本文主要是介绍Pytorch之RepVGG图像分类,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、RepVGG
- 1.RepVGG 模型定义
- 2.RepVGG Block 结构
- 3.单分支模型的优势
- 🎆速度快
- 🎆节省内存
- 🎆灵活
- 4.structural re-parameterization结构重参数化
- ✨结构重参数化引入(ACNet)
- ✨Conv+BN层融合
- ✨Conv_3x3和Conv_1x1合并
- ✨identity分支(BN)转化为3x3卷积层
- ✨多分支融合
- 二、RepVGG网络结构
- 结束语
- 💂 个人主页:风间琉璃
- 🤟 版权: 本文由【风间琉璃】原创、在CSDN首发、需要转载请联系博主
- 💬 如果文章对你有
帮助、欢迎关注、点赞、收藏(一键三连)和订阅专栏哦
前言
RepVGG是一个简单的网络结构,它通过堆叠RepVGG Block来构建整个网络,在2021 年发布在CVPR的一篇论文Making VGG-style ConvNets Great Again提出来的,使用structural re-parameterization(结构重参数化)的方式让类VGG的架构重新获得了更好的性能和更快的速度。
RepVGG核心思想是:通过结构重参数化思想,让训练网络的多路结构(多分支模型训练时——性能高)转换为推理网络的单路结构(模型推理时——速度快、省内存)),结构中均为3x3的卷积核,同时,计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,最终可以使网络有着高效的推理速率。在TensorRT在构建engine阶段,对模型进行重构,应用了卷积合并,多分支融合思想,来使得模型最终有着高性能的推理速率。
主要贡献在于:
∙ \bullet ∙ 提出了一种简单而强有力的 CNN 架构 RepVGG,相比 EfficientNet、RegNet 等架构,RepVGG 具有更佳的精度-速度均衡;
∙ \bullet ∙ 提出采用重参数化技术对 plain 架构进行训练-推理解耦;
∙ \bullet ∙ 在图像分类、语义分割等任务上验证了 RepVGG 的有效性。
RepVGG打破了常规工作思路:train model -> deploy model,转换为:train model -> redefine model -> deploy model
一、RepVGG
1.RepVGG 模型定义
VGG 式网络结构通常是指
∙ \bullet ∙ 没有任何分支结构,即通常所说的 plain 或 feed-forward 架构。
∙ \bullet ∙ 仅使用3x3类型的卷积。
∙ \bullet ∙ 仅使用 ReLU 作为激活函数。
VGG 式极简网络结构的五大优势:
✨3x3 卷积非常快。现有的计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,相比其他卷积核,3x3卷积计算密度更高,更加有效。在GPU上,3x3 卷积的计算密度(理论运算量除以所用时间)可达 1x1 和 5x5 卷积的四倍。
✨单路架构非常快,因为并行度高。同样的计算量,“大而整”的运算效率远超“小而碎”的运算。已有研究表明:并行度高的模型要比并行度低的模型推理速度更快。
✨单路架构省内存。ResNet 的 shortcut 虽然不占计算量,却增加了一倍的显存占用。
✨单路架构灵活性更好,容易改变各层的宽度(如剪枝)。
✨RepVGG 主体部分只有一种算子:3x3 卷积接 ReLU。在设计专用芯片时,给定芯片尺寸或造价,可以集成海量的 3x3 卷积-ReLU 计算单元来达到很高的效率,同时单路架构省内存的特性也可以帮我们少做存储单元。
RepVGG模型的基本架构:将多层3x3卷积层堆叠起来,分成5个 stage,每个 stage 的第一层是stride=2的降采样,每个卷积层用 ReLU 作为激活函数。
2.RepVGG Block 结构
第一次出现多分支结构应该是在Inception中,就获得了高性能收益,加上不同分支应用不同卷积核,能获得不同感受野,并行多个分支一般能够增加模型的表征能力,后续出现的ResNet,其残差结构也是多路结构。但是需要注意的是:多路结构需要保存中间结果,显存占有量会明显增高,只有到多路融合时,显存会会降低。
RepVGG的设计是受ResNet启发得到,尽管多分支结构以对于推理不友好,但对于训练友好,本文作者提出一种新思想:训练一个多分支模型,推理时将多分支模型等价转换为单路模型。参考 ResNet 的identity与1x1分支,设计了如下卷积模块:
y = x + g ( x ) + f ( x ) y = x + g(x) + f(x) y=x+g(x)+f(x)其中, x , g ( x ) , f ( x ) x,g(x),f(x) x,g(x),f(x)分别对应恒等映射,1x1卷积,3x3卷积。即在训练时,为每一个 3x3 卷积层添加平行的 1x1 卷积分支和恒等映射分支,构成一个 RepVGG Block。
这种设计是借鉴 ResNet 的做法,区别在于ResNet 是每隔两层或三层加一分支,RepVGG 模型是每层都加两个分支(训练阶段)。
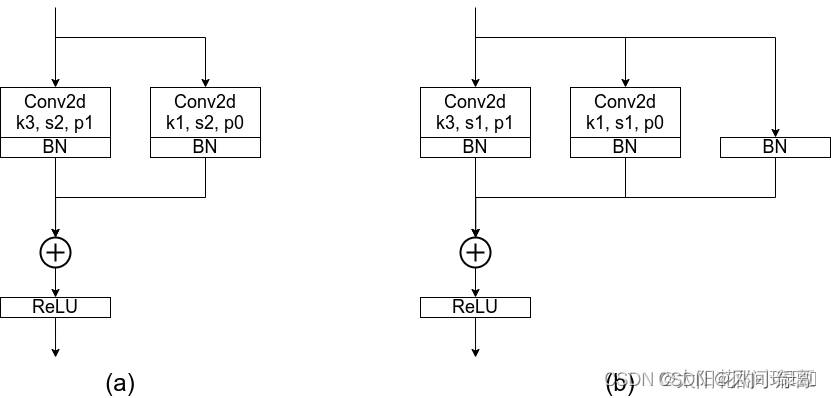
图(a)是进行下采样(stride=2)时使用的RepVGG Block结构,图(b)是正常的(stride=1)RepVGG Block结构。通过图(b)可以看到训练时RepVGG Block并行了三个分支:一个卷积核大小为3x3的主分支,一个卷积核大小为1x1的shortcut分支以及一个只连了BN的shortcut分支。
训练阶段,通过简单的堆叠上述 RepVGG Block 构建 RepVGG 模型;而在推理阶段,上述模块转换成 y = h ( x ) y = h(x) y=h(x)形式, h ( x ) h(x) h(x)的参数可以通过线性组合方式从训练好的模型中转换得到,如下图(c)所示。下面我们来说说为什么在推理阶段要将多分支模型转换成单路模型?
