本文主要是介绍用python识别照片的主人,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
思路:
一、数据收集,可以采用爬虫对网上海里的明星信息进行有针对的爬取
二、格式化数据,存入mysq,把明星的自拍照的文件名存入数据库中
三、使用百度的api对程序进行编写,说实话,百度人脸识别做的很棒了,精确度很高
四、你上传一张图片(或者你能想象到的方式),后面的程序会对你海量的数据库中人的信息进行比对
五、输出匹配到的人的信息,和相似度的数值。

直接上代码:
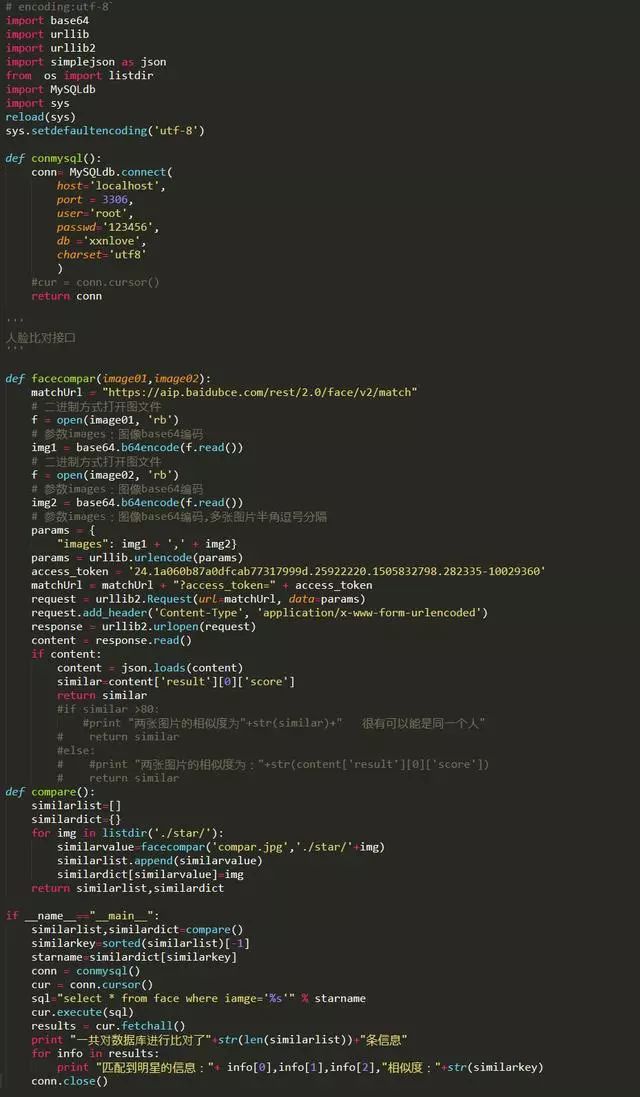
测试图片:

明星数据库:

明星的照片所在目录:

明星照片:





程序运行效果:

一共对数据库进行比对了5条信息
匹配到明星的信息:曾轶可 27 1990年1月3日出生于湖南省常德市汉寿县,创作型女歌手,演员。相似度:63.689125061
数据库:

目录:

项目总结:
人脸比对对照片的有一定要求,因为我爬取的照片大小不规则,所以比对的时候,会有问题,人脸比对用的百度的api接口,感觉关键部分不是自己实现的,正在恶补数据结构和算法。
简介 --静态网站框架hugo
Hugo 是一个用 Go 编写的静态 HTML 和 CSS 网站生成器。它针对速度、易用性和可配置性进行了优化。Hugo 获取包含内容和模板的目录,并将它们呈现为一个完整的 HTML 网站。
Hugo 号称是世界上最快的网站构建框架。

Hugo 依赖于带有元数据前端的 Markdown 文件,可以从任何目录运行 Hugo,以毫秒级别的速度呈现一个中等大小的典型网站,适用于任何类型的网站,包括博客、文档等。
目前,官方为 x64、i386 和 ARM 架构的 Windows、Linux、FreeBSD、NetBSD、DragonFly BSD、Open BSD、macOS (Darwin) 和 Android 提供预构建的 Hugo 二进制文件。也可以在 Go 编译器工具链可以运行的任何地方从源代码编译,例如用于其他操作系统,包括 Plan 9 和 Solaris。
项目地址是:
https://github.com/gohugoio/hugo
特点

-
极致的速度。Hugo 是同类工具中速度最快的,每个页面生成时间小于1毫秒,平均站点构建时间不到1秒。
-
强大的内容管理。Hugo 支持无限的内容类型、菜单、动态 API 驱动的内容等,无需插件。
-
简化的代码。Hugo 的代码既优雅又灵活。
-
内置模板。Hugo 附带了内置模板,可以快速使用 SEO、评论、分析和其他功能,只需一行代码即可完成。
-
支持国际化多语言。
-
自定义输出。Hugo 运行输出多种格式的内容,包括 JSON 或 AMP,并且可以轻松创建自定义的内容。
-
支持 300+ 主题。Hugo 提供了一个强大的主题系统,它易于实现,但能够生产最复杂的网站。
下载安装
在 Mac 上
$ brew install hugo
在 Windows 上
$ choco install hugo -confirm
在 Linux 上
$ snap install hugo
常用命令
-
hugo
hugo, 构建站点的主要命令
-b,--baseURL 字符串主机名(和路径)到根
-D,--buildDrafts 包括标记为草稿的内容
-E,--buildExpired 包括过期的内容
-F,--buildFuture 包含将来发布日期的内容
--cacheDir 字符串文件系统路径到缓存目录
-
hugo check
hugo check,包含一些验证检查选项
-h, --help 帮助
--config 字符串配置文件(默认为 path/config.yaml|json|toml)
--configDir 字符串配置目录(默认为“config” )
--debug 调试输出
-e, --environment 构建环境
--ignoreVendor 忽略任何 _vendor 目录
--ignoreVendorPaths 忽略匹配给定模式的模块路径的任何 _vendor 目录
--log enable Logging --logFile string log 文件路径(如果设置,自动启用日志记录)
--quiet 在安静模式下构建
-
hugo completion
hugo completion,为指定的 shell 生成自动完成脚本
-config 字符串配置文件(默认为 path/config.yaml|json|toml)
--configDir 字符串配置目录(默认“config”)
--debug debug输出
-e, --environment 构建环境
--ignoreVendor 忽略任何 _vendor 目录
--ignoreVendorPaths 忽略匹配给定模式的模块路径的任何 _vendor 目录
--log enable Logging --logFile string log 文件路径(如果设置,启用日志记录)自动)
--quiet 在安静模式下构建
-
hugo config
hugo config,打印站点配置,包括默认和自定义设置
-
hugo convert toJSON
hugo convert toJSON,将内容目录中的所有前端内容转换为使用 JSON
-
hugo deploy
hugo deploy,将站点部署到云提供商
-confirm 在对目标进行更改之前要求确认
--dryRun 运行
--force 强制上传所有文件
-h, --help 部署帮助
--invalidateCDN 使列表中列出的 CDN 缓存失效(默认为 true)
--maxDeletes 要删除的最大文件数,或 -1 禁用(默认为 256)
--target 配置文件中部署部分的目标部署;默认为第一个从父命令继承的选项
--config 配置文件(默认为 path/config.txt)
-
hugo env
hugo env,打印 Hugo 版本和环境信息
这篇关于用python识别照片的主人的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




