本文主要是介绍K8S RC RS DaemonSet StatefulSet Job CronJob,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
RC、RS
RC: ReplicasController:副本控制器
RS: ReplicasSet:副本集;Deployment【滚动更新特性】默认控制的是他
RC是老版,RS是新版(可以有复杂的选择器【表达式】)。
## RS支持复杂选择器
matchExpressions:key: pod-name value: [aaaa,bbb] # In, NotIn, Exists and DoesNotExist # In: value: [aaaa,bbb]必须存在,表示key指定的标签的值是这个集合内的 # NotIn value: [aaaa,bbb]必须存在,表示key指定的标签的值不是这个集合内的 # Exists # 只要有key指定的标签即可,不用管值是多少 # DoesNotExist # 只要Pod上没有key指定的标签,不用管值是多少 operator: DoesNotExist虽然ReplicasSet强大,但是我们也不直接写RS;
都是直接写Deployment的,Deployment会自动产生RS。
Deployment每次的滚动更新都会产生新的RS。
DaemonSet:
k8s集群的每个机器(每一个节点)都运行一个程序(默认master除外,master节点默认不会把Pod调度过去)
无需指定副本数量;因为默认给每个机器都部署一个(master除外)
DaemonSet 控制器确保所有(或一部分)的节点都运行了一个指定的 Pod 副本。
1.每当向集群中添加一个节点时,指定的 Pod 副本也将添加到该节点上
2.当节点从集群中移除时,Pod 也就被垃圾回收了
3.删除一个 DaemonSet 可以清理所有由其创建的 Pod
DaemonSet 的典型使用场景有:
在每个节点上运行集群的存储守护进程,例如 glusterd、ceph
在每个节点上运行日志收集守护进程,例如 fluentd、logstash
在每个节点上运行监控守护进程,例如 Prometheus Node Exporter、Sysdig Agent、collectd、
Dynatrace OneAgent、APPDynamics Agent、Datadog agent、New Relic agent、Ganglia gmond、Instana Agent 等
apiVersion: apps/v1
kind: DaemonSet
metadata:name: ds-testnamespace: defaultlabels:app: ds-test
spec:selector:matchLabels:app: ds-testtemplate:metadata:labels:app: ds-testspec:containers:- name: ds-testimage: nginx
StatefulSet:
Deployment部署的应用我们一般称为无状态应用
StatefulSet部署的应用我们一般称为有状态应用
无状态应用:网络可能会变,存储可能会变,顺序可能会变。场景就是业务代码(Deployment)
有状态应用:网络不变,存储不变,顺序不变。场景就是中间件(MySQL、Redis、MQ)
有状态副本集;Deployment等属于无状态的应用部署(stateless)
StatefulSet 使用场景;对于有如下要求的应用程序,StatefulSet 非常适用:
稳定、唯一的网络标识(dnsname)【必须配合Service】
StatefulSet通过与其相关的无头服务为每个pod提供DNS解析条目。假如无头服务的DNS
条目为: “ ( s e r v i c e n a m e ) . (service name). (servicename).(namespace).svc.cluster.local”,
