本文主要是介绍曼孚科技:三分钟读懂何为“数据标注”,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作为人工智能三大决定性影响因素,算法、算力与数据,一直是行业研究的重中之重。
然而,相比于算法与算力,数据领域受到的关注度显然少了很多。尤其是数据标注行业,作为人工智能产业的基石,与处在聚光灯下的AI整体行业相比,显得那么粗砺与拙朴。
不过,随着时代的发展,这种情况出现了很大的改观,数据标注的重要性越来越得到整个AI行业的认可。AI对数据的质量、规模和场景化方面的要求越来越高,精细化、领域化成为了标注数据的新标准。
1.什么是数据标注
数据标注是AI行业的一个分支。目前的人工智能算法由数据驱动,一个好的模型需要质量优异的数据资源做支撑。
想要了解什么是数据标注,就得先理解人工智能的目标:机器代替人的认知与思考。
回想一下我们在小的时候是如何认知这个世界的,比如汽车。当我们第一次见到汽车这个物体时,我们并不知道它叫什么有什么用。我们的父母会告诉我们,这个东西读作“汽车”,它是这样的形状,并且能够行驶。
类比机器学习。我们要让机器明白什么是汽车,只能给机器一张汽车的图片,标注出汽车轮廓,并标记上名字“汽车”,这个时候机器就能识别出这张图片里的汽车了。
然而,相比如人类,机器并不具备思考与联想的能力。换一张图片之后,机器可能就识别不出来里面的“汽车”了。怎么办?这个时候需要给机器大量标注好的图片,让机器找到这些图片里汽车的共同特征,那么以后就可以识别出其他汽车了。
简单来说:数据标注就是通过数据标注员借助标注工具,对人工智能学习数据进行加工的一种行为。
2.数据标注工具有哪些
数据标注的基本数据类型包括文本、图片、视频、语音、数值型数据等。
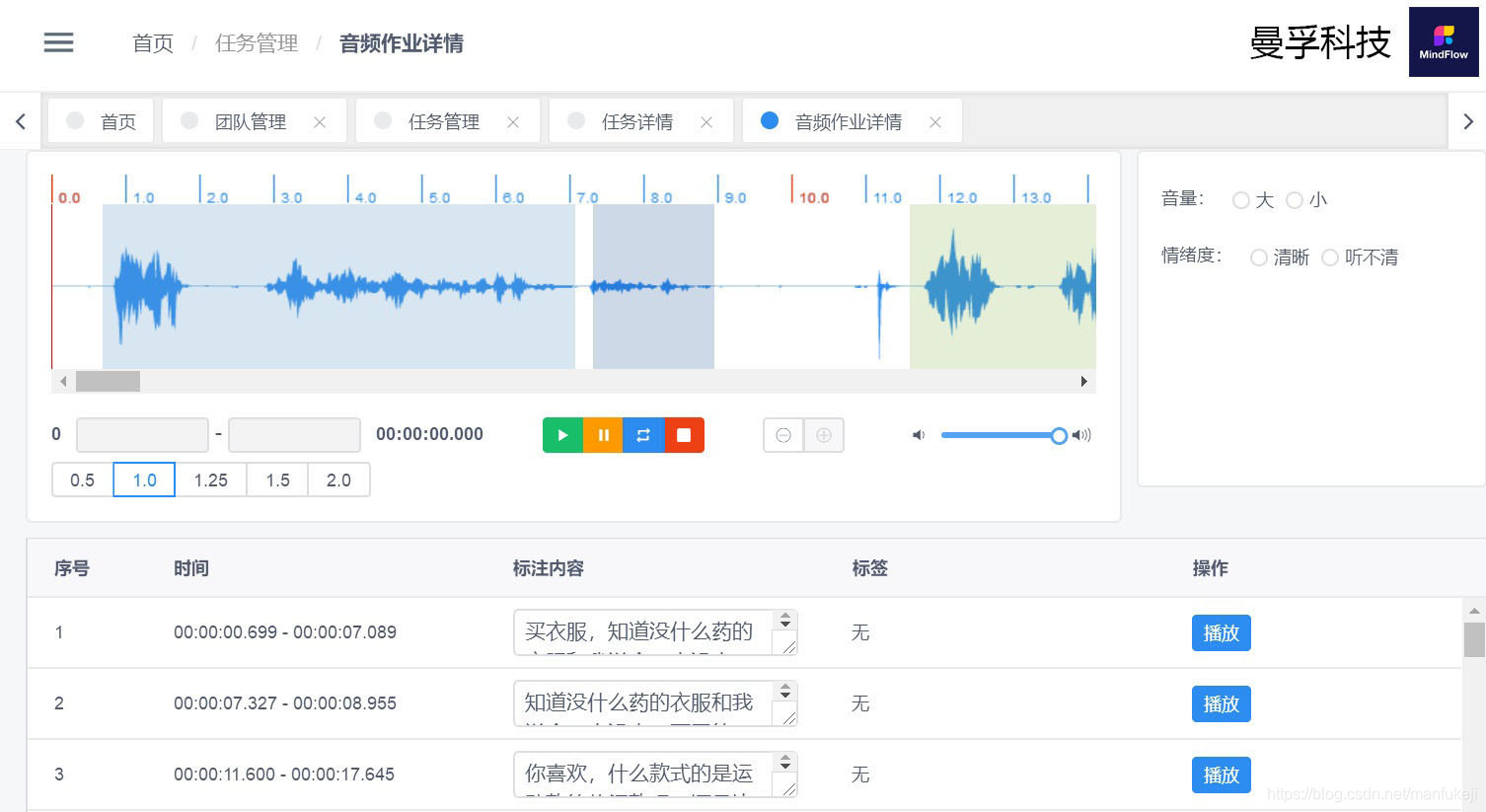
常用的数据标注工具类型有2D框、多边形分割、语义分割、点标注、线标注、视频标注、3D立方体标注等等。

3.数据标注行业新趋势
目前,人工智能技术逐渐从实验室走向现实,落地产品对于标注数据的质量提出了新的要求。
就当前的数据采集和标注的情况来看,传统的通用数据显然已无法满足产业场景化的要求,精细化、高质量的标注数据已成为行业新的需求。
在这样的时代背景下,数据标注行业亟需一场变革,高效率的数据标注工具与高素质的数据标注员将成为行业未来发展的重要组成部分,精细化的标注数据将构成未来AI行业发展最坚固的基石。
这篇关于曼孚科技:三分钟读懂何为“数据标注”的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





