本文主要是介绍Tensorflow1架构内核和学习方法论,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
概念简介
总体介绍
名词解释
疑问辨析
工程构建
代码生成
技术栈
模型类型
系统架构
分层架构
图控制
运行机制
会话机制
队列
运行模型
本地模式
分布式模式
技能方法论
发现领域模型
挖掘系统架构
细节是魔鬼
适可而止
发现她的美
形式化
独乐乐,不如众乐乐
更新知识
专攻术业
概念简介
总体介绍
TensorFlow的主要作用是构建和训练复杂的机器学习模型,提供高效的并行计算能力,可视化训练过程,支持多种编程语言以及跨平台计算。这些特点使得TensorFlow成为目前炙手可热的深度学习框架之一。
TensorFlow是一个使用数据流图 (Dataflow Graph) 表达数值计算的开源软件库。它使用节点表示抽象的数学计算,并使用 OP 表达计算的逻辑;而边表示节点间传递的数据流, 并使用 Tensor 表达数据的表示。数据流图是一种有向无环图 (DAG),当图中的 OP 按照特定的拓扑排序依次被执行时,Tensor 在图中流动形成数据流,TensorFlow 因此而得名。
名词解释
OP,即Operation,是计算图中的一个节点,代表一个计算单元。在深度学习中,OP可以表示数据流图中的操作,如卷积、池化等。
Kernel , 是 OP 在某种硬件设备的特定实现,它负责执行 OP 的具体运算,
疑问辨析
问:Kernel,又称核函数是不是就是卷积核的意思?
答:Kernel并不等同于卷积核。在计算机视觉和深度学习中,Kernel和卷积核虽然都用于实现某种特定运算,但它们并不完全相同。
Kernel是操作(如卷积、池化等)在某种硬件设备的特定实现,它负责执行操作的具体运算。在深度学习中,每个Kernel对应一个特定的卷积核或权重矩阵。