那么pod的解析条目就是" ( p o d n a m e ) . (pod name). (podname).(service name).$(namespace).svc.cluster.local",
每个pod name也是唯一的。
稳定的、持久的存储;【每个Pod始终对应各自的存储路径(PersistantVolumeClaimTemplate)】
有序的、优雅的部署和缩放。【按顺序地增加副本、减少副本,并在减少副本时执行清理】
有序的、自动的滚动更新。【按顺序自动地执行滚动更新】
限制:
1.给定 Pod 的存储必须由 PersistentVolume 驱动 基于所请求的 storage class 来提供,或
者由管理员预先提供。
2.删除或者收缩 StatefulSet 并不会 删除它关联的存储卷。 这样做是为了保证数据安全,它通
常比自动清除 StatefulSet 所有相关的资源更有价值。
3.StatefulSet 当前需要无头服务 来负责 Pod 的网络标识。你需要负责创建此服务。
4.当删除 StatefulSets 时,StatefulSet 不提供任何终止 Pod 的保证。 为了实现 StatefulSet 中的
Pod 可以有序地且体面地终止,可以在删除之前将 StatefulSet 缩放为 0。
5.在默认 Pod 管理策略( OrderedReady ) 时使用 滚动更新,可能进入需要人工干预 才能修复
的损坏状态。
如果一个应用程序不需要稳定的网络标识,或者不需要按顺序部署、删除、增加副本,就应该考虑使用
Deployment 这类无状态(stateless)的控制器
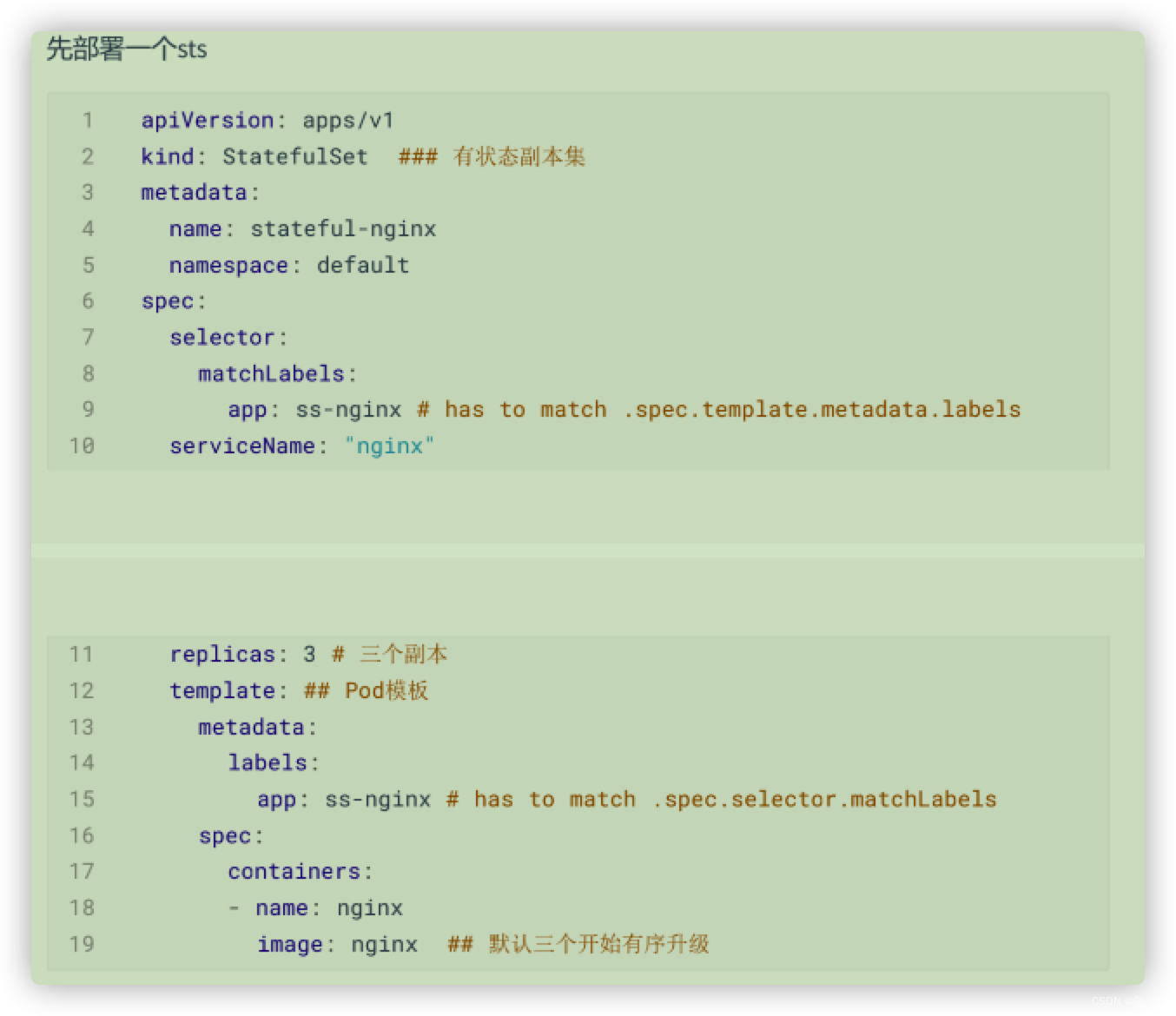
定义pod启动:
apiVersion: apps/v1
kind: StatefulSet ### 有状态副本集
metadata:name: stateful-nginxnamespace: default
