本文主要是介绍袁芳的学习笔记(6)基于Predix的在线分析服务,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
作者:袁芳,北京华瑞特信息技术有限公司
如果您还没有Predix试用帐号,请访问https://supportcentral.ge.com/esurvey/GE_survey/takeSurvey.html?form_id=18446744073709715720申请。请务必准确提供您的信息,我们会以邮件方式通知您注册结果。
GE Predix平台的在线分析服务非常有特色,我个人觉得这也是GE做工业互联网云的最大优势,因为百年老店GE积累了大量的有价值的信息分析服务,这也正是其他企业所无法比拟的。今天我们参考官方教程(https://predix-io.run.aws-jp01-pr.ice.predix.io/resources/tutorials/journey.html#1615)记录如何向predix申请分析服务,并编写分析算法,借助predix运行分析服务。
一、通过Predix创建analytics-catalog-instance和analytics-runtime-instance(因为Predix一直在更新,所以此服务和图片可能不一致)
(1)通过predix控制台申请Analytics Catalog和Analytics Runtime,在创建服务中,请务必绑定UAA(UAA的创建可以参考之前的博客文章)
(2)下载一个前端示例工程
通过git命令下载示例程序:
git clone https://github.com/PredixDev/predix-nodejs-starter.git,详细参加之前的博客,本次借用之前创建的前端工程进行练习和纪录。以下按照命令将上一步创建的分析服务与前端进行绑定。
cf bind-serviceyf-predix-nodejs-starter yf-analytics-catalog-instance
cf restage yf-predix-nodejs-starter
cf env yf-predix-nodejs-starter,返回相关的predix-analytics-catalog环境变量如下所示:
"predix-analytics-catalog": [
{
"credentials": {
"catalog_uri":"https://predix-analytics-catalog-release.run.aws-jp01-pr.ice.predix.io",
"zone-http-header-name": "Predix-Zone-Id",
"zone-http-header-value":"0235f167-80f3-4578-964e-987549e4d892", 【此为Predix-Zone-Id的数值,重要】
"zone-oauth-scope":"analytics.zones.0235f167-80f3-4578-964e-987549e4d892.user" 【此为UAA授权信息,重要】
},
"label": "predix-analytics-catalog",
"name": "yf-analytics-catalog-instance",
