本文主要是介绍记一次惊险的CDH6.3.2集群断电后重启的过程,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
重启服务
systemctl restart cloudera-scm-server.service
systemctl restart cloudera-scm-agent.service
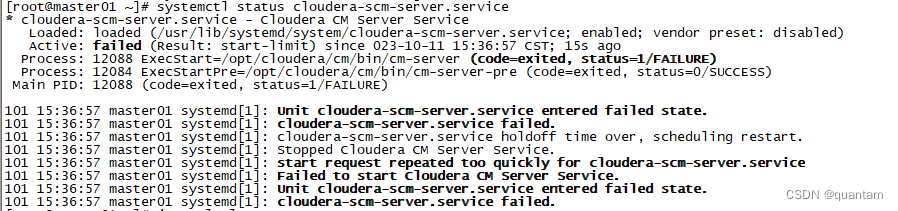
查看服务是否启动,显然结果是failed
systemctl status cloudera-scm-server.service
查看异常
journalctl -xe
去看服务日志
发现是这个位置错误
SqlExceptionHelper - Table ‘metastore.CM_VERSION’ doesn’t exist
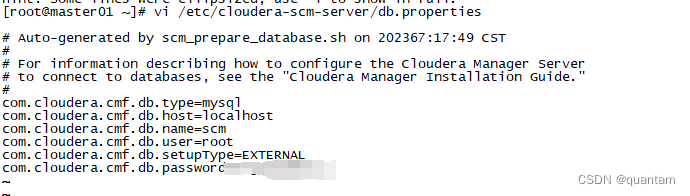
用navicat打开数据后发现确实在metastore库下是没有CM_VERSION这张表的,但是在scm下有,然后我就自己在metastore库里面建一个一样的,不知道有没有用
当时我记得配数据库的时候是用scm的,不知为啥变成metastore了,现在改回来
再重启服务
systemctl restart cloudera-scm-server.service
还是有问题
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'entityManagerFactoryBean': FactoryBean threw exception on object creation; nested exception is java.lang.RuntimeException: ScmActive at bootup: Failed to validate the identity of Cloudera Manager.
vi /etc/default/cloudera-scm-server
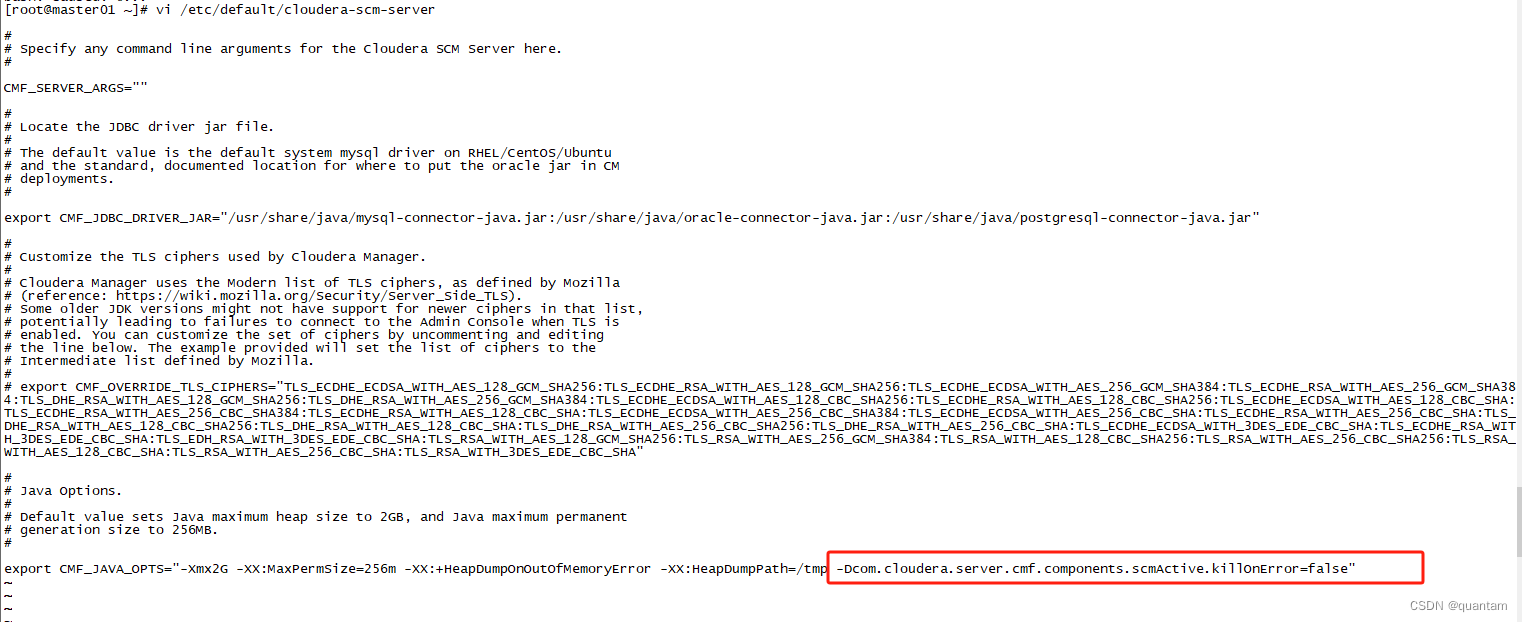
再重启服务
systemctl restart cloudera-scm-server.service

终于启动起来了,然后登录http://xxx:7180/cmf/home 去看哪些服务没起的就手动起就完了
这篇关于记一次惊险的CDH6.3.2集群断电后重启的过程的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





