本文主要是介绍03 | Defining Query Methods 的命名语法与参数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Spring Data JPA 的最大特色是利用方法名定义查询方法(Defining Query Methods)来做 CRUD 操作,这一课时我将围绕这个内容来详细讲解。
在工作中,你是否经常为方法名的语义、命名规范而发愁?是否要为不同的查询条件写各种的 SQL 语句?是否为同一个实体的查询,写一个超级通用的查询方法或者 SQL?如果其他开发同事不查看你写的 SQL 语句,而直接看方法名的话,却不知道你想查什么而郁闷?
Spring Data JPA 的 Defining Query Methods(DQM)通过方法名和参数,可以很好地解决上面的问题,也能让我们的方法名的语义更加清晰,开发效率也会提升很多。DQM 语法共有 2 种,可以实现上面的那些问题,具体如下:
- 一种是直接通过方法名就可以实现,这也是本课时会详细介绍的重点内容;
- 另一种是 @Query 手动在方法上定义,这将在第 05 课时“@Query 帮我们解决了什么问题?什么时候应该选择 @Query?”中详细介绍。
下面我将从 6 个方面来详细讲解 Defining Query Methods。先来分析一下“定义查询方法的配置和使用方法”,这个是 Defining Query Methods 中必须要掌握的语法。
定义查询方法的配置和使用方法
若想要实现 CRUD 的操作,常规做法是写一大堆 SQL 语句。但在 JPA 里面,只需要继承 Spring Data Common 里面的任意 Repository 接口或者子接口,然后直接通过方法名就可以实现,神不神奇?来看下面具体的使用步骤。
第 1 步,User 实体的 UserRepository 继承 Spring Data Common 里面的 Repository 接口:
复制代码
interface UserRepository extends CrudRepository<User, Long> {User findByEmailAddress(String emailAddress);
}
第 2 步,对于 Service 层就可以直接使用 UserRepository 接口:
复制代码
@Service
public class UserServiceImpl{@AutowiredUserRepository userRepository;public void testJpa() {userRepository.deleteAll();userRepository.findAll();userRepository.findByEmailAddress("zjk@126.com");}
这个时候就可以直接调用 CrudRepository 里面暴露的所有接口方法,以及 UserRepository 里面定义的方法,不需要写任何 SQL 语句,也不需要写任何实现方法。通过上面的两步我们完成了 Defining Query Methods(DQM)的基本使用,下面来看另外一种情况:选择性暴露方法。
然而,有时如果不想暴露 CrudRepository 里面的所有方法,那么可以直接继承我们认为需要暴露的那些方法的接口。假如 UserRepository 只想暴露 findOne 和 save,除了这两个方法之外不允许任何的 User 操作,其做法如下。
我们选择性地暴露 CRUD 方法,直接继承Repository(因为这里面没有任何方法),把CrudRepository 里面的 save 和 findOne 方法复制到我们自己的 MyBaseRepository 接口即可,代码如下:
复制代码
@NoRepositoryBean
interface MyBaseRepository<T, ID extends Serializable> extends Repository<T, ID> {T findOne(ID id); T save(T entity);
}
interface UserRepository extends MyBaseRepository<User, Long> {User findByEmailAddress(String emailAddress);
}