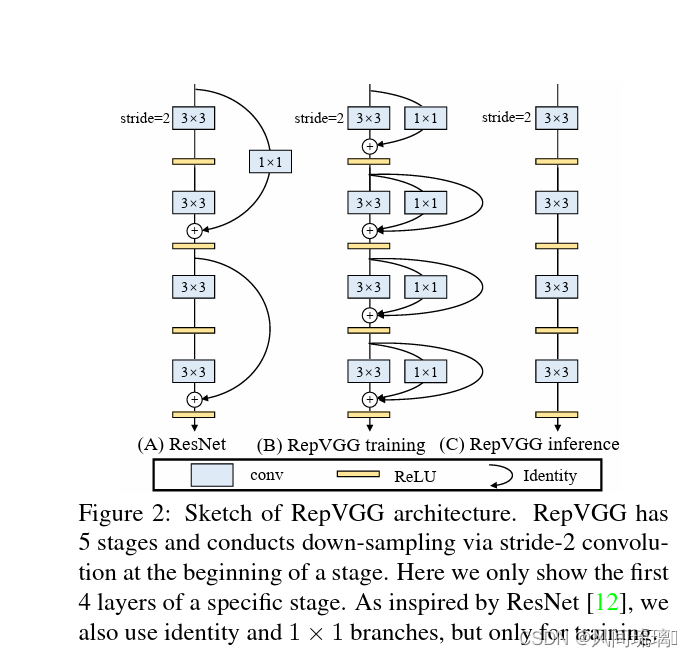
3.单分支模型的优势
从上面了解到,RepVGG 在推理时要将多分支模型转换成单路模型,因为采用单路模型会更快、更省内存并且更加的灵活。而基于多分支结构设计,如残差网络add,Inception系列中的concat操作,多分支结构会增加推理时间,增加显存消耗,因为需要保存各个分支的结果,直到add/concat操作后,显存才会减少。
推理时作者要将多分支模型转换成单路模型(也是VGGPlain结构的优势)以下优势:
🎆速度快
VGG网络几乎都是由3x3卷积构成,现有的计算库(如CuDNN,Intel MKL)和硬件针对3x3卷积有深度的优化,相比其他卷积核,3x3卷积计算密度更高,更加有效。
同时考虑到模型在推理时硬件计算的并行程度以及MAC(memory access cost)。对于多分支模型,硬件需要分别计算每个分支的结果,不同的分支一般计算时间不一样,只有等全部分支都计算完后才能做进一步融合,这样会导致硬件算力不能充分利用,或者说并行度不够高。而且每个分支都需要去访问一次内存,计算完后还需要将计算结果存入内存(不断地访问和写入内存会在IO上浪费很多时间)。
MAC(memory access cost)内存访问次数,也叫内存使用量,CNN 网络中每个网络层 MAC 的计算分为读输入 feature map 大小、权重大小(DDR 读)和写输出 feature map 大小(DDR 写)三部分。
以卷积层为例计算 MAC,可假设某个卷积层输入 feature map 大小是 (Cin, Hin, Win),输出 feature map 大小是 (Hout, Wout, Cout),卷积核是 (Cout, Cin, K, K)。feature map 大小一般表示为 (N, C, H, W),MAC 指标一般用在端侧模型推理中,端侧模型推理模式一般都是单帧图像进行推理,即 N = 1(batch_size = 1),不同于模型训练时的 batch_size 大小一般大于 1。
input = Hin x Win x Cin # 输入 feature map 大小
output = Hout x Wout x Cout # 输出 feature map 大小
weights = K x K x Cin x Cout + bias # bias 是卷积层偏置
ddr_read = input + weights