spec:selector:matchLabels:app: ss-nginx # has to match .spec.template.metadata.labelsserviceName: "nginx" ## 服务名,指定加到那个service里面replicas: 3 # 三个副本template: ## Pod模板metadata:labels:app: ss-nginx # has to match .spec.selector.matchLabelsspec:containers:- name: nginximage: nginx
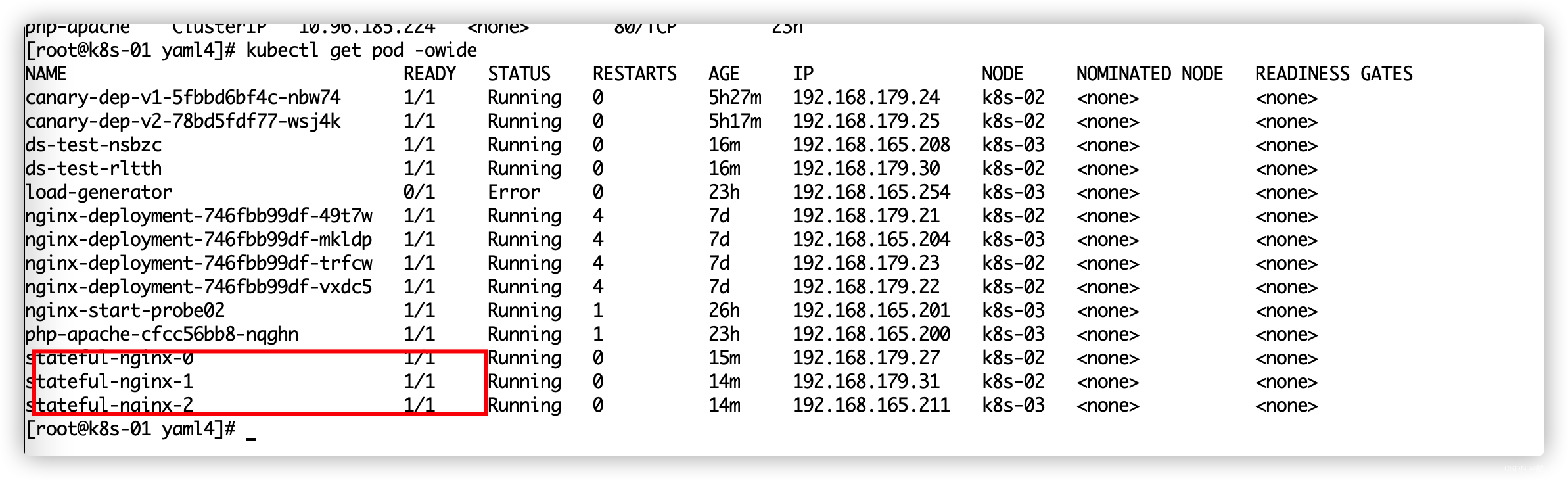
定义负责均衡网络pod:
## 加网络
apiVersion: v1
kind: Service
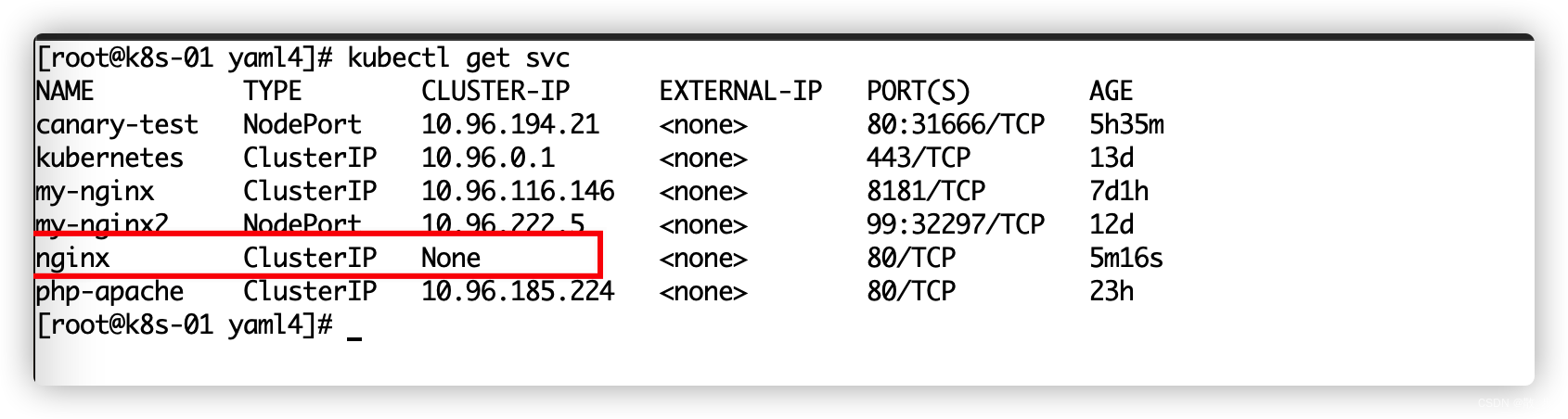
metadata:name: nginx ## 和上面的serviceNamenamespace: default
spec:selector:app: ss-nginxclusterIP: None ## 不要分配ClusterIP,headless service,整个集群的Pod能直接访问# 浏览器目前不能访问,mysql\mq。继续使用ingress网络定义所有的访问逻辑type: ClusterIPports:- name: httpport: 80targetPort: 80
随意进入一个pod访问: pod名.service名.namespace名.后面一串默认的
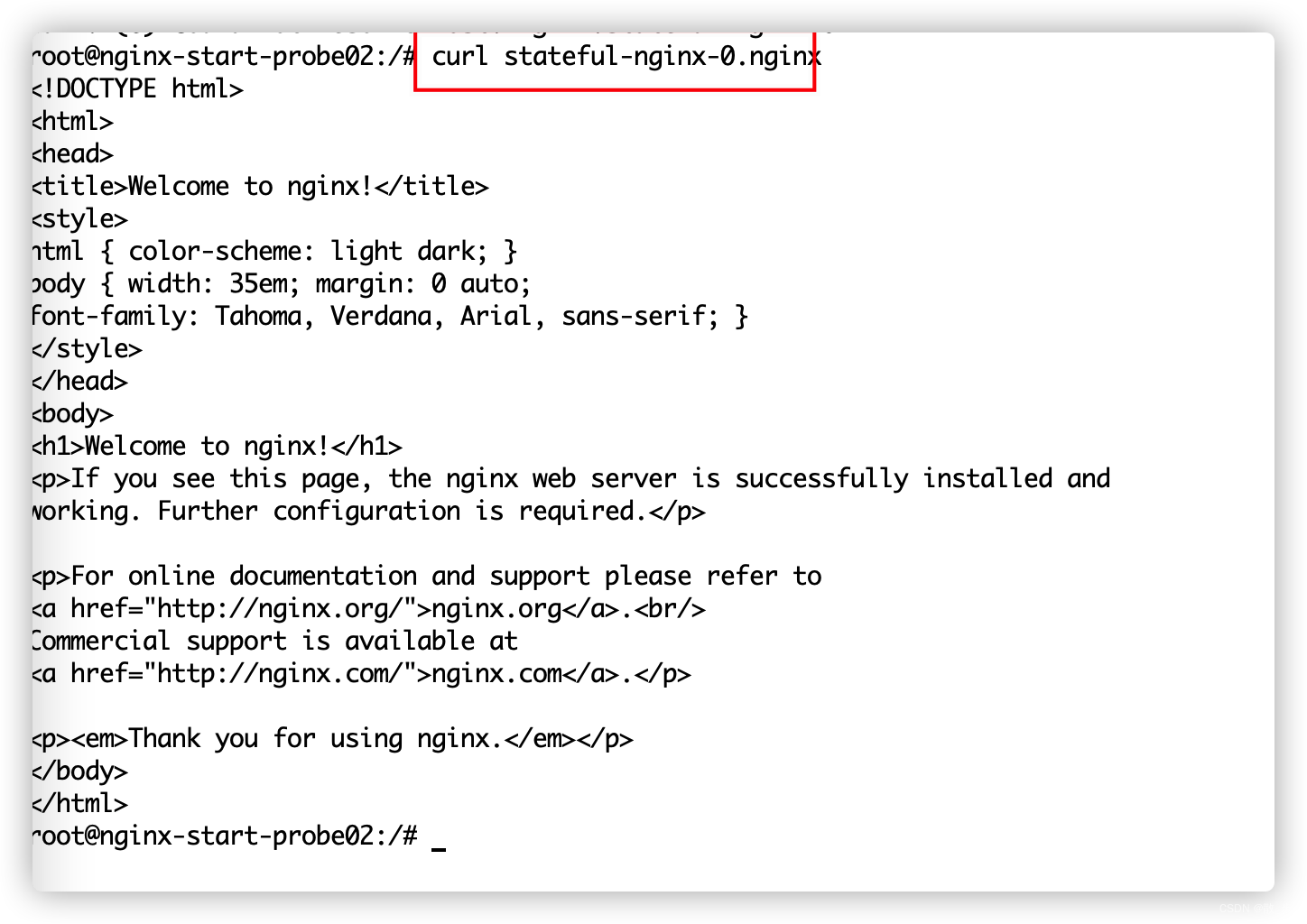
#观察效果。
删除一个,重启后名字,ip等都是一样的。保证了状态
#细节
kubectl explain StatefulSet.spec podManagementPolicy: OrderedReady(按序)、Parallel(并发)