这样在 Service 层就只有 findOne、save、findByEmailAddress 这 3 个方法可以调用,不会有更多方法了,我们可以对 SimpleJpaRepository 里面任意已经实现的方法做选择性暴露。
综上所述,得出以下 2 点结论:
- MyRepository Extends Repository 接口可以实现 Defining Query Methods 的功能;
- 继承其他 Repository 的子接口,或者自定义子接口,可以选择性地暴露 SimpleJpaRepository 里面已经实现的基础公用方法。
在平时的工作中,你可以通过方法名,或者定义方法名上面添加 @Query 注解两种方式来实现 CRUD 的目的,而 Spring 给我们提供了两种切换方式。接下来我们就讲讲“方法的查询策略设置”。
方法的查询策略设置
目前在实际生产中还没有遇到要修改默认策略的情况,但我们必须要知道有这样的配置方法,做到心中有数,这样我们才能知道为什么方法名可以,@Query 也可以。通过 @EnableJpaRepositories 注解来配置方法的查询策略,详细配置方法如下:
复制代码
@EnableJpaRepositories(queryLookupStrategy= QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND)
其中,QueryLookupStrategy.Key 的值共 3 个,具体如下:
- Create:直接根据方法名进行创建,规则是根据方法名称的构造进行尝试,一般的方法是从方法名中删除给定的一组已知前缀,并解析该方法的其余部分。如果方法名不符合规则,启动的时候会报异常,这种情况可以理解为,即使配置了 @Query 也是没有用的。
- USE_DECLARED_QUERY:声明方式创建,启动的时候会尝试找到一个声明的查询,如果没有找到将抛出一个异常,可以理解为必须配置 @Query。
- CREATE_IF_NOT_FOUND:这个是默认的,除非有特殊需求,可以理解为这是以上 2 种方式的兼容版。先用声明方式(@Query)进行查找,如果没有找到与方法相匹配的查询,那用 Create 的方法名创建规则创建一个查询;这两者都不满足的情况下,启动就会报错。
以 Spring Boot 项目为例,更改其配置方法如下:
复制代码
@EnableJpaRepositories(queryLookupStrategy= QueryLookupStrategy.Key.CREATE_IF_NOT_FOUND)
public class Example1Application {public static void main(String[] args) {SpringApplication.run(Example1Application.class, args);}
}
以上就是方法的查询策略设置,很简单。接下来我们再讲讲“Defining Query Method(DQM)语法”,这是可以让方法生效的详细语法。
Defining Query Method(DQM)语法
该语法是:带查询功能的方法名由查询策略(关键字)+ 查询字段 + 一些限制性条件组成,具有语义清晰、功能完整的特性,我们实际工作中 80% 的 API 查询都可以简单实现。
我们来看一个复杂点的例子,这是一个 and 条件更多、distinct or 排序、忽略大小写的例子。下面代码定义了 PersonRepository,我们可以在 service 层直接使用,如下所示:
复制代码
interface PersonRepository extends Repository<User, Long> {// and 的查询关系List<User> findByEmailAddressAndLastname(EmailAddress emailAddress, String lastname);// 包含 distinct 去重,or 的 sql 语法List<User> findDistinctPeopleByLastnameOrFirstname(String lastname, String firstname);// 根据 lastname 字段查询忽略大小写List<User> findByLastnameIgnoreCase(String lastname);// 根据 lastname 和 firstname 查询 equal 并且忽略大小写List<User> findByLastnameAndFirstnameAllIgnoreCase(String lastname, String firstname); // 对查询结果根据 lastname 排序,正序List<User> findByLastnameOrderByFirstnameAsc(String lastname);// 对查询结果根据 lastname 排序,倒序List<User> findByLastnameOrderByFirstnameDesc(String lastname);