ddr_write = output
MAC = ddr_read + ddr_write
🎆节省内存
如图(A)所示的Residual模块是一个多分支结构,其分支结构需要消耗显存的,因为各个分支的结果需要保存,直到最后一步融合(比如add),才能把各分支显存释放掉。而图(B)的Plain结构占用内存始终不变,单路结构会占有更少的内存,因为不需要保存其中间结果。同时,单路架构非常快,因为并行度高。同样的计算量,大而整的运算效率远超小而碎的运算。
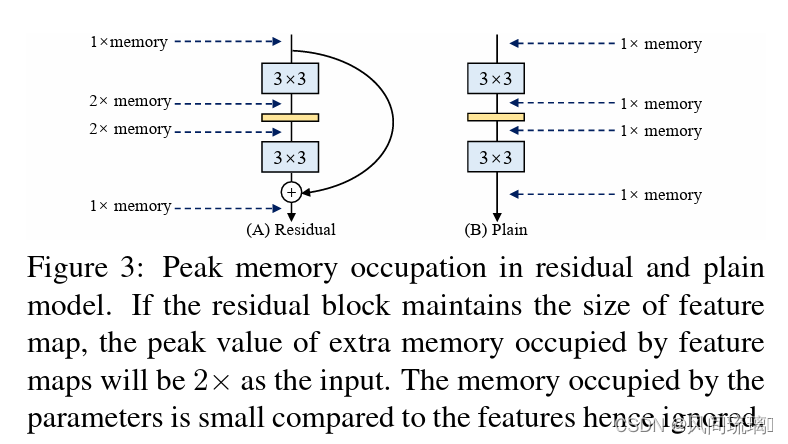
🎆灵活
作者在论文中提到了模型优化的剪枝问题,对于多分支的模型,结构限制较多剪枝很麻烦,而对于Plain结构的模型就相对灵活很多,剪枝也更加方便。
4.structural re-parameterization结构重参数化
基于上述,要想要使网络具有高性能,又要有高效推理速度,作者提出结构重参数化思想,在训练时使用多分支结构来增加模型的表征能力,在推理时采用利用结构重参数化思想,将多分支转化成单路模型,这样显存占用少,推理速度又快。
✨结构重参数化引入(ACNet)
首先得理解卷积计算的恒等式,它是结构重参数化思想的理论基础,卷积计算的恒等式的示意图如下图所示。
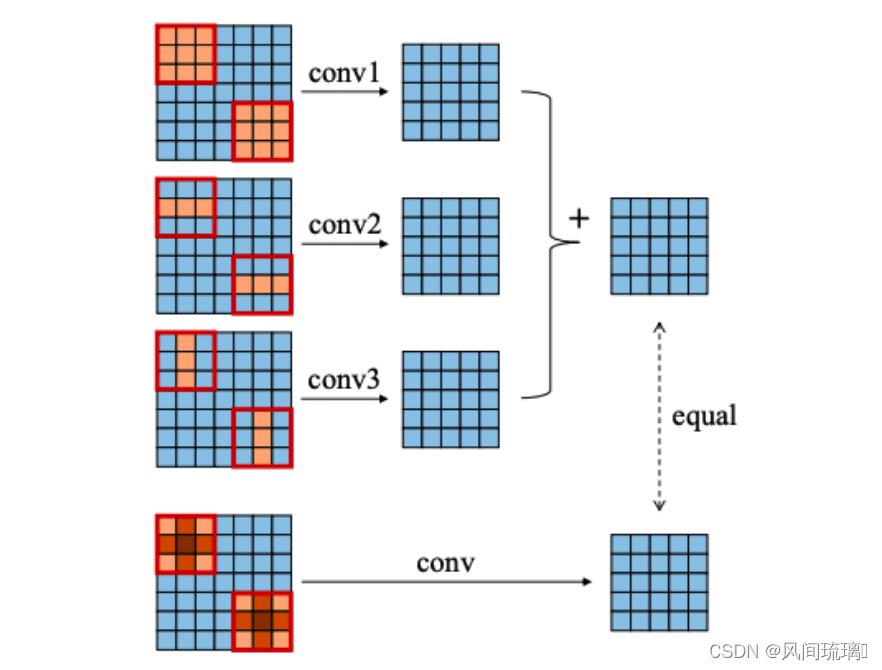
结构重参数化(structural re-parameterization) 指的是首先构造一系列结构(一般用于训练),并将其参数等价转换为另一组参数(一般用于推理),从而将这一系列结构等价转换为另一系列结构。
卷积计算的恒等式如下:
I ∗ K ( 1 ) + I ∗ K ( 2 ) = I ∗ ( K ( 1 ) + K ( 2 ) ) I*K^{(1)} + I*K^{(2)} = I*(K^{(1)} + K^{(2)}) I∗K(1)+I∗K(2)=I∗(K(1)+K(2))上面等式表达的意思是对应输入特征图 I I I,先进行 K ( 1 ) K^{(1)} K(1)和 I I I卷积、 K ( 2 ) K^{(2)} K(2)和 I I I卷积,再对结果进行相加。与先进行 K ( 1 ) K^{(1)} K(1)和 K ( 2 ) K^{(2)} K(2)的逐点相加后再和 I I I进行卷积得到的结果是一致的。
这是网络模型在推理阶段不增加任何计算量的理论基础,训练阶段计算量增加,训练时间更长,需要的显存更大。以上来自ACNet网络论文中的思想。