serviceName -required- 设置服务名,就可以用域名访问pod了。 pod-specific-string.serviceName.default.svc.cluster.local
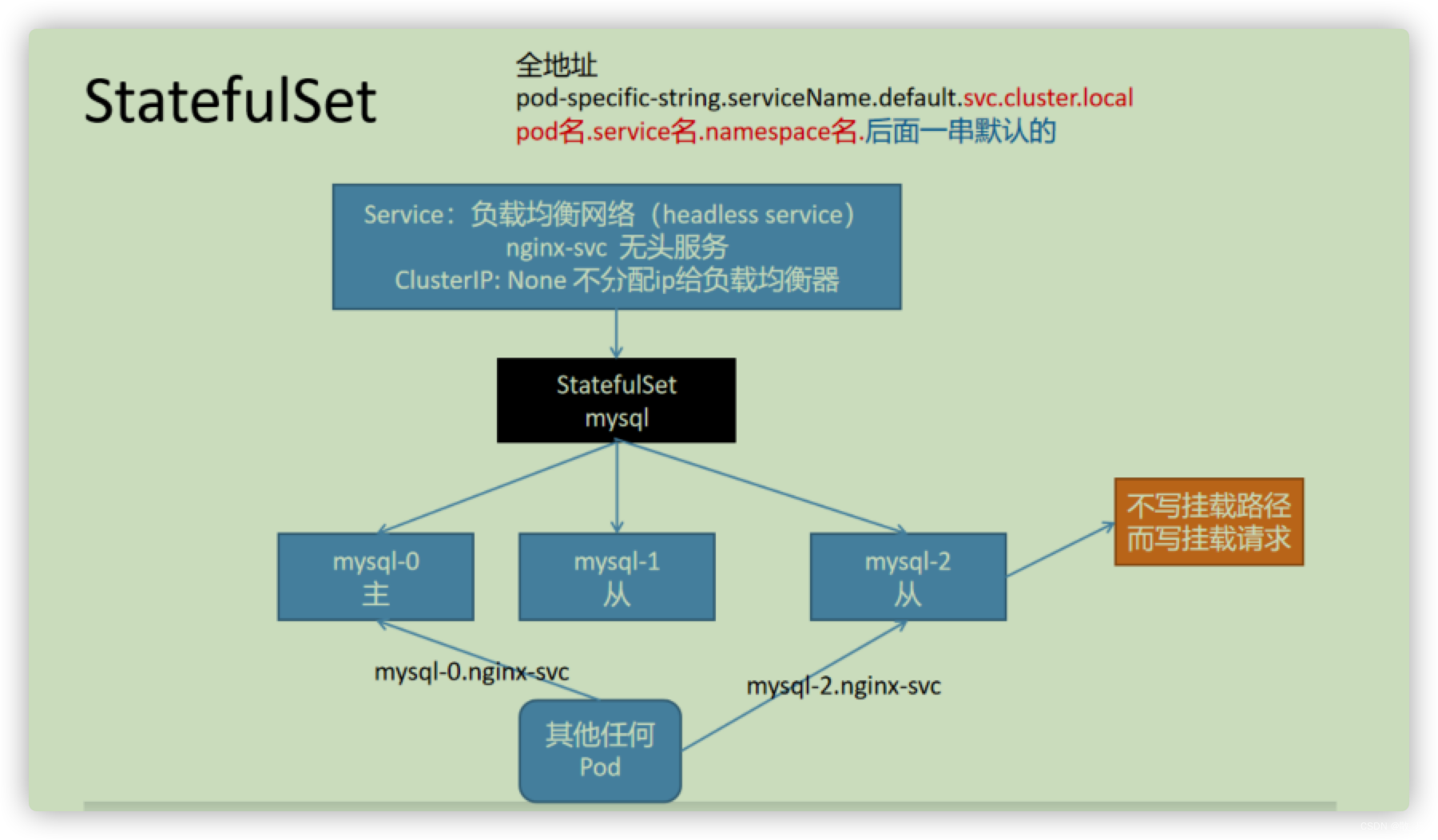
DNS解析。整个状态kubelet(DNS内容同步到Pod)和kube-proxy(整个集群网络负责)会同步
curl nginx-svc: 负载均衡到sts部署的Pod上
curl mysql-0.nginx-svc: 直接访问指定Pod
和Deployment不同的字段:
podManagementPolicy: pod管理策略
控制Pod创建、升级以及扩缩容逻辑
默认是 OrderedReady : 有序启动
修改为 Parallel : 同时创建启动,一般不用
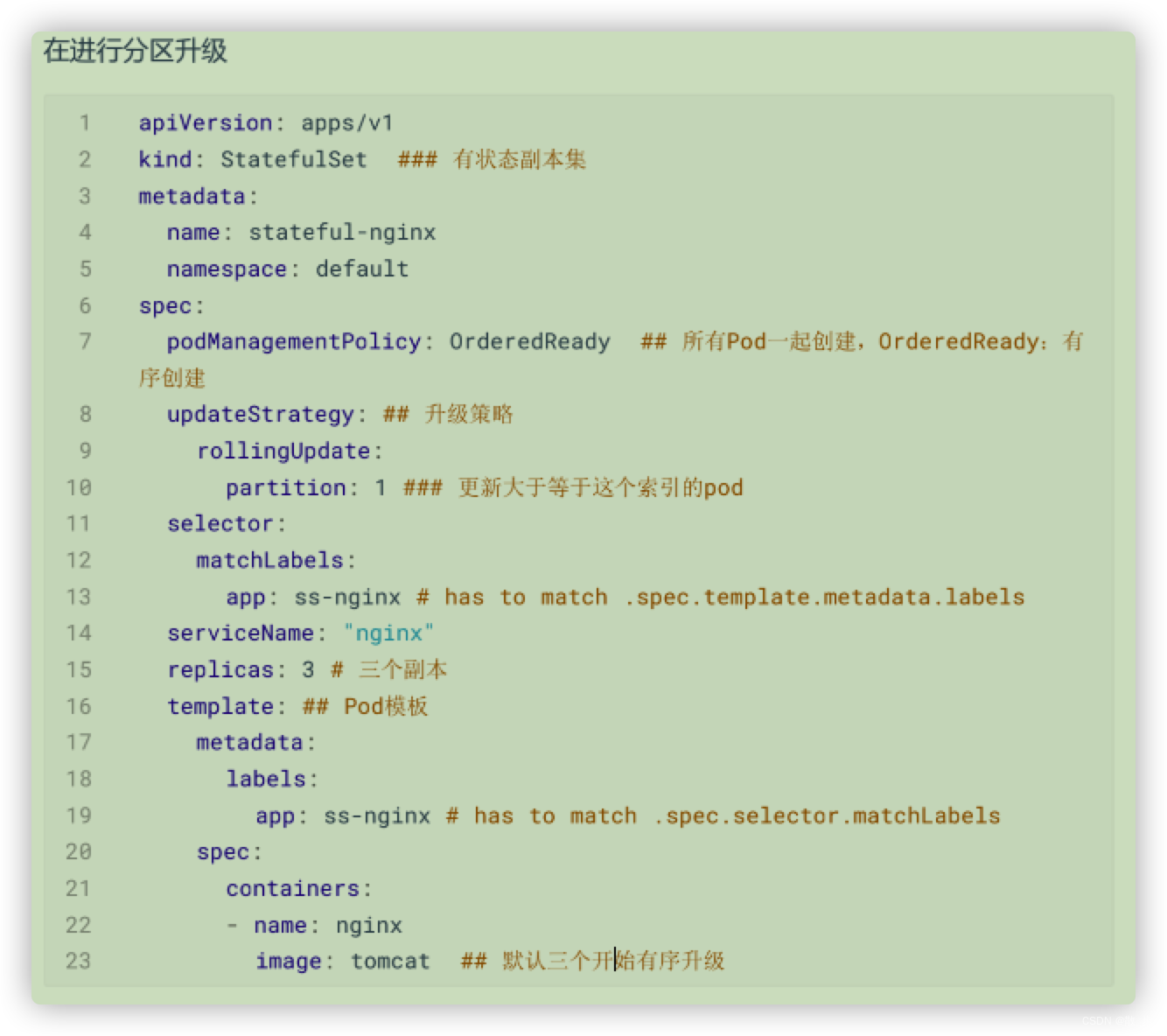
updateStrategy: 更新策略
rollingUpdate:
partition :按分区升级
实验:
Job:
Kubernetes中的 Job 对象将创建一个或多个 Pod,并确保指定数量的 Pod 可以成功执行到进程正常
1.当 Job 创建的 Pod 执行成功并正常结束时,Job 将记录成功结束的 Pod 数量
2.当成功结束的 Pod 达到指定的数量时,Job 将完成执行
3.删除 Job 对象时,将清理掉由 Job 创建的 Pod
apiVersion: batch/v1
kind: Job
metadata:name: job-01
spec:completions: 5 # 前一次必须结束才会下一次parallelism: 3 # 每次并行启动几个template:spec:containers:- name: piimage: busybox # job类型的pod,不要用阻塞式的。如nginx。