}
下面表格是一个我们在上面 DQM 方法语法里常用的关键字列表,方便你快速查阅,并满足在实际代码中更加复杂的场景:
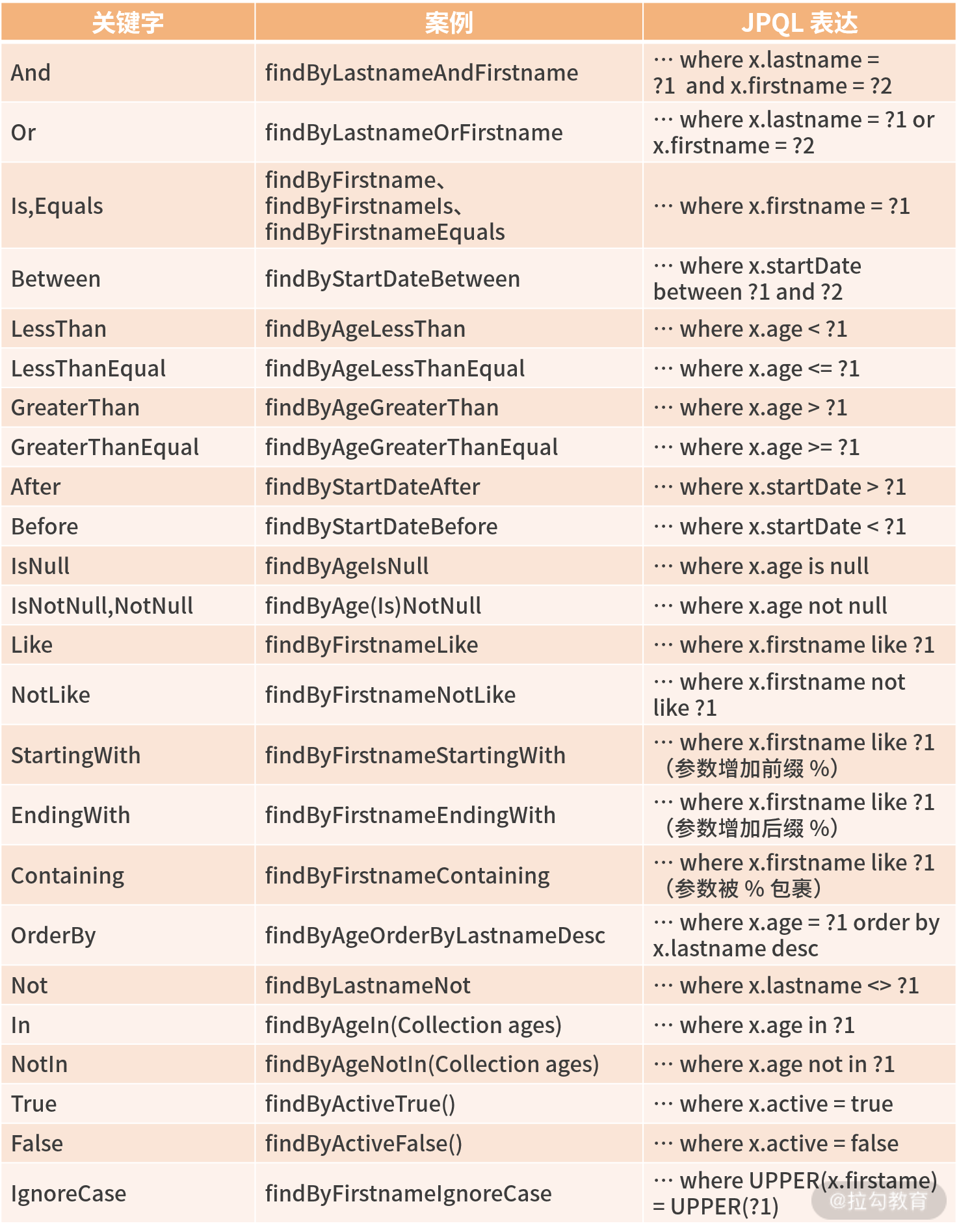
综上,总结 3 点经验:
- 方法名的表达式通常是实体属性连接运算符的组合,如 And、or、Between、LessThan、GreaterThan、Like 等属性连接运算表达式,不同的数据库(NoSQL、MySQL)可能产生的效果不一样,如果遇到问题,我们可以打开 SQL 日志观察。
- IgnoreCase 可以针对单个属性(如 findByLastnameIgnoreCase(…)),也可以针对查询条件里面所有的实体属性忽略大小写(所有属性必须在 String 情况下,如 findByLastnameAndFirstnameAllIgnoreCase(…))。
- OrderBy 可以在某些属性的排序上提供方向(Asc 或 Desc),称为静态排序,也可以通过一个方便的参数 Sort 实现指定字段的动态排序的查询方法(如 repository.findAll(Sort.by(Sort.Direction.ASC, “myField”)))。
我们看到上面的表格虽然大多是 find 开头的方法,除此之外,JPA 还支持read、get、query、stream、count、exists、delete、remove等前缀,如字面意思一样。我们来看看 count、delete、remove 的例子,其他前缀可以举一反三。实例代码如下:
复制代码
interface UserRepository extends CrudRepository<User, Long> {long countByLastname(String lastname);//查询总数long deleteByLastname(String lastname);//根据一个字段进行删除操作,并返回删除行数List<User> removeByLastname(String lastname);//根据Lastname删除一堆User,并返回删除的User
}
有的时候随着版本的更新,也会有更多的语法支持,或者不同的版本语法可能也不一样,我们通过源码来看一下上面说的几种语法。感兴趣的同学可以到类 org.springframework.data.repository.query.parser.PartTree 查看相关源码的逻辑和处理方法,关键源码如下:
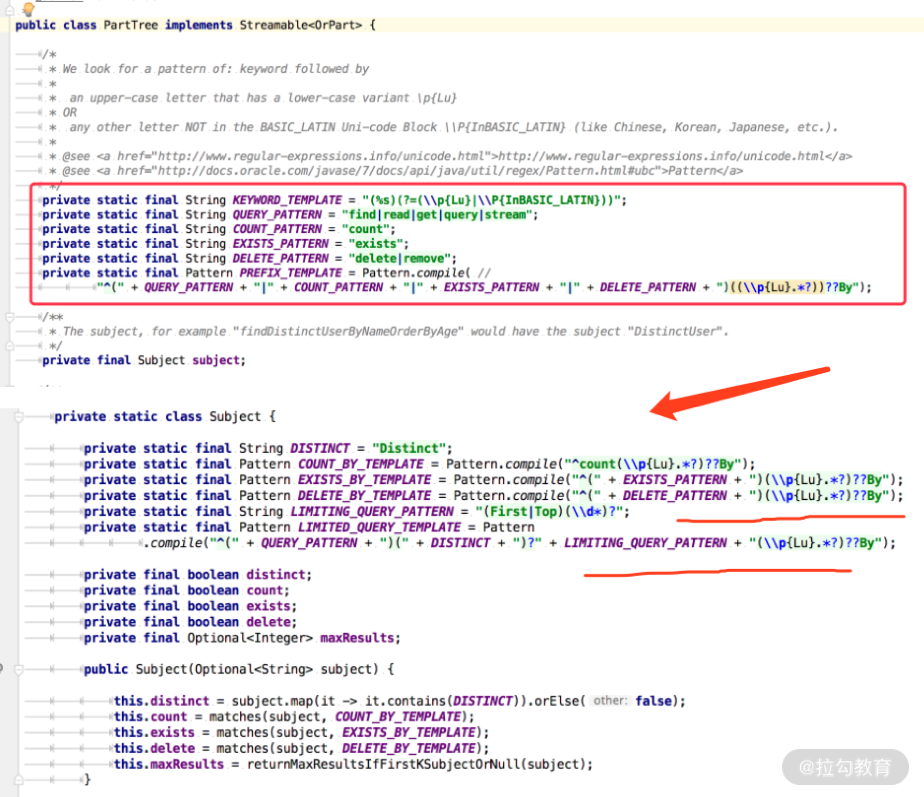
根据源码我们也可以分析出来,query method 包含其他的表达式,比如 find、count、delete、exist 等关键字在 by 之前通过正则表达式匹配。
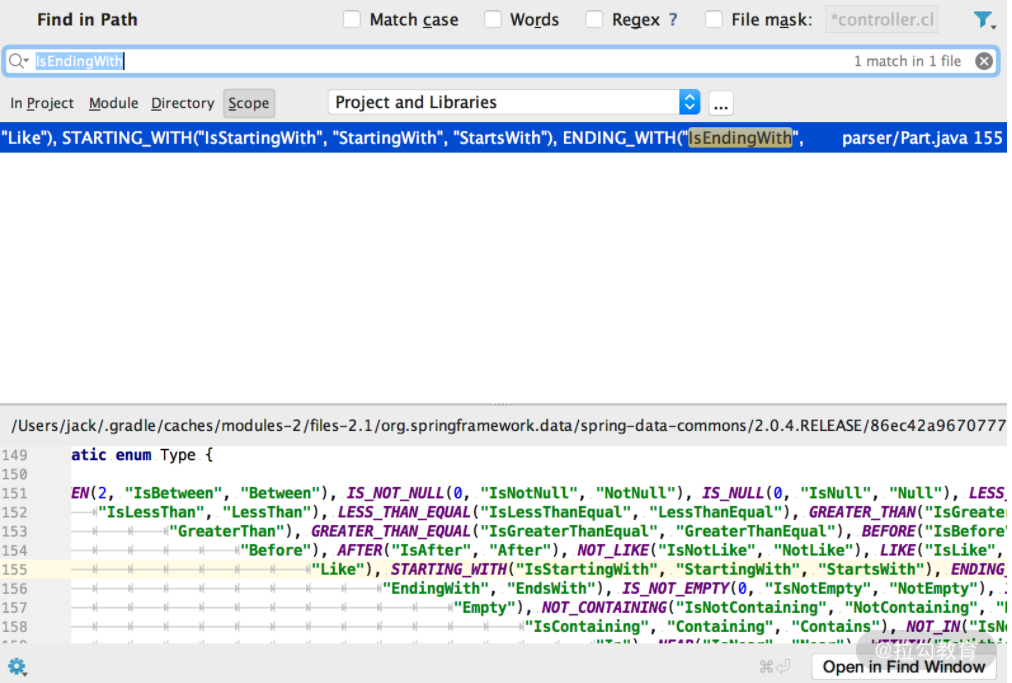
由此可知,我们方法中的关键字不是乱填的,是枚举帮我们定义好的。接下来打开枚举类 Type 源码看下,比什么都清楚。
复制代码
public static enum Type {BETWEEN(2, new String[]{"IsBetween", "Between"}),IS_NOT_NULL(0, new String[]{"IsNotNull", "NotNull"}),IS_NULL(0, new String[]{"IsNull", "Null"}),LESS_THAN(new String[]{"IsLessThan", "LessThan"}),LESS_THAN_EQUAL(new String[]{"IsLessThanEqual", "LessThanEqual"}),GREATER_THAN(new String[]{"IsGreaterThan", "GreaterThan"}),GREATER_THAN_EQUAL(new