查询性能要满足以下几个要求:
- 了解用户的访问模式
- 提供良好的性能,通常需要创建索引、物化视图和 OLAP 多维数据集。
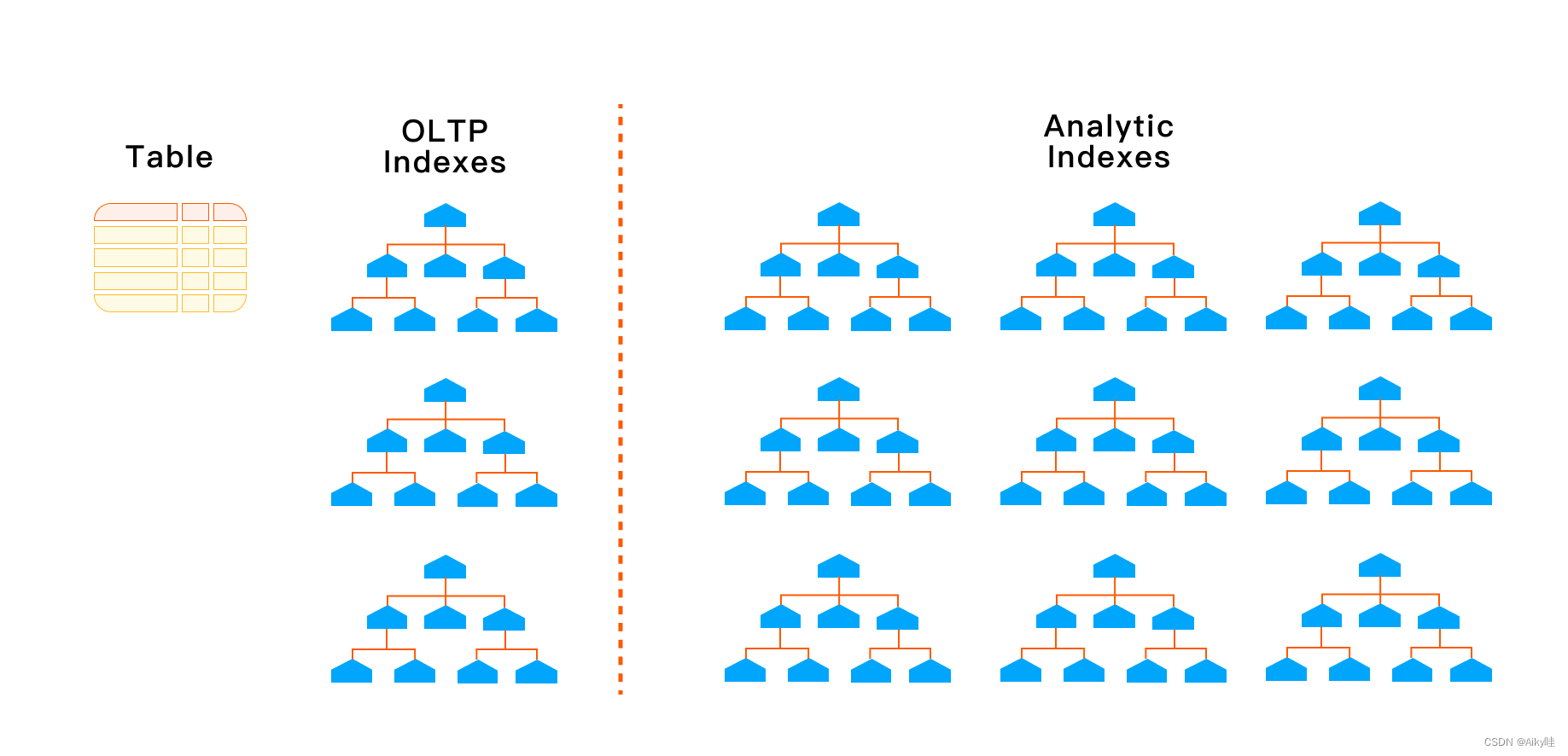
这样比较极端的情况是,对每一列都会创建一个索引,会造成创建索引的空间比表占用空间还要大的一种情况。
为了提升性能,StoneDB 在 1.0 的版本中使用了基于列的数据格式。列式数据格式以列的形式组织数据,而不是行。
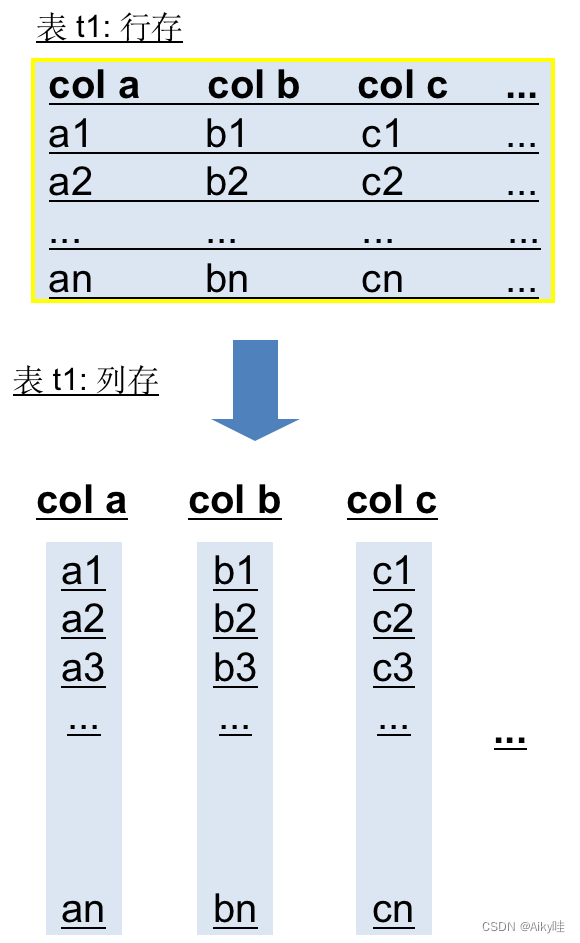
(使用列存的好处大家可以自行搜索,网上的资料非常之多。)
行存和列存没有孰优孰劣之分,在不同的应用场景中会有不同的表现,具体为"增改查"的区别。
- 行存的优势在于写入和修改的效率很高,同时对于每行数据的完整性上具有天生的优势,适用于面向事务型处理的应用场景。
- 列存的优势在于读取的效率很高,并且可以使用高效的压缩算法来节省储存空间,适用于查询密集型的应用场景
大体上来说使用列存在分析型事务中可以更方便呢的过滤多余数据。
那么问题就是:应用程序要么实现快速分析,要么实现快速交易,但不能同时实现两者。混合工作负载数据库的性能问题并不能通过仅以一种单一格式存储数据来解决。
所以stonedb在2.0中引入了新的引擎,即基于内存列的存储,用于分析工作负载。内存中的基于列的引擎也称Tianmu。
stonedb2.0的内存列式引擎Tianmu的概述
数据在加载到基于列的内存引擎之前会被压缩和编码,但是并非所有类型的数据都适合编码和压缩。
官方给出了基于列的内存引擎的一些简单概述:RFC: Architecture of StoneDB V2.0 · Issue #436 · stoneatom/stonedb · GitHub1 Overview of StoneDB V2.0 2 SQL Syntaxes 3 Massive Parallel Processing 3.1 Data Distribution Approaches 3.2 Redistribution Approaches 3.3 Metadata Management 4 Query Engine 5 Execution Engine 6 In-Memory Column-Based Engine 6.1 Memory O... https://github.com/stoneatom/stonedb/issues/436
https://github.com/stoneatom/stonedb/issues/436
也给出了针对于哪些数据类型可以做编码和压缩:https://github.com/stoneatom/stonedb/issues/423![]() https://github.com/stoneatom/stonedb/issues/423
https://github.com/stoneatom/stonedb/issues/423
NUMA & MySQL
Linux kerner: What is NUMA?
NUMA(Non Uniform Memory Access)非一致存储访问结构。