卷积核则是卷积神经网络中的特定计算单元,它与输入数据在卷积过程中进行特定运算,用于提取输入数据的特定特征。卷积核是一个小型矩阵,它可以遍历输入数据的每个局部区域,并对这些区域进行特定的运算(如点积)。
工程构建
TensorFlow 使用 C++11 语法实现, 所以要保证安装 C++ 编译器要支持 C++11。另外TensorFlow 使用 Bazel 的构建工具, 可以将其视为更高抽象的 Make 工具。不幸的是,Bazel 使用 Java8 实现,其依赖于 JDK。 因此在安装 Bazel 之前,还得需要事先安装 1.8 及以上版本的 JDK。
代码生成
在构建 TensorFlow系统时,Bazel 或 CMake会自动生成部分源代码。理解代码生成器 的输出结果,可以加深理解系统的行为模式。
技术栈

模型类型
在TensorFlow中,可以构建单层感知器模型、多层感知器模型和卷积神经网络模型等。
单层感知器:单层感知器是最简单的神经网络形式,它只有一层神经元,用于对输入数据进行二分类或回归分析。
多层感知器:多层感知器是单层感知器的扩展,它有多层神经元,每层神经元之间相互连接,形成一个层次结构。通过训练,多层感知器可以学习复杂的模式和特征,并用于解决更复杂的分类和回归问题。
卷积网络:卷积网络是一种特殊的神经网络,特别适合处理具有网格结构的数据,如图像。它的基本单元是卷积核或过滤器,这些卷积核可以在输入数据上滑动,并对覆盖区域进行局部连接和计算。卷积网络可以进行特征提取、空间变换、边缘检测等任务,它广泛用于计算机视觉和深度学习中。
系统架构
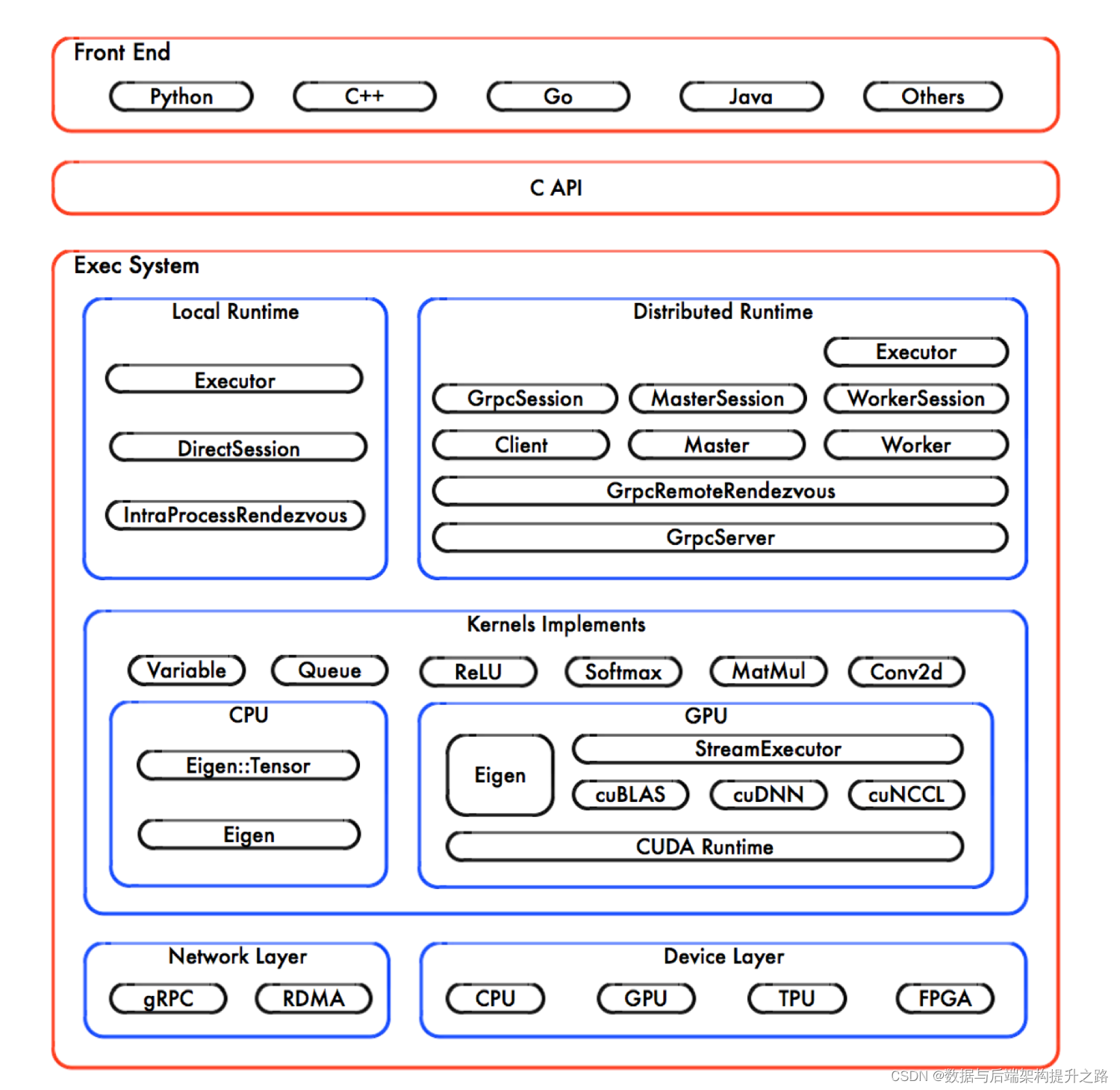