String[]{"IsGreaterThanEqual", "GreaterThanEqual"}),BEFORE(new String[]{"IsBefore", "Before"}),AFTER(new String[]{"IsAfter", "After"}),NOT_LIKE(new String[]{"IsNotLike", "NotLike"}),LIKE(new String[]{"IsLike", "Like"}),STARTING_WITH(new String[]{"IsStartingWith", "StartingWith", "StartsWith"}),ENDING_WITH(new String[]{"IsEndingWith", "EndingWith", "EndsWith"}),IS_NOT_EMPTY(0, new String[]{"IsNotEmpty", "NotEmpty"}),IS_EMPTY(0, new String[]{"IsEmpty", "Empty"}),NOT_CONTAINING(new String[]{"IsNotContaining", "NotContaining", "NotContains"}),CONTAINING(new String[]{"IsContaining", "Containing", "Contains"}),NOT_IN(new String[]{"IsNotIn", "NotIn"}),IN(new String[]{"IsIn", "In"}),NEAR(new String[]{"IsNear", "Near"}),WITHIN(new String[]{"IsWithin", "Within"}),REGEX(new String[]{"MatchesRegex", "Matches", "Regex"}),EXISTS(0, new String[]{"Exists"}),TRUE(0, new String[]{"IsTrue", "True"}),FALSE(0, new String[]{"IsFalse", "False"}),NEGATING_SIMPLE_PROPERTY(new String[]{"IsNot", "Not"}),SIMPLE_PROPERTY(new String[]{"Is", "Equals"});
....}
看源码就可以知道框架支持了哪些逻辑关键字,比如 NotIn、Like、In、Exists 等,有的时候比查文档和任何人写的博客都准确、还快。好了,上面介绍了方面名的基本表达方式,希望你可以在工作中灵活运用,举一反三。接下来我们讲讲特定类型的参数:Sort 排序和 Pageable 分页,这是分页和排序必备技能。
特定类型的参数:Sort 排序和 Pageable 分页
Spring Data JPA 为了方便我们排序和分页,支持了两个特殊类型的参数:Sort 和 Pageable。
Sort 在查询的时候可以实现动态排序,我们看下其源码:
复制代码
public Sort(Direction direction, String... properties) {this(direction, properties == null ? new ArrayList<>() : Arrays.asList(properties));
}
Sort 里面决定了我们哪些字段的排序方向(ASC 正序、DESC 倒序)。
Pageable 在查询的时候可以实现分页效果和动态排序双重效果,我们看下 Pageable 的 Structure,如下图所示:
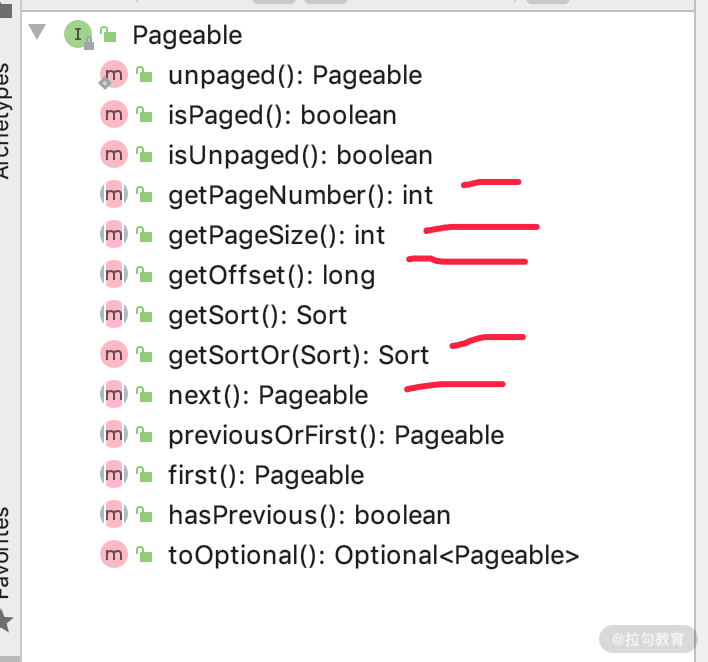
我们发现 Pageable 是一个接口,里面有常见的分页方法排序、当前页、下一行、当前指针、一共多少页、页码、pageSize 等。
在查询方法中如何使用 Pageable 和 Sort 呢?下面代码定义了根据 Lastname 查询 User 的分页和排序的实例,此段代码是在 UserRepository 接口里面定义的方法:
复制代码
Page<User> findByLastname(String lastname, Pageable pageable);//根据分页参数查询User,返回一个带分页结果的Page(下一课时详解)对象(方法一)