ACNet 的创新分为训练和推理阶段:
∙ \bullet ∙ 训练阶段:将现有网络中的每一个3x3卷积层换成3x1卷积 + 1x3卷积 + 3x3卷积共三个卷积层,并将三个卷积层的计算结果进行相加得到最终卷积层的输出。因为这个过程引入的1x3卷积和3x1卷积是非对称的,所以将其命名为Asymmetric Convolution。引入这样的水平卷积核可以提升模型对图像上下翻转的鲁棒性,竖直方向的卷积核同理。
∙ \bullet ∙ 推理阶段:主要是对三个卷积核进行融合,这部分在实现过程中就是使用融合后的卷积核参数来初始化现有的网络。
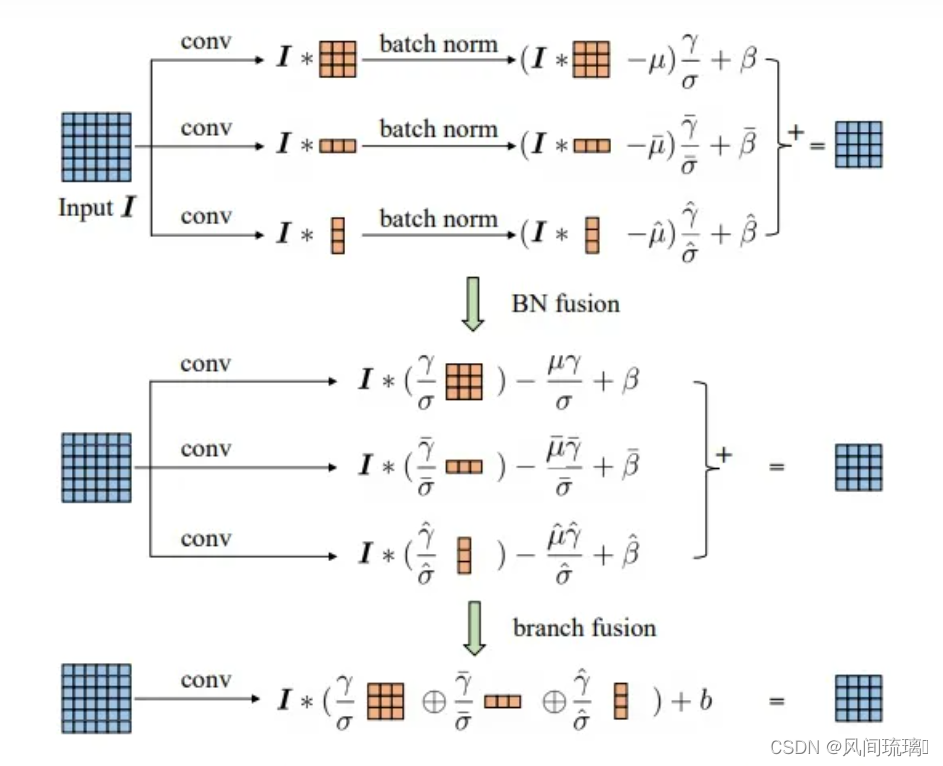
推理阶段的卷积融合操作是和 BN 层一起的,融合操作发生在 BN 之后,论文实验证明融合在 BN 之后效果更好些。推理阶段卷积层融合操作示意图如上所示(BN 操作省略了 ϵ \epsilon ϵ)
✨Conv+BN层融合
训练时使用多分支卷积结构,推理时将多分支结构进行融合转换成单路3x3卷积层,由卷积的线性(可加性)原理,每个 RepVGG Block 的三个分支可以合并为一个3x3卷积层(等价转换),如下图详细描绘了这一转换过程。
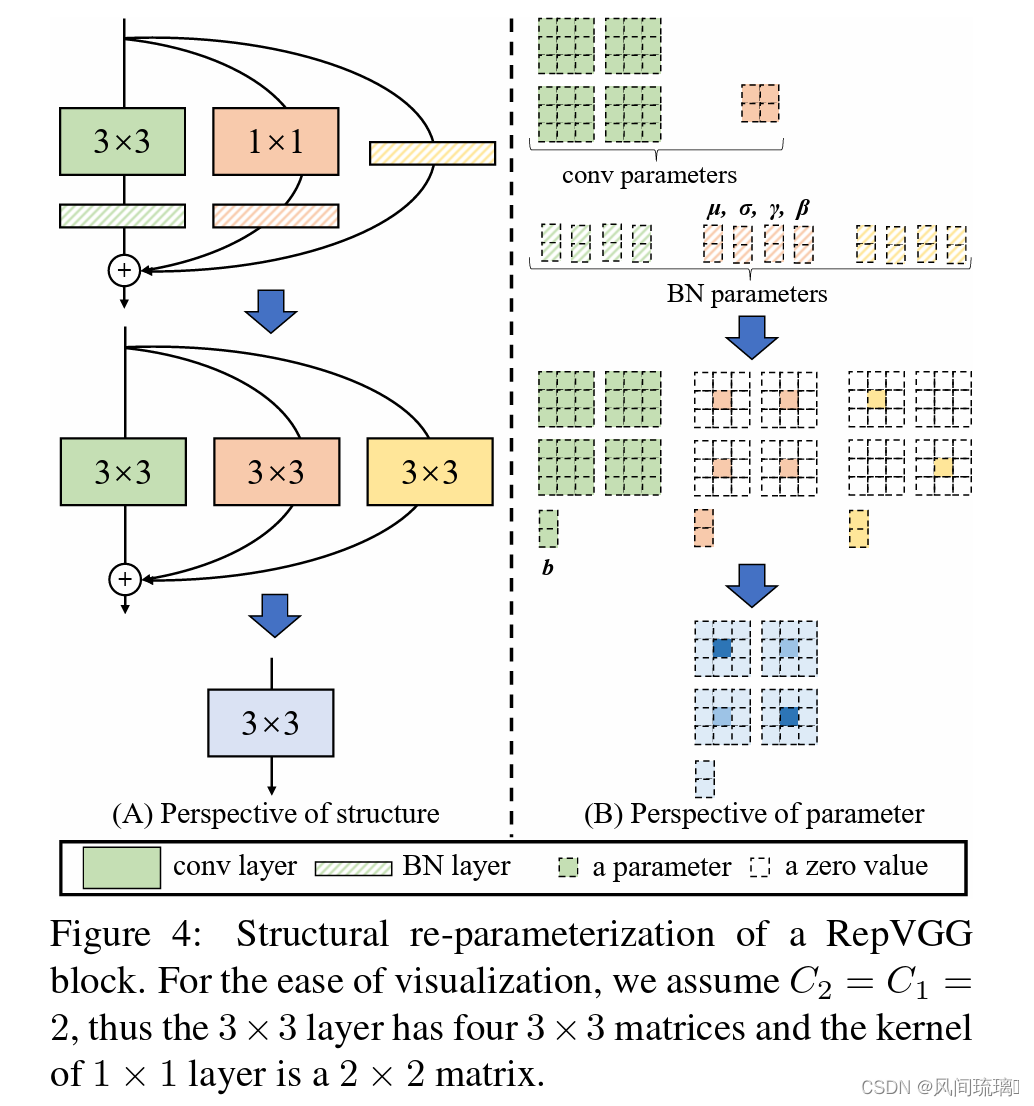
根据上图左侧可以看到,结构重参数化主要分为两步:
∙ \bullet ∙ 将Conv2d算子和BN算子融合以及将只有BN的分支转换成一个Conv2d算子
∙ \bullet ∙ 将每个分支上的3x3卷积层融合成一个卷积层。
因为Conv2d和BN两个算子都是线性运算,所以可以融合成一个算子。注意,融合是在网络训练完之后做的,所以默认是推理模式,注意BN在训练以及推理时计算方式是不同的。对于卷积层,每个卷积核的通道数是与输入特征图的通道数相同,卷积核的个数决定了输出特征图的通道个数。
卷积层公式(偏置b存在)为
C o n v ( x ) = W ( x ) + b Conv(x) = W(x) + b Conv(x)=W(x)+b对于BN层(推理模式),主要包含4个参数: μ \mu μ(均值)、 σ 2 \sigma^2 σ2(方差)、 γ \gamma γ和 β \beta β,其中 μ \mu μ和 σ 2 \sigma^2 σ2 是训练过程中统计得到的, γ \gamma γ和 β \beta β是训练学习得到的。对于特征图某一个通道BN的计算公式如下,其中 ϵ \epsilon ϵ是一个非常小的常量,防止分母为零:
B N ( x ) = x − μ σ 2 + ϵ γ + β BN(x) = \frac{x- \mu}{\sqrt{\sigma^2 + \epsilon }} \gamma + \beta BN(x)=σ2+ϵx−μγ+β将卷积层结果带入BN公式(这里忽略了 ϵ \epsilon ϵ)中为
B N ( C o n v ( x ) ) = W ( x ) + b − μ σ 2 γ + β BN(Conv(x)) = \frac{W(x) + b - \mu}{\sqrt{\sigma^2 }} \gamma + \beta BN(Conv(x))=σ2W(x)+b−μγ+β进一步化简为 B N ( C o n v ( x ) ) = W ( x ) ∗ γ σ 2 + ( ( b − μ ) ∗ γ σ 2 + β ) BN(Conv(x)) = \frac{W(x)*\gamma}{\sqrt{\sigma^2 }} + (\frac{(b-\mu)*\gamma}{\sqrt{\sigma^2 }} + \beta) BN(Conv(x))=σ2W(x)∗γ+(σ2(b−μ)∗γ+β)这本质上是一个卷积层,只不过权重和偏置考虑了BN层的参数,令 W f u s e d = W ( x ) ∗ γ σ 2 , B f u s e d = ( b − μ ) ∗ γ σ 2 + β W_{fused} = \frac{W(x)*\gamma}{\sqrt{\sigma^2 }}, \qquad B_{fused} = \frac{(b-\mu)*\gamma}{\sqrt{\sigma^2 }} + \beta Wfused=σ2W(x)∗γ,Bfused=σ2(b−μ)∗γ+β最后融合后新的卷积层计算公式为
B N ( C o n v ( x ) ) = W f u s e d + B f u s e d BN(Conv(x)) = W_{fused} + B_{fused} BN(Conv(x))=Wfused+Bfused
假设输入的特征图(Input feature map)如下图所示,输入通道数为2,然后采用两个卷积核,右侧为其中一个卷积核。
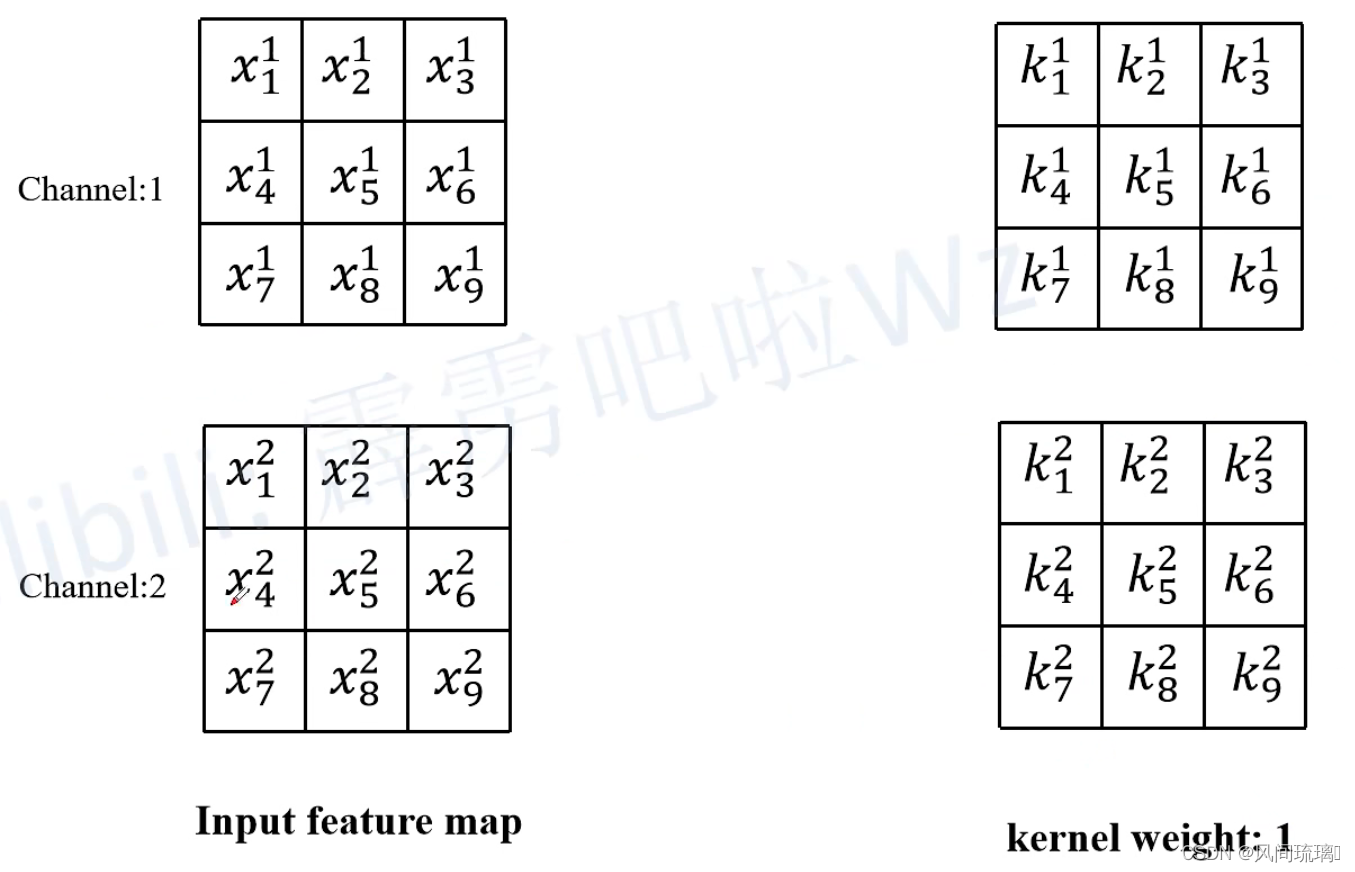