TensorFlow的系统结构以 C API 为界,将整个系统分为前端和后端两个子系统。
1. 前端系统:提供编程模型,负责构造计算图;
2. 后端系统:提供运行时环境,负责执行计算图。
分层架构
TensorFlow的系统设计遵循良好的分层架构,后端系统的设计和实现可以进一步分解为4层。
1. 运行时:分别提供本地模式和分布式模式,并共享大部分设计和实现;
2. 计算层:由各个 OP 的 Kernel 实现组成;在运行时,Kernel 实现执行 OP 的具
体数学运算;
3. 通信层:基于 gRPC 实现组件间的数据交换,并能够在支持 IB 网络的节点间实
现 RDMA 通信;
4. 设备层:计算设备是 OP 执行的主要载体,TensorFlow 支持多种异构的计算设备
类型。
TensorFlow 支持 Python 和 C++ 的编程接口较为完善,尤其对 Python 的 API 支持最为全面。并且,对其他编程语言的 API 支持日益完善。
图控制
在TensorFlow中,图控制包括图构建、图执行和图优化等方面。通过图控制,可以构建复杂的机器学习模型,并实现高效的并行计算和可视化训练过程。
运行机制
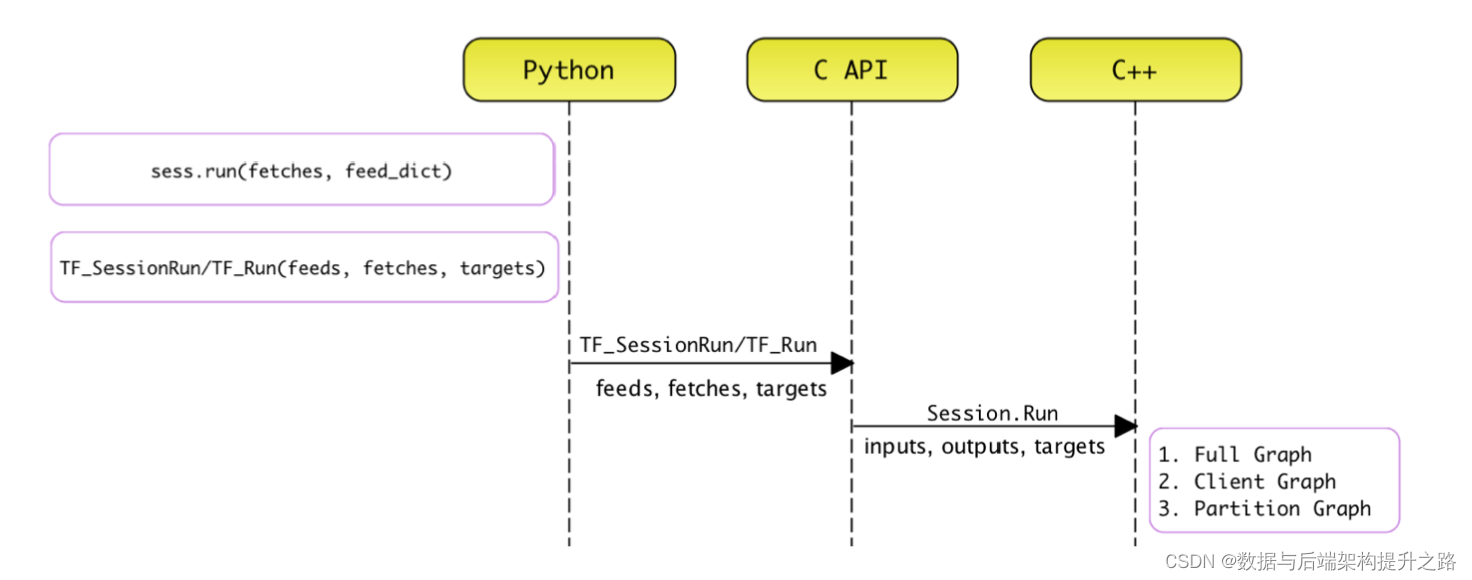
会话机制
TensorFlow的会话(Session)机制是用于实际执行计算图的关键部分。计算图在构建阶段定义了模型的结构和计算关系,而会话则负责在执行阶段将这些计算分配给适当的计算设备(如CPU、GPU或TPU等)并执行它们。
会话的生命周期包括会话的创建,创建计算图,扩展计算图,执行计算图,关闭会话, 销毁会话的基本过程。在前端 Python 和后端 C++ 表现为两套相兼容的接口实现。
队列