Slice<User> findByLastname(String lastname, Pageable pageable);//我们根据分页参数返回一个Slice的user结果(方法二)
List<User> findByLastname(String lastname, Sort sort);//根据排序结果返回一个List(方法三)
List<User> findByLastname(String lastname, Pageable pageable);//根据分页参数返回一个List对象(方法四)
方法一:允许将 org.springframework.data.domain.Pageable 实例传递给查询方法,将分页参数添加到静态定义的查询中,通过 Page 返回的结果得知可用的元素和页面的总数。这种分页查询方法可能是昂贵的(会默认执行一条 count 的 SQL 语句),所以用的时候要考虑一下使用场景。
方法二:返回结果是 Slice,因为只知道是否有下一个 Slice 可用,而不知道 count,所以当查询较大的结果集时,只知道数据是足够的,也就是说用在业务场景中时不用关心一共有多少页。
方法三:如果只需要排序,需在 org.springframework.data.domain.Sort 参数中添加一个参数,正如上面看到的,只需返回一个 List 也是有可能的。
方法四:排序选项也通过 Pageable 实例处理,在这种情况下,Page 将不会创建构建实际实例所需的附加元数据(即不需要计算和查询分页相关数据),而仅仅用来做限制查询给定范围的实体。
那么如何使用呢?我们再来看一下源码,也就是 Pageable 的实现类,如下图所示:
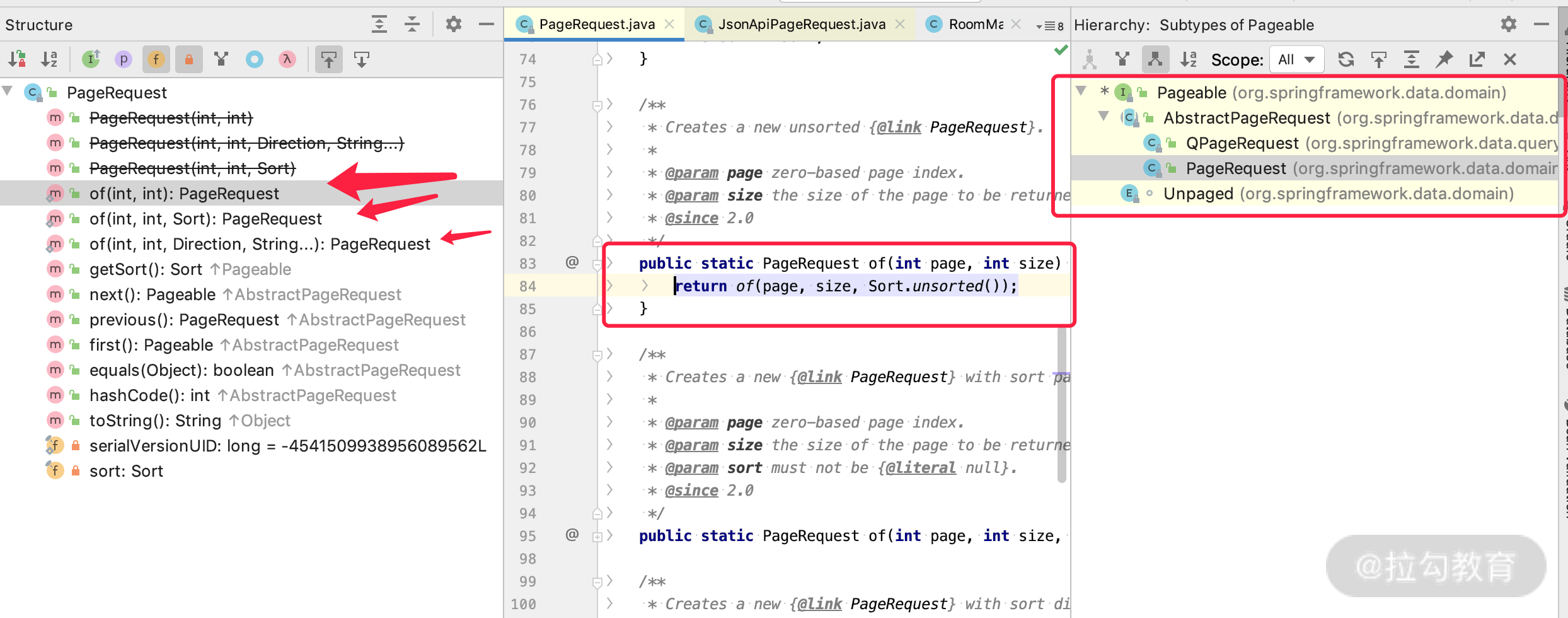
由此可知,我们可以通过 PageRequest 里面提供的几个 of 静态方法(多态),分别构建页码、页面大小、排序等。我们来看下,在使用中的写法,如下所示:
复制代码
//查询user里面的lastname=jk的第一页,每页大小是20条;并会返回一共有多少页的信息
Page<User> users = userRepository.findByLastname("jk",PageRequest.of(1, 20));
//查询user里面的lastname=jk的第一页的20条数据,不知道一共多少条
Slice<User> users = userRepository.findByLastname("jk",PageRequest.of(1, 20));
//查询出来所有的user里面的lastname=jk的User数据,并按照name正序返回List
List<User> users = userRepository.findByLastname("jk",new Sort(Sort.Direction.ASC, "name"))
//按照createdAt倒序,查询前一百条User数据
List<User> users = userRepository.findByLastname("jk",PageRequest.of(0, 100, Sort.Direction.DESC, "createdAt"));
上面讲解了分页和排序的应用场景,在实际工作中,如果遇到不知道参数怎么传递的情况,可以看一下源码,因为 Java 是类型安全的。接下来讲解“限制查询结果 First 和 Top”,这是分页的另一种表达方式。
限制查询结果 First 和 Top
有的时候我们想直接查询前几条数据,也不需要动态排序,那么就可以简单地在方法名字中使用 First 和 Top 关键字,来限制返回条数。
我们来看看 userRepository 里面可以定义的一些限制返回结果的使用。在查询方法上加限制查询结果的关键字 First 和 Top。
复制代码
User findFirstByOrderByLastnameAsc();
User findTopByOrderByAgeDesc();
List<User> findDistinctUserTop3ByLastname(String lastname, Pageable pageable);
List<User> findFirst10ByLastname(String lastname, Sort sort);
List<User> findTop10ByLastname(String lastname, Pageable pageable);