现代cpu是多核,那么核数越多,并发访问竞争越高,要实现内存一致性访问效率就越慢。
NUMA 的内存分配策略有 localalloc、preferred、membind、interleave四种:
- localalloc: 进程从当前 node(比如上图整个处理器一分为二,左边为一个node,右边为一个node) 上请求 alloc memory;
- preferred: 指定一个推荐 node 来获取内存,如果被推荐的 node 上没有足够内存,可以尝试别的 node
- membind: 可以指定若干个 node,进程只能从这些指定的 node 上请求分配内存
- interleave: 进程从指定的若干个 node 上以 Round Robin (轮询调度)算法请求分配内存。
MySQL 在 NUMA 架构上会出现的问题,ref from
Jeremy Cole:https://blog.jcole.us/2010/09/28/mysql-swap-insanity-and-the-numa-architecture/
A brief update on NUMA and MySQL – Jeremy Cole
结论就是,推荐使用 NUMA 内存分配策略为:numactl --interleave=all
因为MySQL 数据库外部请求随机性强,各个线程访问内存在地址上平均分布,Interleave 的内存分配模式相较默认模式可以带来一定程度的性能提升
mysql buffer pool
mysql buffer pool是mysql的innodb自带的一个缓冲池。
(关于buffer pool,网上也有一大堆资料可以看)
InnoDB 缓冲池是数 GB 的范围,内存分布在不同的 NUMA 节点中。
而且,cross-NUMA访问是多核系统的性能瓶颈。因此,NUMA 节点中的内存分配算法(或策略)应谨慎选择。
在 innobase/buf/buf0buf.cc 中,它使用 buf_block_alloc 函数来分配一个缓冲块,并传播到所有 buffer pool 实例。
buf_block_t *buf_block_alloc(buf_pool_t *buf_pool) /*!< in/out: buffer pool instance,or NULL for round-robin selectionof the buffer pool */
{buf_block_t *block;ulint index;static ulint buf_pool_index;if (buf_pool == nullptr) {/* We are allocating memory from any buffer pool, ensurewe spread the grace on all buffer pool instances. */index = buf_pool_index++ % srv_buf_pool_instances;buf_pool = buf_pool_from_array(index);}block = buf_LRU_get_free_block(buf_pool);buf_block_set_state(block, BUF_BLOCK_MEMORY);return (block);
}在redhat中,numa内存分配策略:NUMA memory allocation policies in RedHat.
在 MySQL 中,我们建议在 NUMA 架构中使用 interleave 内存分配策略。结构set_numa_interleave_t 用于将内存分配策略设置为MPOL_INTERLEAVE。
struct set_numa_interleave_t {
// 构造函数set_numa_interleave_t() {if (srv_numa_interleave) {ib::info(ER_IB_MSG_47) << "Setting NUMA memory policy to"" MPOL_INTERLEAVE";struct bitmask *numa_nodes = numa_get_mems_allowed();if (set_mempolicy(MPOL_INTERLEAVE, numa_nodes->maskp, numa_nodes->size) !=0) {ib::warn(ER_IB_MSG_48) << "Failed to set NUMA memory"" policy to MPOL_INTERLEAVE: "<< strerror(errno);}numa_bitmask_free(numa_nodes);}}// 析构函数~set_numa_interleave_t() {if (srv_numa_interleave) {ib::info(ER_IB_MSG_49) << "Setting NUMA memory policy to"" MPOL_DEFAULT";if (set_mempolicy(MPOL_DEFAULT, nullptr, 0) != 0) {ib::warn(ER_IB_MSG_50) << "Failed to set NUMA memory"" policy to MPOL_DEFAULT: "<< strerror(errno);}}}
};一般情况下,在 MySQL 中,会创建多个缓冲池实例,由innodb_buffer_pool_instances控制。缓冲池实例的数量应根据缓冲池的大小进行调整。
对于具有数 GB buffer pool 的系统,将 buffer pool 划分为单独的一个个实例,通过减少不同线程读取和写入缓存页面时的争用来提高并发性。
说白了就是在从空间上减少锁的粒度。
缓冲池大小由 innodb_buffer_pool_size 设置。每个缓冲池实例的大小需要满足:
size_of_an_instance = innodb_buffer_pool_size / innodb_buffer_pool_instances 
缓冲池使用了lru的管理。
tianmu引擎
[RFC] Tianmu In-Memory Column Store Engine · Issue #424 · stoneatom/stonedb · GitHub1 Why do we use seconardy engine? 2 Why do we employ an in-memory column-based engine? 3 Overview of In-memory column-based engine, Tianmu 3.1 MySQL Buffer Pool 3.2 MySQL Change Buffer 3.3 MySQL Log Buffer 3.4 Tianmu In-memory engine 3.4...https://github.com/stoneatom/stonedb/issues/424
tianmu引擎是通过buffer pool划分多个实例来提高并发行的

