本文主要是介绍如何使用 arrayList.removeAll(Collection<?> c)?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
引言
对于 Collection 集合及其实现类都有 removeAll(Collection<?> c)。
对于ArrayList 的实例对象,在数据比较多的情况下,方法 removeAll() 的传参 c 的类型是 HashSet会比是 ArrayList 的情况快的多。
原因
我们来细看一下ArrayList类的removeAll()方法实现的伪代码。
如:arrayList.removeAll(subList);// 遍历底层数组,将不需要删除的元素放在数组前面,后面的全部置为 null
// w 为要删除和不删除的分界线
int w = 0;
for(var value in 该 arrayList 的底层数组){if(!subList.contains(value)){该 arrayList 的底层数组 [w] = value;w++;}
}
这里影响速率关键的一步是:subList.contains(value)!
这是因为contains()方法在不同类中的实现是存在差异的。
对于 ArrayList.contains(),它的实现是调用 indexOf(),一个一个地遍历查找。最坏时间复杂度为O(总数据量)。
而对于 HashSet.contains(),由于 HashSet 的底层是 HashMap,因此实际调用的是 HashMap 的 containsKey()方法,该方法是通过哈希计算的方式去查询的,因此速度十分快。最坏的时间复杂度约为O(最长链表长度),而链表长度一般不会过大。
使用方法
在数据量比较大的的情况下,使用arrayList.removeAll(subList)时,可以将subList封装为HashSet:
arrayList.removeAll(new HashSet(subList));
速度实测:
| 数据量 | ArrayList | HashSet | LinkedList |
|---|---|---|---|
| 10 万 | 1094 毫秒 | 6 毫秒 | 1133 毫秒 |
| 20 万 | 4140毫秒 | 8 毫秒 | 4241 毫秒 |
| 50 万 | 51431毫秒 | 30 毫秒 | 34380 毫秒 |
| 100 万 | 140444 毫秒 | 36 毫秒 | 179465 毫秒 |
| 500 万 | 9130706 毫秒 | 79 毫秒 | 10549229 毫秒 |
测试用的代码:
public class RemoveAllTest {public static void main(String[] args) {ArrayList<Integer> arrayList = new ArrayList<>();for (int i = 0; i < 5000000; i++) {arrayList.add(i);}ArrayList<Integer> subList = new ArrayList<>();for (int i = 0; i < 5000000; i++) {subList.add(i);i += 2;}// 测试入参为 ArrayList 类型时 removeAll() 的性能long startTime = System.currentTimeMillis();arrayList.removeAll(subList);long endTime = System.currentTimeMillis();System.out.println("ArrayList 耗时:" + (endTime - startTime));// 测试入参为 HashSet 类型时 removeAll() 的性能ArrayList<Integer> arrayList2 = new ArrayList<>();for (int i = 0; i < 5000000; i++) {arrayList2.add(i);}startTime = System.currentTimeMillis();arrayList2.removeAll(new HashSet<>(subList));endTime = System.currentTimeMillis();System.out.println("HashSet 