其中:
- 查询方法在使用 First 或 Top 时,数值可以追加到 First 或 Top 后面,指定返回最大结果的大小;
- 如果数字被省略,则假设结果大小为 1;
- 限制表达式也支持 Distinct 关键字;
- 支持将结果包装到 Optional 中(下一课时详解)。
- 如果将 Pageable 作为参数,以 Top 和 First 后面的数字为准,即分页将在限制结果中应用。
First 和 Top 关键字的使用非常简单,可以让我们的方法名语义更加清晰。接下来讲讲 NULL 的情况作了哪些支持。
@NonNull、@NonNullApi、@Nullable
从 Spring Data 2.0 开始,JPA 新增了@NonNull @NonNullApi @Nullable,是对 null 的参数和返回结果做的支持。
- @NonNullApi:在包级别用于声明参数,以及返回值的默认行为是不接受或产生空值的。
- @NonNull:用于不能为空的参数或返回值(在 @NonNullApi 适用的参数和返回值上不需要)。
- @Nullable:用于可以为空的参数或返回值。
我在自己的 Repository 所在 package 的 package-info.java 类里面做如下声明:
复制代码
@org.springframework.lang.NonNullApi
package com.myrespository;
myrespository 下面的 UserRepository 实现如下:
复制代码
package com.myrespository;
import org.springframework.lang.Nullable;
interface UserRepository extends Repository<User, Long> {User getByEmailAddress(EmailAddress emailAddress);
}
这个时候当 emailAddress 参数为 null 的时候就会抛异常,当返回结果为 null 的时候也会抛异常。因为我们在package 的 package-info.java里面指定了NonNullApi,所有返回结果和参数不能为 Null。
复制代码
@NullableUser findByEmailAddress(@Nullable EmailAddress emailAdress);//当我们添加@Nullable 注解之后,参数和返回结果这个时候就都会允许为 null 了;Optional<User> findOptionalByEmailAddress(EmailAddress emailAddress); //返回结果允许为 null,参数不允许为 null 的情况
以上就是对 Defining Query Methods 的方法名和分页参数整体学习了。
给我们的一些思考
我们学习了 Defining Query Methods 的语法和其所表达的命名规范,在实际工作中,也可以将方法名(非常语义化的 respository 里面所定义方法命名规范)的强制约定规范运用到 controller 和 service 层,这样全部统一后,可以减少很多的沟通成本。
Spring Data Common 里面的 repository 基类,我们是否可以应用推广到 service 层呢?能否也建立一个自己的 baseService?我们来看下面的实战例子:
复制代码
public interface BaseService<T, ID> {Class<T> getDomainClass();<S extends T> S save(S entity);<S extends T> List<S> saveAll(Iterable<S> entities);void delete(T entity);void deleteById(ID id);void deleteAll();void deleteAll(Iterable<? extends T> entities);void deleteInBatch(Iterable<T> entities);void deleteAllInBatch();T getOne(ID id);<S extends T> Optional<S> findOne(Example<S> example);Optional<T> findById(ID