然后计算输出特征图(Output feature map)通道1上的第一个元素,即当卷积核1在输入特征图红色框区域卷积时得到的值(为了保证输入输出特征图高宽不变,所以对Input feature map进行了Padding)。其他位置的计算过程同理。
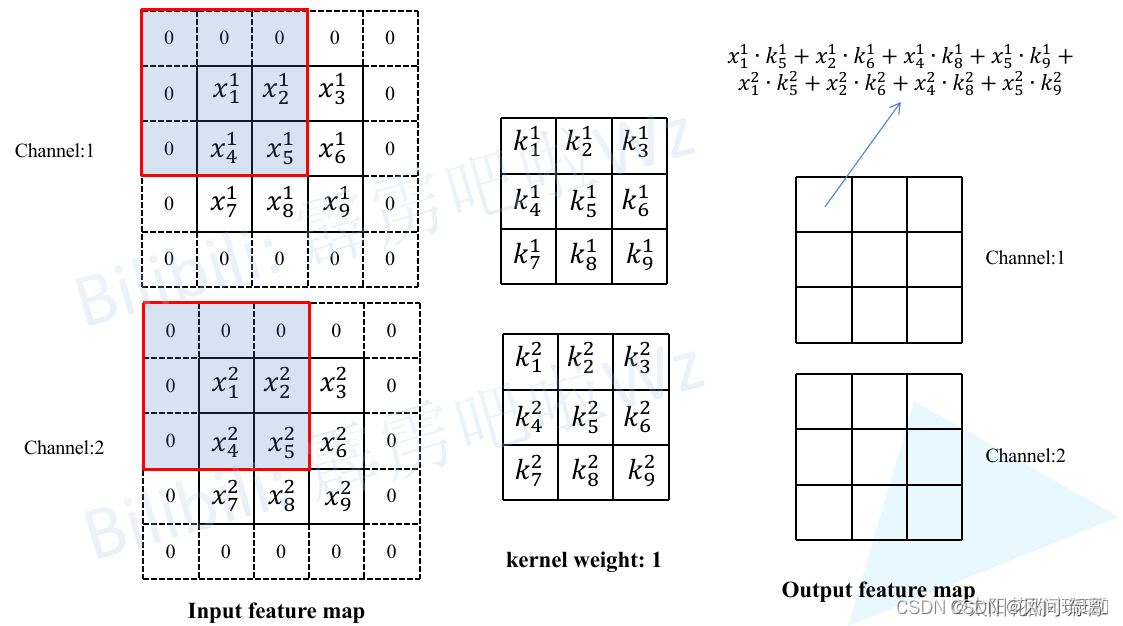
然后再将卷积层输出的特征图作为BN层的输入,这里同样计算一下输出特征图(Output feature map)通道1上的第一个元素,按照上述BN在推理时的计算公式即可得到如下图所示的计算结果。
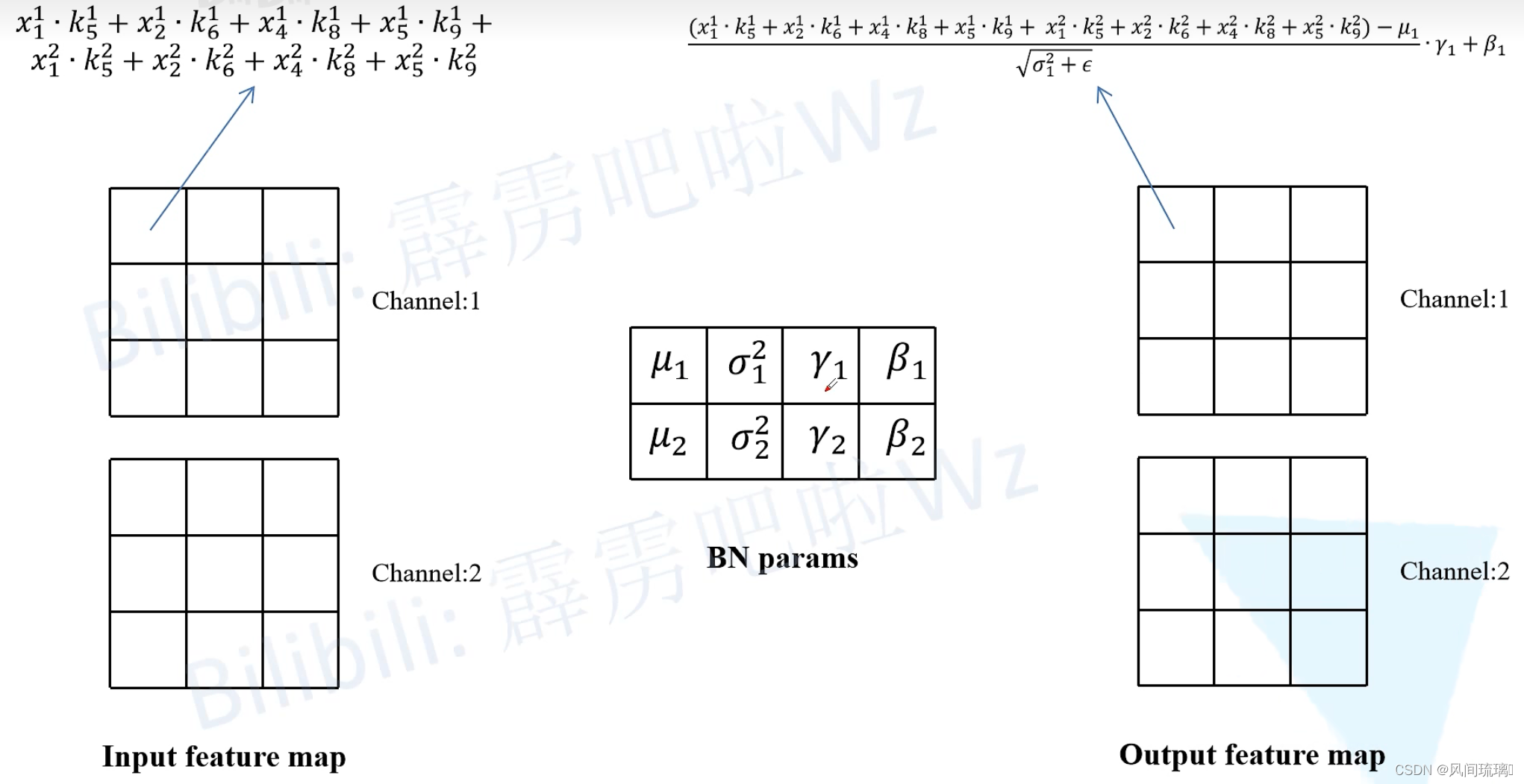
最后对上述计算公式进行简单的变形,可以得到转化后新卷积层只需在对应第i个卷积核的权重上乘以 γ i σ i 2 + ϵ \frac{\gamma_i}{\sqrt{\sigma^2_i+\epsilon}} σi2+ϵγi系数即可,对应第i个卷积核新的偏执就等于 β i − μ i γ i σ i 2 + ϵ \beta_i - \frac{\mu_i \gamma_i}{\sqrt{\sigma^2_i + \epsilon}} βi−σi2+ϵμiγi 。一般采用Conv2d+BN的组合中Conv2d默认是不采用偏执的或者说偏执为零,因为有无偏置,推导结果都是相同的。这里新的卷积层偏置b存在,不为零。

✨Conv_3x3和Conv_1x1合并
假设输入特征图特征图尺寸为(1, 2, 3, 3),输出特征图尺寸与输入特征图尺寸相同,且stride=1,下面展示是conv_3x3的卷及过程:
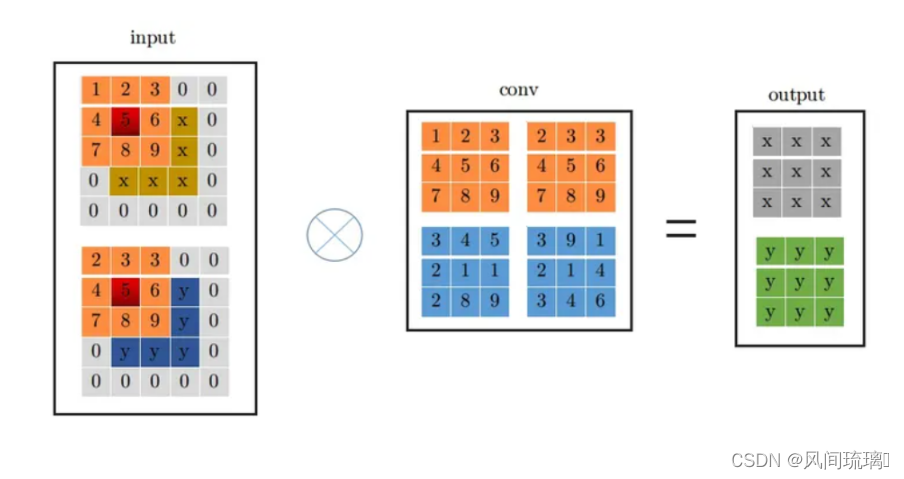
首先将特征图进行pad=kernel_size//2,然后从左上角开始(上图中红色位置)做卷积运算,最终得到右边output输出。
下面是conv_1x1卷积过程:
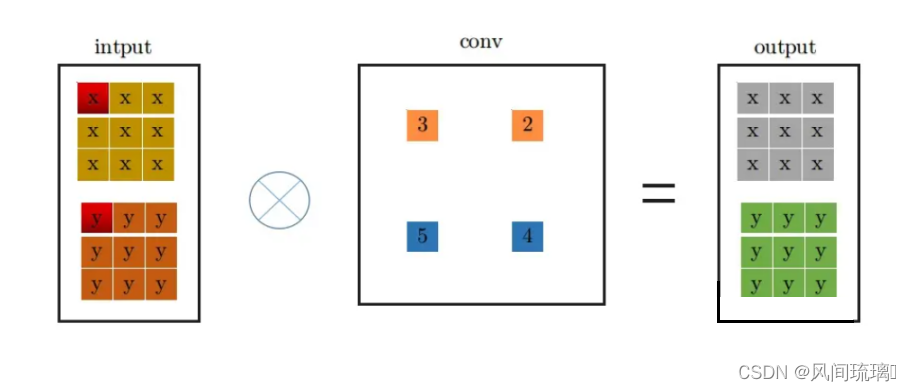
conv_1x1和conv_3x3卷积过程一样,从上图中左边input中红色位置开始进行卷积,得到右边的输出,观察conv_1x1和conv_3x3的卷积过程,可以发现它们都是从input中红色起点位置开始,走过相同的路径,因此,将conv_3x3和conv_1x1进行融合,只需要将conv_1x1卷积核padding成conv_3x3的形式,然后于conv_3x3相加,再与特征图做卷积(这里依据卷积的可加性原理)即可,conv_1x1的卷积过程变成如下形式:
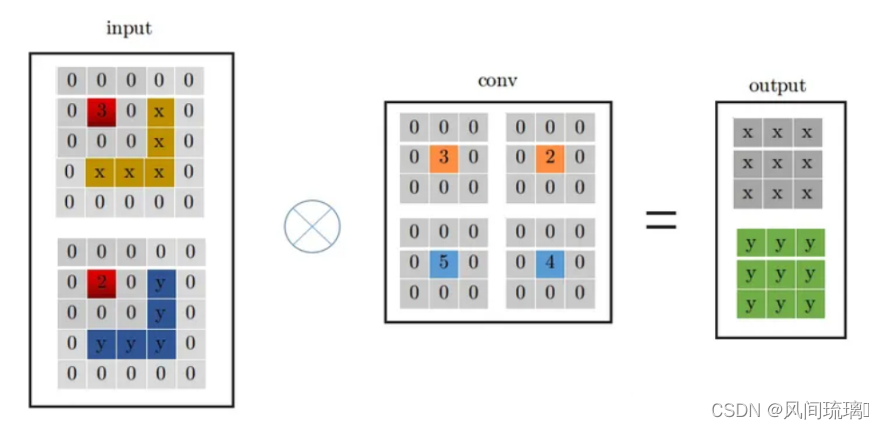
注意为了保证输入输出特征图高宽不变,此时需要将padding设置成1,原来卷积核大小为1x1时padding为0。
✨identity分支(BN)转化为3x3卷积层
identity层是输入直接等于输出,即input中每个通道每个元素直接输出到output中对应的通道。
卷积操作必须涉及要将每个通道加起来然后输出的,然后又要保证input中的每个通道每个元素等于output中,从这一点,可以从PWconv想到,只要令当前通道的卷积核参数为1,其余的卷积核参数为0;从DWconv中可以想到,用conv_1x1卷积且卷积核权重为1,就能保证每次卷积不改变输入,因此,identity可以等效成如下的conv_1x1的卷积形式:
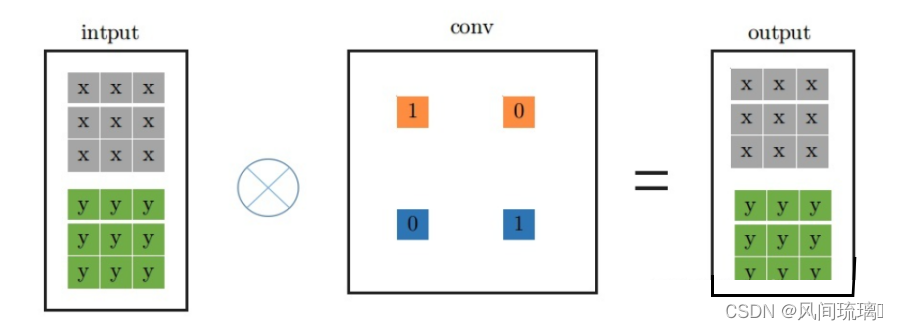
从上面的分析,进一步可以将indentity -> conv_1x1 -> conv_3x3的形式,如下所示:
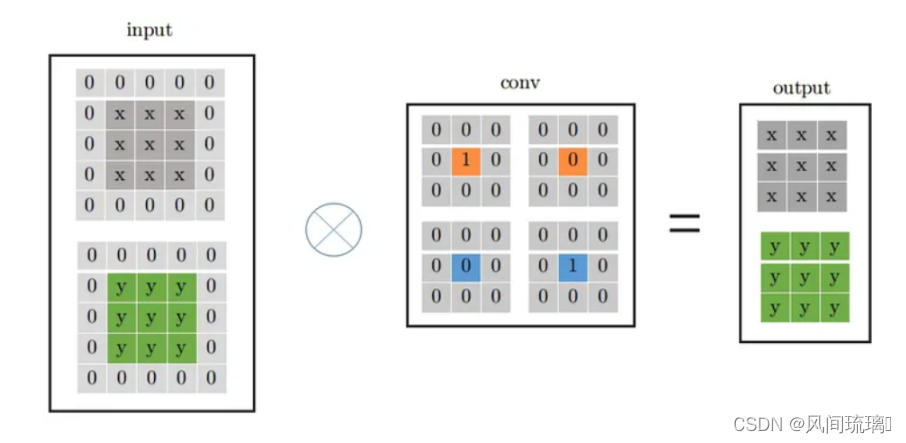
✨多分支融合
上面已经把每个分支融合转换成一个3x3的卷积层,接下来需要进一步将多分支转换成一个单分支3x3卷积层。合并的过程其实很简单,直接将这三个卷积层的参数相加即可,因为卷积的可加性原理。
O = ( I ⨂ K 1 + B 1 ) + ( I ⨂ K 2 + B 2 ) + ( I ⨂ K 3 + B 3 ) \qquad \qquad \quad \color{green} O= (I\bigotimes K_1 + B_1) + (I\bigotimes K_2 + B_2) + (I\bigotimes K_3 + B_3) O=(I⨂K1+B1)+(I⨂K2+B2)+(I⨂K3+B3) = I ⨂ ( K 1 + K 2 + K 3 ) + ( B 1 + B 2 + B 3 ) \color{blue} \quad= I\bigotimes (K_1 + K_2 + K_3) + (B_1 + B_2 + B_3) =I⨂(K1+K2+K3)+(B1+B2+B3)
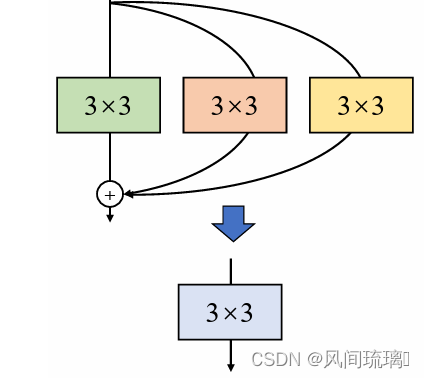
下面来看看结构重参数总体流程:如下图所示