Deployment才应该是阻塞式的command: ["/bin/sh","-c","ping -c 10 baidu.com"]restartPolicy: Never #Job情况下,不支持Always# backoffLimit: 4 #任务4次都没成,认为失败# activeDeadlineSeconds: 600 # 整个Job的存活时间,超出就自动杀死# ttlSecondsAfterFinished: 10 # 运行完成后自己删除
#默认这个任务需要成功执行一次。
#查看job情况
kubectl get job
#修改下面参数设置再试试
#千万不要用阻塞容器。nginx。job由于Pod一直running状态。下一个永远得不到执行,而且超时了,当前running的Pod还会删掉
activeDeadlineSeconds:10 总共维持10s#该字段限定了 Job 对象在集群中的存活时长,一旦达到 .spec.activeDeadlineSeconds 指定的时长,#该 Job 创建的所有的 Pod 都将被终止。但是 Job不会删除,Job需要手动删除,或者使用ttl进行清理
backoffLimit: #设定 Job 最大的重试次数。该字段的默认值为 6;一旦重试次数达到了 backoffLimit 中的值,Job 将被标记为失败,且尤其创建的所有 Pod 将被终止
completions: #Job结束需要成功运行的Pods。默认为1
manualSelector: parallelism: #并行运行的Pod个数,默认为1
ttlSecondsAfterFinished: (Time To Live) ttlSecondsAfterFinished: 0 #在job执行完时马上删除 ttlSecondsAfterFinished: 100 #在job执行完后,等待100s再删除
#除了 CronJob 之外,TTL 机制是另外一种自动清理已结束Job(Completed 或 Finished)的方式:
