本文主要是介绍论文阅读2018:Detecting ICMP Rate Limiting in the Internet,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Detecting ICMP Rate Limiting in the Internet
- 作者
- 知识点
- NACK
- token bucket
- ICMP应用的领域
- 摘要
- 研究点的提出
- 实验
- 限制块的建模
- 测量
- ICMP速率限制的四个阶段
- 实验结果
- 结论
Models and Inference
作者
- Hang Guo
- John Heidemann
知识点
NACK
与NACK对应的是ACK,ACK是到达通知技术。以TCP为例,他可靠因为接收方在收到数据后会给发送方返回一个“已收到数据”的消息(ACK),告诉发送方“我已经收到了”,确保消息的可靠。
NACK也是一种通知技术,只是触发通知的条件刚好的ACK相反,在未收到消息时,通知发送方“我未收到消息”,即通知未达。
token bucket
令牌桶算法是网络流量整形(Traffic Shaping)和速率限制(Rate Limiting)中最常使用的一种算法。 典型情况下,令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。 令牌桶这种控制机制基于令牌桶中是否存在令牌来指示什么时候可以发送流量。
令牌桶算法用来控制发送到网络上的数据的数目,并允许突发数据的发送。
基本过程:
- 假如用户配置的平均发送速率为r,则每隔1/r秒一个令牌被加入到桶中;
- 假设桶最多可以存发b个令牌。如果令牌到达时令牌桶已经满了,那么这个令牌会被丢弃;
- 当一个n个字节的数据包到达时,就从令牌桶中删除n个令牌,并且数据包被发送到网络;
- 如果令牌桶中少于n个令牌,那么不会删除令牌,并且认为这个数据包在流量限制之外;
- 算法允许最长b个字节的突发,但从长期运行结果看,数据包的速率被限制成常量r。对于在流量限制外的数据包可以以不同的方式处理:
- 它们可以被丢弃;
- 它们可以排放在队列中以便当令牌桶中累积了足够多的令牌时再传输;
- 它们可以继续发送,但需要做特殊标记,网络过载的时候将这些特殊标记的包丢弃。
当网络设备衡量流量是否超过额定带宽时,需要查看令牌桶,而令牌桶中会放置一定数量的令牌,一个令牌允许接口发送或接收1bit数据(有时是1
Byty数据),当接口通过1bit数据后,同时也要从桶中移除一个令牌。当桶里没有令牌的时候,任何流量都被视为超过额定带宽,只有当桶中有令牌时,数据才可以通过接口。令牌桶中的令牌不仅仅可以被移除,同样也可以往里添加,所以为了保证接口随时有数据通过,就必须不停地往桶里加令牌,由此可见,往桶里加令牌的速度,就决定了数据通过接口的速度。因此,我们通过控制往令牌桶里加令牌的速度从而控制用户流量的带宽。而设置的这个用户传输数据的速率被称为承诺信息速率(CIR),通常以秒为单位。比如我们设置用户的带宽为1000
bit每秒,只要保证每秒钟往桶里添加1000个令牌即可。
在一秒钟结束后,没有用完的令牌会被全部清空,由下一秒重新加入。
ICMP应用的领域
- Internet address usage
- path performance
- outages
- carrier-grade NAT deployment
- DHCP churn
摘要
ICMP主动探测是许多网络测量的核心。对ICMP流量的速率限制可能如果未被发现,会扭曲测量并产生错误的结论。为解决这一问题,我们系统地研究了互联网中的ICMP速率限制。我们创建了FADER,这是一种新算法,可以用最少的新测量流量识别用户端轨迹的速率限制。我们在测试平台实验中验证了FADER在许多不同网络配置中的准确性,并表明它几乎总能检测到速率限制。有了这种信心,我们将算法应用于整个互联网的随机样本,显示速率限制存在,但对于慢速探测速率,速率限制非常罕见。对于40,493/24块的随机样本(约2%的响应空间),我们确认6个块(0.02%!)的速率限制为每块0.39个数据包/秒。我们研究公共数据集中较高的速率,并建议响应的下降,因为速率接近每24个块的1个数据包/秒与速率限制一致。我们还表明,即使非常慢的探测(0.0001数据包/秒)也会遇到NACK的速率限制,这些NACK集中在探测器附近的单个路由器上
研究点的提出
网络管理员对ICMP进行限速(限速inbound ICMP)——路由器禅师ICMP error 报文
并且近期技术使得探测技术越来越快;
先前研究:测量互联网上的限速问题
(1)昂贵(需要数百个有利位置或谷歌CDN的服务器端流量)
(2)它们都没有考虑前向路径中ICMP回应请求的速率限制
希望在没有密集的流量探测或广泛的服务器端数据的情况下研究全球范围内的前向路径ICMP速率限制。
实验
限制块的建模
检测算法使用商用路由器中的速率限制模型
- 商业路由器:令牌桶算法,我们只模拟令牌桶的稳态行为,因为我们的主动探测(第4节)持续时间足够长(2周,1800次迭代)以避免瞬态条件的干扰
- 模型的可用性:N:回应的IP数,下图的A