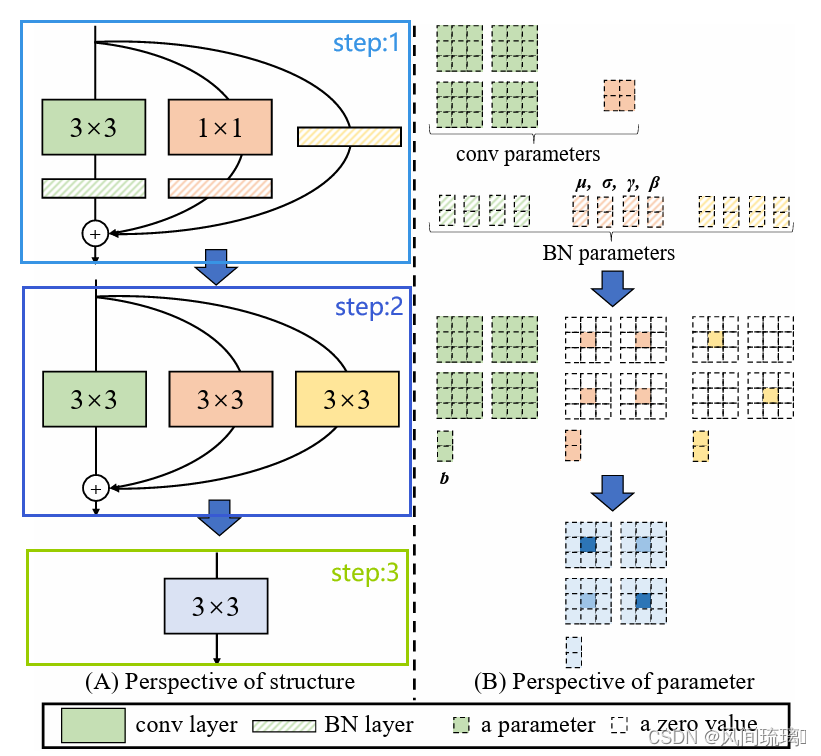 从step1到step2的变换过程,涉及conv和BN层融合,conv_1x1与identity转化为等价的conv_3x3的形式。 结构重参数化的最后一步是上图中step2 -> step3,即多分支融合,这一步主要利用
从step1到step2的变换过程,涉及conv和BN层融合,conv_1x1与identity转化为等价的conv_3x3的形式。 结构重参数化的最后一步是上图中step2 -> step3,即多分支融合,这一步主要利用卷积可加性原理,将三个分支的卷积层权重和偏置对应相加组成最终一个conv3x3的形式即可。
二、RepVGG网络结构
RepVGG进一步细分有RepVGG-A、RepVGG-B以及RepVGG-Bxgy三种版本。
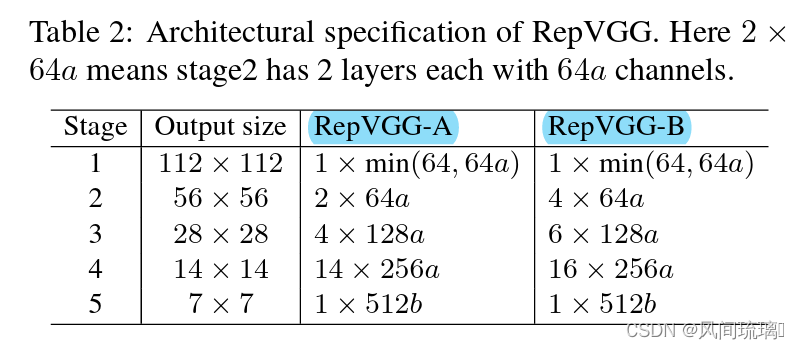
根据Table2可以知道RepVGG-B的网络层数比RepVGG-A更深。这两种配置在每个stage重复block的次数。RepVGG-A中的base Layers of each stage为1, 2, 3, 14, 1,如stage=2时,2x64a代表stage2重复2次数,并且通道数为64a。RepVGG-B中的base Layers of each stage为1, 4, 6, 16, 1。
更加详细的模型配置可以看表3。其中a代表模型stage2~4的宽度缩放因子,b代表模型最后一个stage的宽度缩放因子。
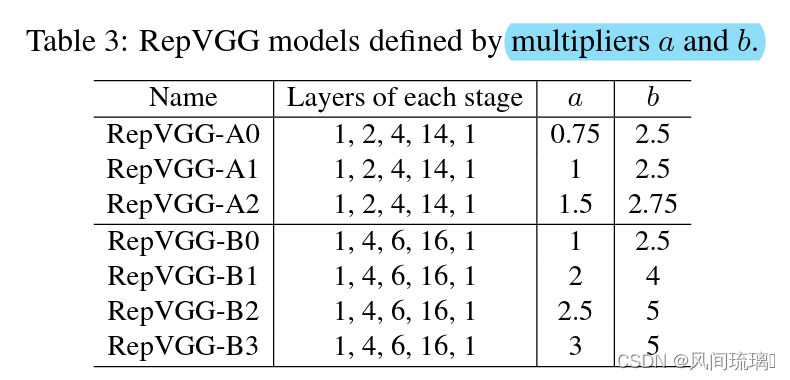
RepVGG-Bxgy这个版本的配置是在RepVGG-B的上加入组卷积(Group Convolution),其中gy表示组卷积采用的groups参数为y。
注意并不是所有卷积层都采用组卷积,根据源码可以看到,是从Stage2开始(索引从1开始)的第2, 4, 6, 8, 10, 12, 14, 16, 18, 20, 22, 24, 26的卷积层采用组卷积。
结束语
感谢阅读吾之文章,今已至此次旅程之终站 🛬。
吾望斯文献能供尔以宝贵之信息与知识也 🎉。
学习者之途,若藏于天际之星辰🍥,吾等皆当努力熠熠生辉,持续前行。
然而,如若斯文献有益于尔,何不以三连为礼?点赞、留言、收藏 - 此等皆以证尔对作者之支持与鼓励也 💞。
这篇关于Pytorch之RepVGG图像分类的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