id);List<T> findAll();List<T> findAll(Sort sort);Page<T> findAll(Pageable pageable);<S extends T> List<S> findAll(Example<S> example);<S extends T> List<S> findAll(Example<S> example, Sort sort);<S extends T> Page<S> findAll(Example<S> example, Pageable pageable);List<T> findAllById(Iterable<ID> ids);long count();<S extends T> long count(Example<S> example);<S extends T> boolean exists(Example<S> example);boolean existsById(ID id);void flush();<S extends T> S saveAndFlush(S entity);
}
我们模仿JpaRepository接口也自定义了一个自己的BaseService,声明了常用的CRUD操作,上面的代码是生产代码,可以作为参考。当然了我们也可以建立自己的 PagingAndSortingService、ComplexityService、SampleService 等来划分不同的 service接口,供不同目的 Service 子类继承。
我们再来模仿一个 SimpleJpaRepository,来实现自己的 BaseService 的实现类。
复制代码
public class BaseServiceImpl<T, ID, R extends JpaRepository<T, ID>> implements BaseService<T, ID> {private static final Map<Class, Class> DOMAIN_CLASS_CACHE = new ConcurrentHashMap<>();private final R repository;public BaseServiceImpl(R repository) {this.repository = repository;}@Overridepublic Class<T> getDomainClass() {Class thisClass = getClass();Class<T> domainClass = DOMAIN_CLASS_CACHE.get(thisClass);if (Objects.isNull(domainClass)) {domainClass = GenericsUtils.getGenericClass(thisClass, 0);DOMAIN_CLASS_CACHE.putIfAbsent(thisClass, domainClass);}return domainClass;}protected R getRepository() {return repository;}@Overridepublic <S extends T> S save(S entity) {return repository.save(entity);}@Overridepublic <S extends T> List<S> saveAll(Iterable<S> entities) {return repository.saveAll(entities);}@Overridepublic void delete(T entity) {repository.delete(entity);}@Overridepublic void deleteById(ID id) {repository.deleteById(id);}@Overridepublic void deleteAll() {repository.deleteAll();}@Overridepublic void deleteAll(Iterable<? extends T> entities) {repository.deleteAll(entities);}@Overridepublic void deleteInBatch(Iterable<T> entities) {repository.deleteInBatch(entities);}@Overridepublic