- 回应速率建模:上图R
- 交替计数建模:响应轮换定义为地址从响应转换为非响应或相反的转换。频繁的交替有助于区分速率限制与其他数据包丢失源。观察到的响应变化的计数:
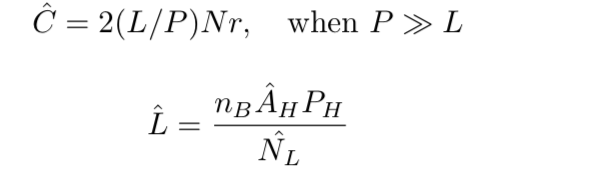
测量
输入:低速和高速测量
低速:低速率测量必须慢于检测到的任何速率限制:每块0.0001 ping / s
高速:必须超过目标速率限制,并且必须重复高速测量以使用我们的交替检测算法
低速和高速测量都需要持续24小时的倍数才能解决地址使用中的常规日变化问题
ICMP速率限制的四个阶段
- Non-RL(P<L)
- RL-Tran(L<P<1.1L): 限速开始
- RL-Sat(1.1L<P<100L):频繁地交替
- RL-Rej(P> T r e j T_{rej} TrejL, T r e j = 100 T_{rej}=100 Trej=100):大多包被丢弃
1.1L和100L:经验值

算法1,该子程序识别由速率限制引起的一致和随机丢包(通过查找大量响应交替)

Frequent Alternation Test
- 如果观察到的响应交替次数大于2倍的在慢扫描中发现的响应IP数乘以快速扫描中的探测轮数除以 R L − R e j 的 下 限 RL-Rej 的下限 RL−Rej的下限 并且快发现IP小于慢
then:频繁交替测试的结果 = passed
else:失败
FADER检测目标块是否受速率限制
实验结果
多少块受限制:测试数据:Heidemann, J., Pradkin, Y., Govindan, R., Papadopoulos, C., Bartlett, G., Bannis- ter, J.: Census and survey of the visible internet.
慢查(每块0.0001 ping / s)和快查(每块0.39 ping / s)定义了我们的算法检测到的限制速率限制的低速率和高速率
通过随机选择的响应IPv4地址空间的2%(抽样),60%不受限制。39%cannot tell,0.27%,111块受到速率限制
ICMP限制块非常罕见
验证结果保持不变
Is Faster Probing Rate Limited?:ZMap and Yarrp
结论
针对商用路由器和测试平台中的灵敏度实验验证了FADER,表明当探测流量在速率限制的1到60倍之间时,它非常准确地检测速率限制。
啊!这种我一点也不感兴趣啊
这篇关于论文阅读2018:Detecting ICMP Rate Limiting in the Internet的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)