耗时:" + (endTime - startTime));// 测试将 ArrayList 类型转成 LinkedList 类型ArrayList<Integer> arrayList3 = new ArrayList<>();for (int i = 0; i < 5000000; i++) {arrayList3.add(i);}startTime = System.currentTimeMillis();new LinkedList(arrayList3).removeAll(subList);endTime = System.currentTimeMillis();System.out.println("LinkedList 耗时:" + (endTime - startTime));}
}
HashSet 、LinkedList 中 removeAll() 方法的区别
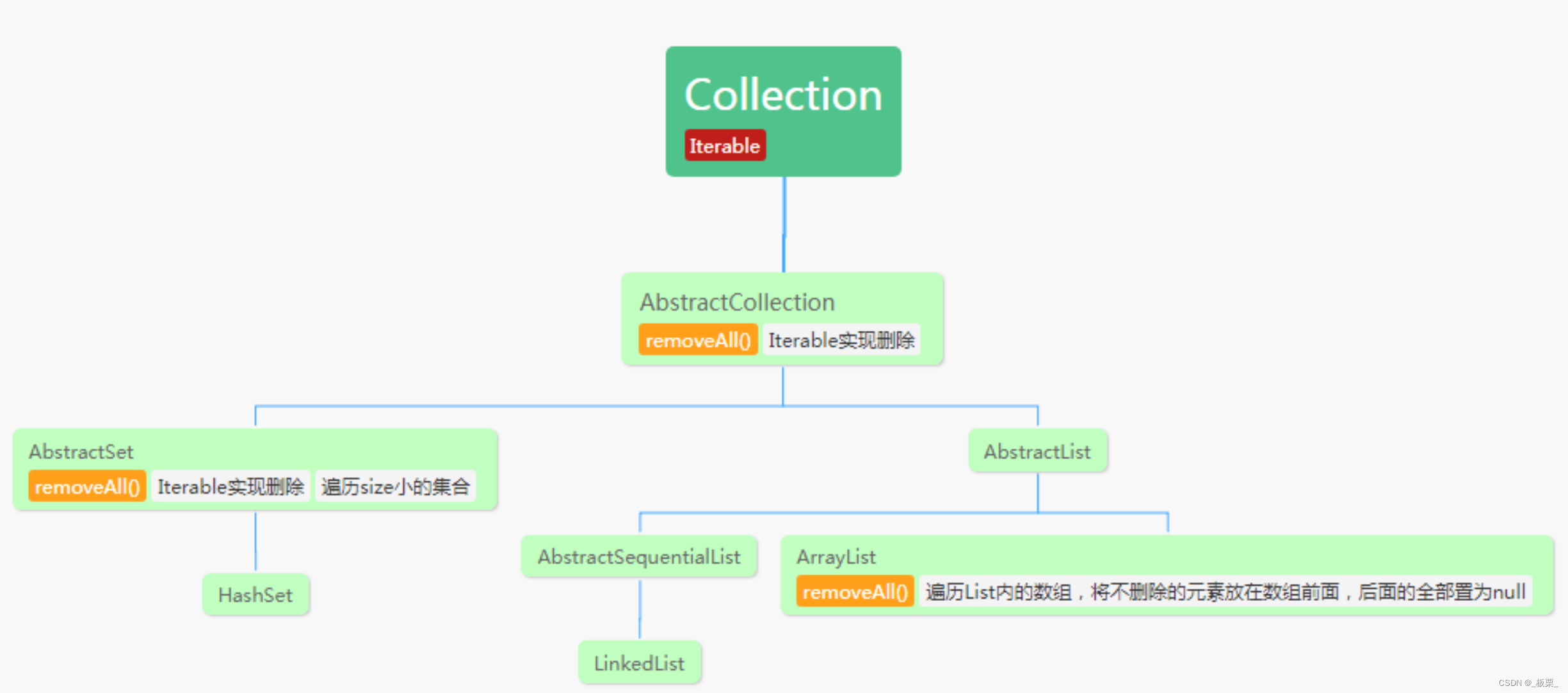
不同类的 removeAll() 方法实现不同,可以看到对于 HashSet 和 LinkedList,他们的 removeAll() 方法是通过父类或超父类的迭代器进行实现的,而 ArrayList 是自己通过 for 循环进行了实现。
HashSet 内部实现
依托于 AbstractSet 类的 removeAll(Collection<?> c) 方法,实现的逻辑是:
先调原集合对象 HashSet 和 removeAll(Collection<?> c) 方法中传入的参数 c 的 size() 方法,用来判断谁包含的元素更多。
-
如果原集合对象的元素数量 > c 中元素数量,那么调用 c 的代器去遍历 c ,查看元素是否包含在原集合中,并使用原集合的
remove()方法去删除元素。时间复杂度为 O(n)。 -
如果原集合对象的元素数量 < c 中元素数量,那么调用原集合对象的迭代器去遍历原集合,检查元素是否包含在 c 中,并调用原集合迭代器的
remove()方法去删除元素。这里的时间复杂度与集合 c 的contains()方法的实现有关:-
如果 c 是一个
ArrayList,contains()方法的时间复杂度是 O( m )。因此,从集合HashSet中删除ArrayList中存在的所有元素的总体时间复杂度为 O( n * m )。 -
如果 c 再次是
HashSet,则contains()方法的时间复杂度为 O(1)。因此,从集合HashSet中删除HashSet中存在的所有元素的总体时间复杂度为 O( n )。
-
public boolean removeAll(Collection<?> c) {Objects.requireNonNull(c);boolean modified = false;if (size() > c.size()) {for (Iterator<?> i = c.iterator(); i.hasNext(); )modified |= remove(i.next());} else {for (Iterator<?> i = iterator(); i.hasNext(); ) {if (c.contains(i.next())) {i.remove();modified = true;}}}return modified;
}
LinkedList 内部实现
public boolean removeAll(Collection<?> c) {Objects.requireNonNull(c);boolean modified = false;Iterator<?> it = iterator();while (it.hasNext()) {if (c.contains(it.next())) {it.remove();modified = true;}}return modified;
}
通过 contains() 方法来判断是否存在相同的元素,效率与 c 的类型有关。
参考
-
为什么arrayList.removeAll(set)的速度远高于arrayList.removeAll(list)?
-
Java 中 HashSet 的 removeAll 性能分析
这篇关于如何使用 arrayList.removeAll(Collection<?> c)?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