队列在模型训练中扮演重要角色,后文将讲述数据加载的 Pipeline,训练模型常常使用 RandomShuffleQueue 为其准备样本数据。为了提高 IO 的吞吐率,可以使用多线程,并发地将样本数据追加到样本队列中;与此同时,训练模型的线程迭代执行 train_op 时,一次获取 batch_size 大小的批次样本数据。显而易见,队列在 Pipeline 过程中扮演了异步协调和数据交换的功能,这给 Pipeline 的设计和实现带来很大的弹性空间。
运行模型
本地模式
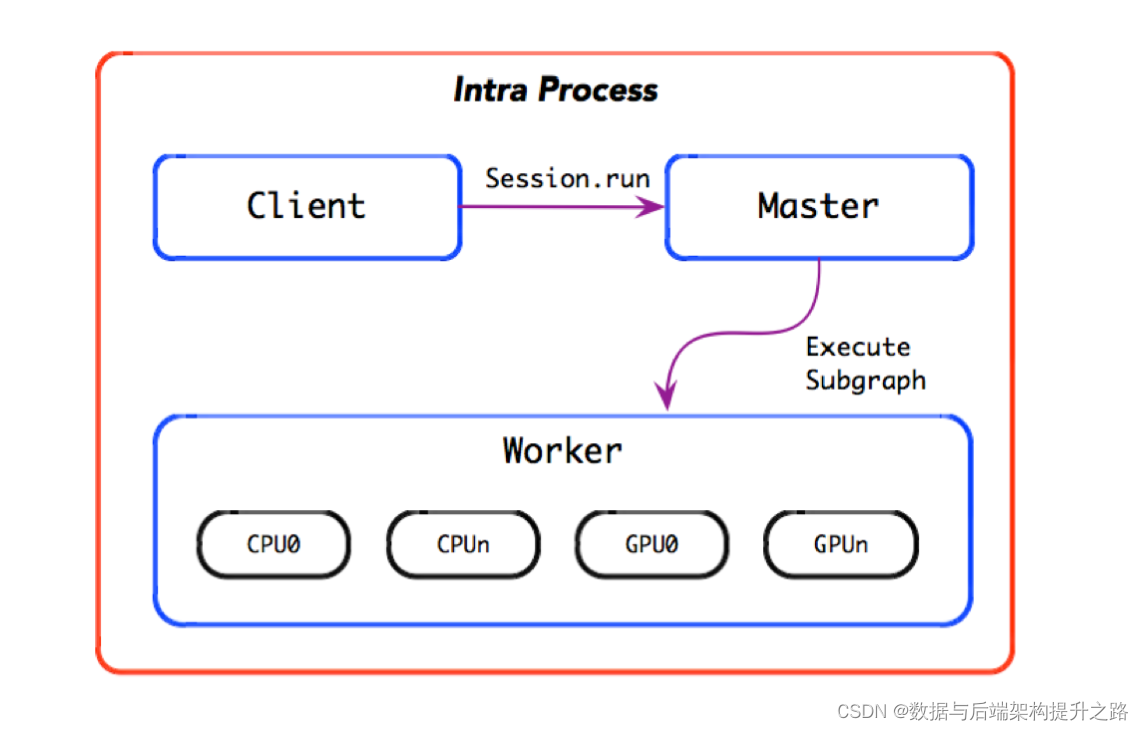

分布式模式


技能方法论
发现领域模型
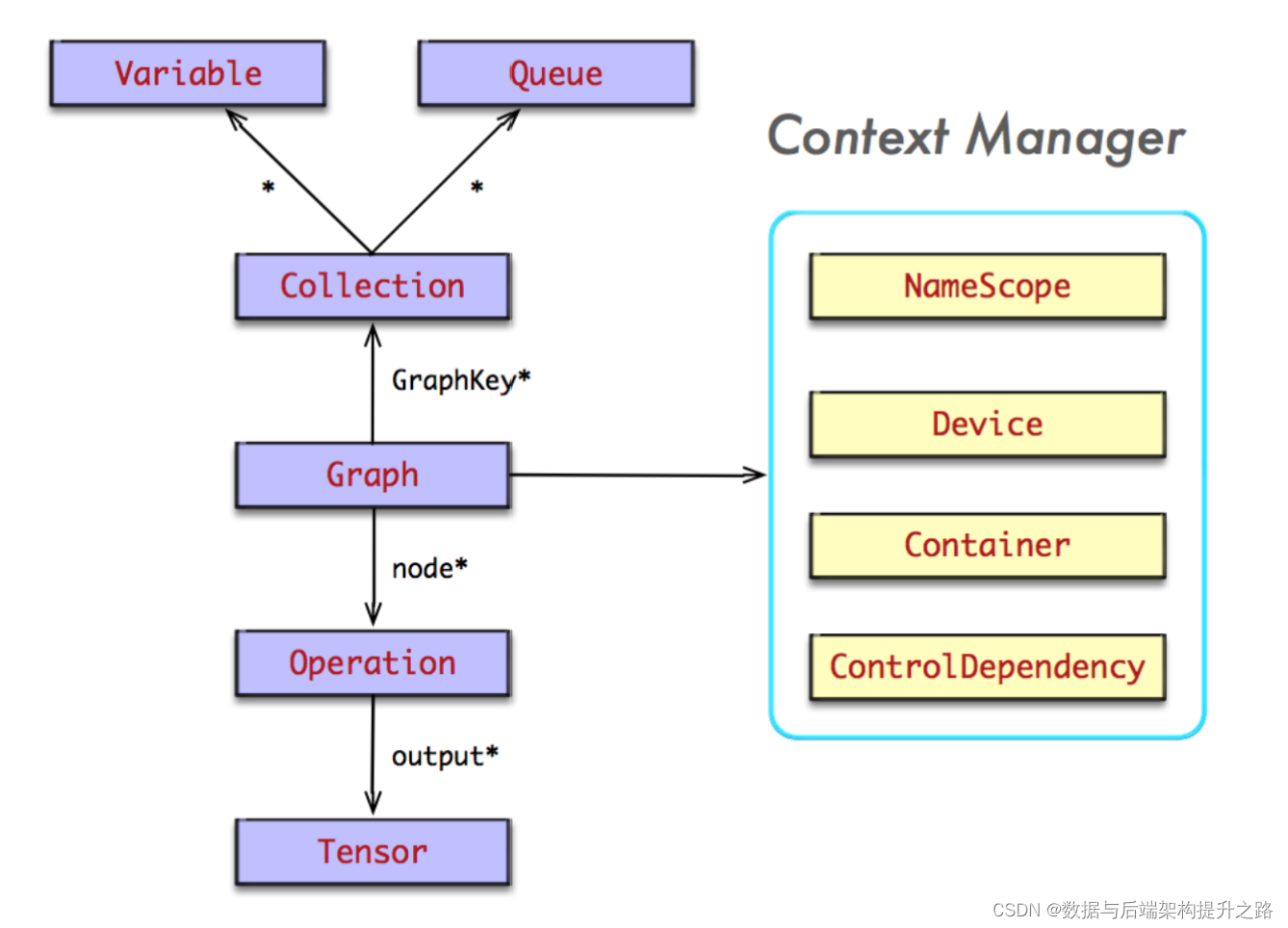
领域模型是阅读代码最重要的一个目标,因为领域模型是系统的灵魂 所在。通过代码阅读,找到系统本质的知识,并通过自己的模式表达出来,才能真正地抓住系统的脉络,否则一切都是空谈。
例如,在阅读 TensorFlow 的 Python 实现的客户端代码时,理顺计算图的领域模型, 对于理解 TensorFlow 的编程模型,及其系统运行时的行为极其重要。
挖掘系统架构
阅读代码犹如在大海中航行,系统架构图就是航海图。阅读代码不能没有整体的系统概念,否则收效不佳,阅读质量大大折扣。必须拥有系统思维,并明确目标。
细节是魔鬼
纠结于细节,将导致代码阅读代码的效率和质量大大折扣。例如,日志打印,解决某个 Bug 的补丁实现,某版本分支的兼容方案,某些变态需求的锤子代码实现等等。
阅读代码的一个常见的反模式就是「给代码做批注」。这是一个高耗低效,投入产出比极低的实践。一般地,越是优雅的系统,注释越少;越是复杂的系统,再多的注释也是于事无补。
适可而止
个人阅读代码的时候,函数调用栈深度绝不超过 3,然后使用抽象的思维方式思考底 层的调用。因为我发现,随着年龄的增长,曾今值得骄傲的记忆力,现在逐渐地变成自己的 短板。当我尝试追踪过深的调用栈之后,之前的阅读信息完全地消失记忆了