#TTL 机制由 TTL 控制器 提供,ttlSecondsAfterFinished 字段可激活该特性
#当 TTL 控制器清理 Job 时,TTL 控制器将删除 Job 对象,以及由该 Job 创建的所有Pod对象。# job超时以后 已经完成的不删,正在运行的Pod就删除
#单个Pod时,Pod成功运行,Job就结束了
#如果Job中定义了多个容器,则Job的状态将根据所有容器的执行状态来变化。
#Job任务不建议去运行nginx,tomcat,mysql等阻塞式的,否则这些任务永远完不了。
##如果Job定义的容器中存在http server、mysql等长期的容器和一些批处理容器,则Job状态不会 发生变化(因为长期运行的容器不会主动结束)。
#此时可以通过Pod的.status.containerStatuses 获取指定容器的运行状态。manualSelector:#job同样可以指定selector来关联pod。需要注意的是job目前可以使用两个API组来操作,#batch/v1和extensions/v1beta1。当用户需要自定义selector时,使用两种API组时定义的#参数有所差异#使用batch/v1时,用户需要将jod的spec.manualSelector设置为true,才可以定制#selector。默认为false。#使用extensions/v1beta1时,用户不需要额外的操作。因为extensions/v1beta1的 spec.autoSelector默认为false,#该项与batch/v1的spec.manualSelector含义正好相反。换#句话说,使用extensions/v1beta1时,用户不想定制selector时,需要手动将#spec.autoSelector设置为true。CronJob:
CronJob创建Job-----Job启动Pod执行命令
CronJob 按照预定的时间计划(schedule)创建 Job(注意:启动的是Job不是Deploy,rs)。一个