void deleteAllInBatch() {repository.deleteAllInBatch();}@Overridepublic T getOne(ID id) {return repository.getOne(id);}@Overridepublic <S extends T> Optional<S> findOne(Example<S> example) {return repository.findOne(example);}@Overridepublic Optional<T> findById(ID id) {return repository.findById(id);}@Overridepublic List<T> findAll() {return repository.findAll();}@Overridepublic List<T> findAll(Sort sort) {return repository.findAll(sort);}@Overridepublic Page<T> findAll(Pageable pageable) {return repository.findAll(pageable);}@Overridepublic <S extends T> List<S> findAll(Example<S> example) {return repository.findAll(example);}@Overridepublic <S extends T> List<S> findAll(Example<S> example, Sort sort) {return repository.findAll(example, sort);}@Overridepublic <S extends T> Page<S> findAll(Example<S> example, Pageable pageable) {return repository.findAll(example, pageable);}@Overridepublic List<T> findAllById(Iterable<ID> ids) {return repository.findAllById(ids);}@Overridepublic long count() {return repository.count();}@Overridepublic <S extends T> long count(Example<S> example) {return repository.count(example);}@Overridepublic <S extends T> boolean exists(Example<S> example) {return repository.exists(example);}@Overridepublic boolean existsById(ID id) {return repository.existsById(id);}@Overridepublic void flush() {repository.flush();}@Overridepublic <S extends T> S saveAndFlush(S entity) {return repository.saveAndFlush(entity);}
}
以上代码就是 BaseService 常用的 CURD 实现代码,我们这里面大部分也是直接调用 Repository 提供的方法。需要注意的是,当继承 BaseServiceImpl 的时候需要传递自己的 Repository,如下面实例代码:
复制代码
@Service
public class UserServiceImpl extends BaseServiceImpl<User, Long, UserRepository> implements UserService {public UserServiceImpl(UserRepository repository) {super(repository);}.....
}
实战思考只是提供一种常见的实现思路,你也可以根据实际情况进行扩展和扩充。
这篇关于03 | Defining Query Methods 的命名语法与参数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