发现她的美
当我发现一个好的设计时,我会尝试使用类图,状态机,序列图等方式来表达设计;如果发现潜在的不足,将自己的想法补充进去,将更加完美。
形式化
当阅读代码时,有部分人习惯画程序的「流程图」。相反,我几乎从来不会画「流程图」, 因为流程图反映了太多的实现细节,而不能深刻地反映算法的本质。
我更倾向于使用「形式化」的方式来描述问题。它拥有数学的美感,简洁的表达方式, 及其高度抽象的思维,对挖掘问题本质极其关键。
例如,对于 FizzBuzzWhizz 的问题,相对于冗长的文字描述,或流程图,形式化的方式将更加简单,并富有表达力。以 3, 5, 7 为输入,形式化后描述后,可清晰地挖掘出问题的本质所在。

独乐乐,不如众乐乐
与他人分享你的经验,也许可以找到更多的启发;尤其对于熟知该领域的人沟通,如果是 Owner就更好了,肯定能得到意外的惊喜和收获。
要让别人信服你的观点,关键是要给别人带来信服的理由。分享的同时,能够帮助锻炼自己的表达能力,这需要长时间的刻意练习。
使用图表来总结知识,一方面图的表达力远远大于文字;另外,通过画图也逼迫自己能够透彻问题的本质
更新知识
我们需要常常更新既有的知识体系,尤其我们处在一个知识大爆炸的时代。我痛恨那些信守教条的信徒
专攻术业
人的精力是有限的,一个人不可能掌握住世界上所有的知识。与其在程序设计语言的 抉择上犹豫不决,不如透彻理解方法论的内在本质;与其在众多框架中悬而未决,不如付出实际,着眼于问题本身。总之,博而不精,不可不防
这篇关于Tensorflow1架构内核和学习方法论的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