CronJob 对象类似于 crontab (cron table) 文件中的一行记录。该对象根据 Cron 格式定义的时间计
划,周期性地创建 Job 对象
Schedule
所有 CronJob 的 schedule 中所定义的时间,都是基于 master 所在时区来进行计算的。
一个 CronJob 在时间计划中的每次执行时刻,都创建 大约 一个 Job 对象。这里用到了 大约 ,是
因为在少数情况下会创建两个 Job 对象,或者不创建 Job 对象。尽管 K8S 尽最大的可能性避免这
种情况的出现,但是并不能完全杜绝此现象的发生。因此,Job 程序必须是 幂等的。1min 执行一
次。
apiVersion: batch/v1beta1
kind: CronJob
metadata:name: hello
spec:schedule: "*/1 * * * *" #分、时、日、月、周jobTemplate:# kind: Jobspec: ## 以下是Job的写法template:spec:containers:- name: helloimage: busyboxargs:- /bin/sh- -c- date; echo Hello from the Kubernetes clusterrestartPolicy: OnFailure
当以下两个条件都满足时,Job 将至少运行一次:
startingDeadlineSeconds: 被设置为一个较大的值,或者不设置该值(默认值将被采纳)
concurrencyPolicy 被设置为 Allow


GC:

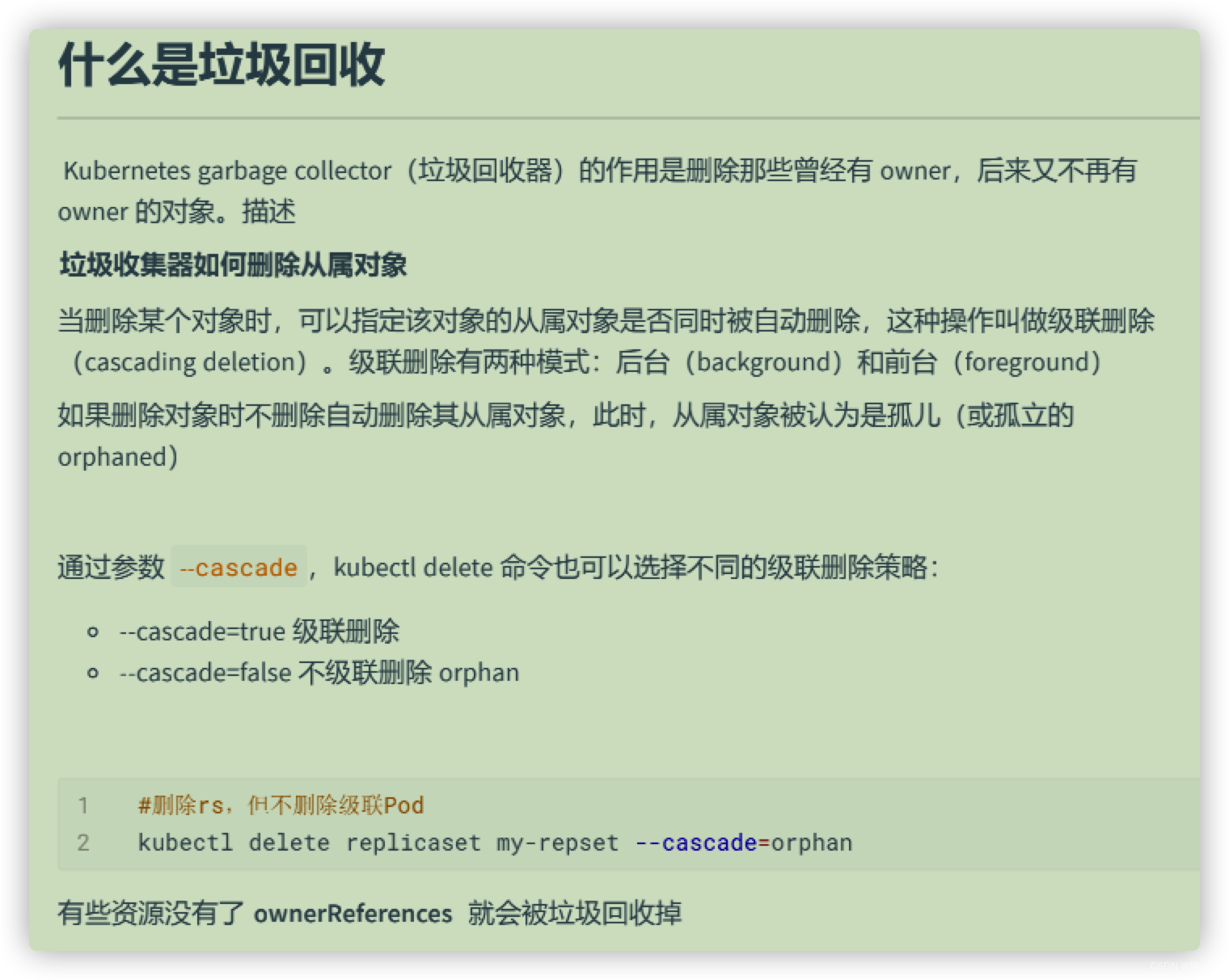
这篇关于K8S RC RS DaemonSet StatefulSet Job CronJob的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