图中有多个tianmu节点,空白部分是给bufferpool本身使用的。
所以需要确定两个参数,一个是tianmu引擎本身占用的大小TIANMU_IN_MEM_SIZE;另外一个是占用的百分比TIANMU_IN_MEM_SIZE_PCT。
[mysqld]#configure the mem usage of tianmu in-memory engine
TIANMU_IN_MEM_SIZE = 100GB
TIANMU_IN_MEM_SIZE_PCT = 0.6比如说tianmu占用60%,那么剩下的40%是给mysql buffer pool使用的。
tianmu引擎的内存池(Memory pools in Tianmu in-memory)
内存池的结构中,会划分为两个子分池。
一部分用来存储列数据,一部分用来存储元数据。

元数据和列数据一一对应,(就是fields和data的关系)
tianmu内存引擎设计
将会从数据组织和数据加载两个方面来说内存引擎设计这块内容。
1.数据组织
内存布局概述:

- IMCU:The column data subpool will be divided into N partition(known as In-memory column-based unit, IMCU),
- IMCDP : in-memory column-based data pack(IMCDP or abbrv called Chunk or RowGroup).
左边是列数据的缓冲池,用来保存数据本身,
整个内存区会被切分成很多块(IMUC),这里和1.0的实现有所不同,1.0是会对每个列做压缩,2.0中每个列还会切割成多个矩阵,每个矩阵也会有单独的元数据管理。

- DP:datapack

由于dp的header中包含了DP的一些统计信息,比如最大最小值,数量等等,所以可以看做是数据的索引。,可以对DP本身进行过滤。
比如,如果想进行一个sql查询,select * from t where order_id > 100 and order_id < 1000
那么就可以过滤掉IMCDP M的包,留下符合条件的IMCDP N的包。
这样可以很快的过滤出符合条件的数据包。
每个IMCDP(chunk)是由多个列的数据包组合成的,所有的数据块都是驻扎在内存中的。
header部分会包含元数据的信息。


IMCU的纵向拆解图如下:

2.数据加载
使用数据加载, 可以将数据从innodb的行存加载到tianmu的内存列引擎中。

设置的隔离级别是RC 。
innodb(TP)数据更新到stoneDB(AP)的时机有三种情况:
- population Buffer已满
- 设定的时间已到
- 查询负载引用到该项数据
此时会将TP变化数据更新到AP之中:



并且在加载时,不需要进行全量数据的加载,只需要加载需要使用到的列即可。
所以需要可以选择需要哪些列进行加载。

与加载相对应,也会有卸载的方法:

卸载操作也会进行数据的持久化,即刷盘到磁盘之中,这样,之后恢复数据到内存的速度会加快,也会使分层存储系统成为可能。
为了缩短加载时间,stonedb启用了并行加载。利用了mysql8.0的并行扫描功能。

并行使用到的参数是innodb_paraller_read_threads
目前stonedb只给出了存储的组织形式,对于计算引擎如何使用还没有什么资料,大家可以自行看源码。
官网:
StoneDB - A Real-time HTAP Database | StoneDB https://stonedb.io/GitHub - stoneatom/stonedb: StoneDB is an open-source, MySQL HTAP and MySQL-native database for oltp, real-time analyticsStoneDB is an open-source, MySQL HTAP and MySQL-native database for oltp, real-time analytics - GitHub - stoneatom/stonedb: StoneDB is an open-source, MySQL HTAP and MySQL-native database for oltp, real-time analyticshttps://github.com/stoneatom/stonedb
https://stonedb.io/GitHub - stoneatom/stonedb: StoneDB is an open-source, MySQL HTAP and MySQL-native database for oltp, real-time analyticsStoneDB is an open-source, MySQL HTAP and MySQL-native database for oltp, real-time analytics - GitHub - stoneatom/stonedb: StoneDB is an open-source, MySQL HTAP and MySQL-native database for oltp, real-time analyticshttps://github.com/stoneatom/stonedb
这篇关于StoneDB 2.0 调研:架构解析内存引擎详细设计的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





