本文主要是介绍Aspose.OCR For NET 23.5 Crack,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用几行代码将光学字符识别 (OCR) 添加到您的 .NET 应用程序。
适用于 .NET 的 Aspose.OCRAspose.OCR 文档
Aspose.OCR for .NET 是一个功能强大但易于使用且具有成本效益的光学字符识别 API。有了它,您可以用不到 5 行代码将 OCR 功能添加到您的 .NET 应用程序中,而不必担心复杂的数学、神经网络和其他技术细节。我们在机器学习技术方面的经验和多年的发展造就了具有卓越速度和准确性的 OCR 引擎,支持基于拉丁文和西里尔文字以及中文的27 种语言. OCR API 可以识别扫描图像、智能手机照片、屏幕截图、图像区域和扫描 PDF,并以最流行的文档和数据交换格式返回结果。各种预处理过滤器可让您识别旋转、倾斜和嘈杂的图像。通过将资源密集型计算任务转移到GPU,可以进一步提高识别性能和系统负载。

Aspose.OCR for .NET 的特性和功能
将图像和 PDF 转换为文本支持您可以从扫描仪或照相机获得的所有图像格式阅读基于拉丁文和西里尔文的语言识别6000多个汉字检测并识别所有流行的字体小心保留字体样式和格式仅处理整个图像或选定区域支持旋转、倾斜和嘈杂的图像批量识别文件夹或档案中的所有图像识别作为网络链接提供的图像查找并自动更正拼写错误的单词与其他 Aspose 产品完全兼容易于安装
Aspose.OCR for .NET 作为轻量级 NuGet 包或作为具有最小依赖性的可下载文件分发。只需将它安装到您的项目中,您就可以识别任何支持的语言的文本,并以任何支持的格式保存识别结果。
便于使用
您需要三行代码来识别图像并显示结果。是的,真的就是这么简单!
跨平台
该库完全支持 .NET Standard 2.0。这意味着应用程序可以在任何平台上运行:桌面 Windows、Windows Server、macOS、Linux 和云。
27种识别语言
OCR API 可以识别大量语言和所有流行的书写脚本,包括混合语言的文本。
扩展拉丁字母表:克罗地亚语、捷克语、丹麦语、荷兰语、英语、爱沙尼亚语、芬兰语、法语、德语、意大利语、拉脱维亚语、立陶宛语、挪威语、波兰语、葡萄牙语、罗马尼亚语、斯洛伐克语、斯洛文尼亚语、西班牙语、瑞典语。
西里尔字母:白俄罗斯语、保加利亚语、哈萨克语、俄语、塞尔维亚语、乌克兰语。
中文:6000多个字。
您可以将语言检测留给库或自己定义语言以提高识别性能和可靠性。
识别照片
OCR 应用程序的最大障碍是扫描仪对最终用户而言并不常见。API 具有强大的内置图像预处理过滤器,可以处理旋转、倾斜和嘈杂的图像。结合对所有图像格式的支持,它甚至可以可靠地识别智能手机照片。大多数预处理和图像校正都是自动完成的,因此您只需要在困难的情况下进行干预。
应用自动图像校正 - C#
Aspose.OCR.RecognitionResult result = recognitionEngine.RecognizeImage("IMG_20220622_163123.jpg", recognitionSettings);
通用转换器
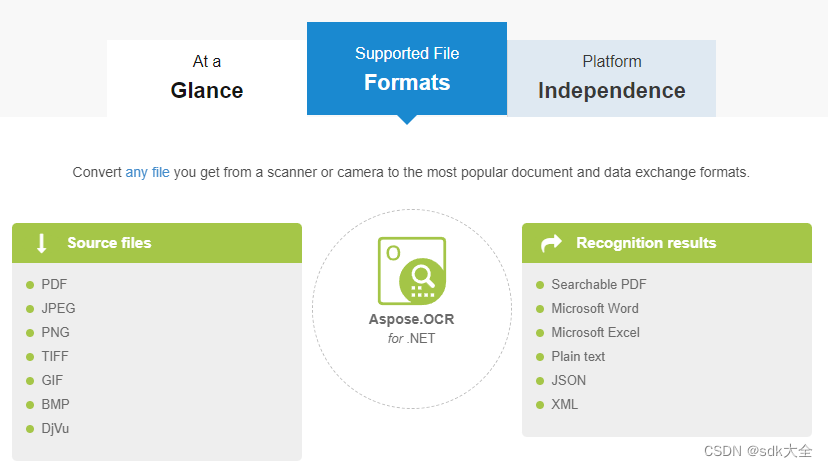
API 几乎可以读取您从扫描仪、相机或智能手机获得的任何图像:PDF 文档、JPEG、PNG、TIFF、GIF、BMP 图像,甚至 DjVu 文件。完全支持多页 PDF 文档、TIFF 和 DjVu 图像。您还可以通过 URL 提供来自 Web 的图像。
识别结果以最流行的文档和数据交换格式返回:纯文本、PDF、Microsoft Word、Microsoft Excel、JSON 和 XML。
资源优化
光学字符识别是一个资源密集型过程。API 提供了非常灵活的方法来在经典的时间-价格-质量三元组中取得平衡:
在彻底识别和快速识别之间进行选择。
指定为识别分配的线程数,或允许库自动扩展到处理器内核的数量。
通过将计算卸载到 GPU 来释放 CPU。
批量处理
OCR API 提供各种批处理方法,让您可以在一次调用中识别多张图像,从而使您无需逐一识别每张图像:
识别多页 PDF、TIFF 和 DjVu 文件。
识别文件夹中的所有文件。
识别档案中的所有文件。
识别列表中的所有文件。
这篇关于Aspose.OCR For NET 23.5 Crack的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!