"plan": "Bronze",
"provider": null,
"syslog_drain_url": null,
"tags": [],
"volume_mounts": []
}
],
-----------------------------------------------------------
cf bind-serviceyf-predix-nodejs-starter yf-analytics-runtime-instance
cf restage yf-predix-nodejs-starter
cf env yf-predix-nodejs-starter返回相关的predix-analytics-runtime环境变量如下所示:
"predix-analytics-runtime": [
{
"credentials": {
"config_uri":"https://predix-analytics-config-release.run.aws-jp01-pr.ice.predix.io",
"execution_uri": "https://predix-analytics-execution-release.run.aws-jp01-pr.ice.predix.io",
"monitoring_uri":"https://predix-analytics-monitoring-release.run.aws-jp01-pr.ice.predix.io",
"scheduler_uri": "https://predix-scheduler-service-release.run.aws-jp01-pr.ice.predix.io",
"zone-http-header-name": "Predix-Zone-Id",
"zone-http-header-value":"e9201bc2-9671-417e-8f2c-df562950e063", 【此为Predix-Zone-Id的数值,重要】
"zone-oauth-scope": "analytics.zones.e9201bc2-9671-417e-8f2c-df562950e063.user" 【此为UAA授权信息,重要】
},
"label": "predix-analytics-runtime",
"name": "yf-analytics-runtime-instance",
"plan": "Bronze",
"provider": null,
"syslog_drain_url": null,
"tags": [],
"volume_mounts": []
}
],
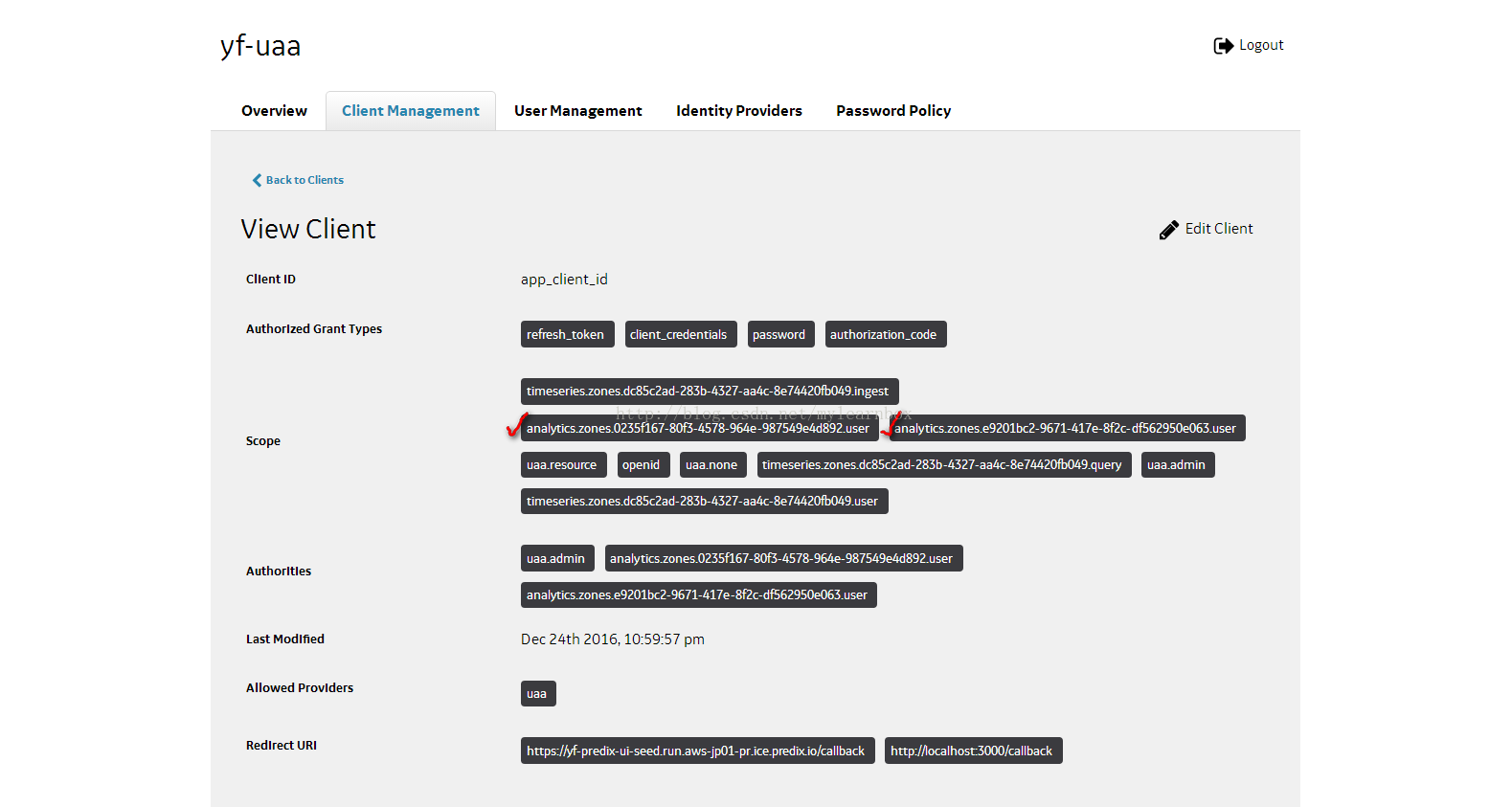
(3)打开UAA Dashboard,点击“Client Management”,此处我们选择并编辑app_client_id,在“scope”中,添加“analytics.zones.0235f167-80f3-4578-964e-987549e4d892.user”和“analytics.zones.e9201bc2-9671-417e-8f2c-df562950e063.user”,如图,保存并返回。
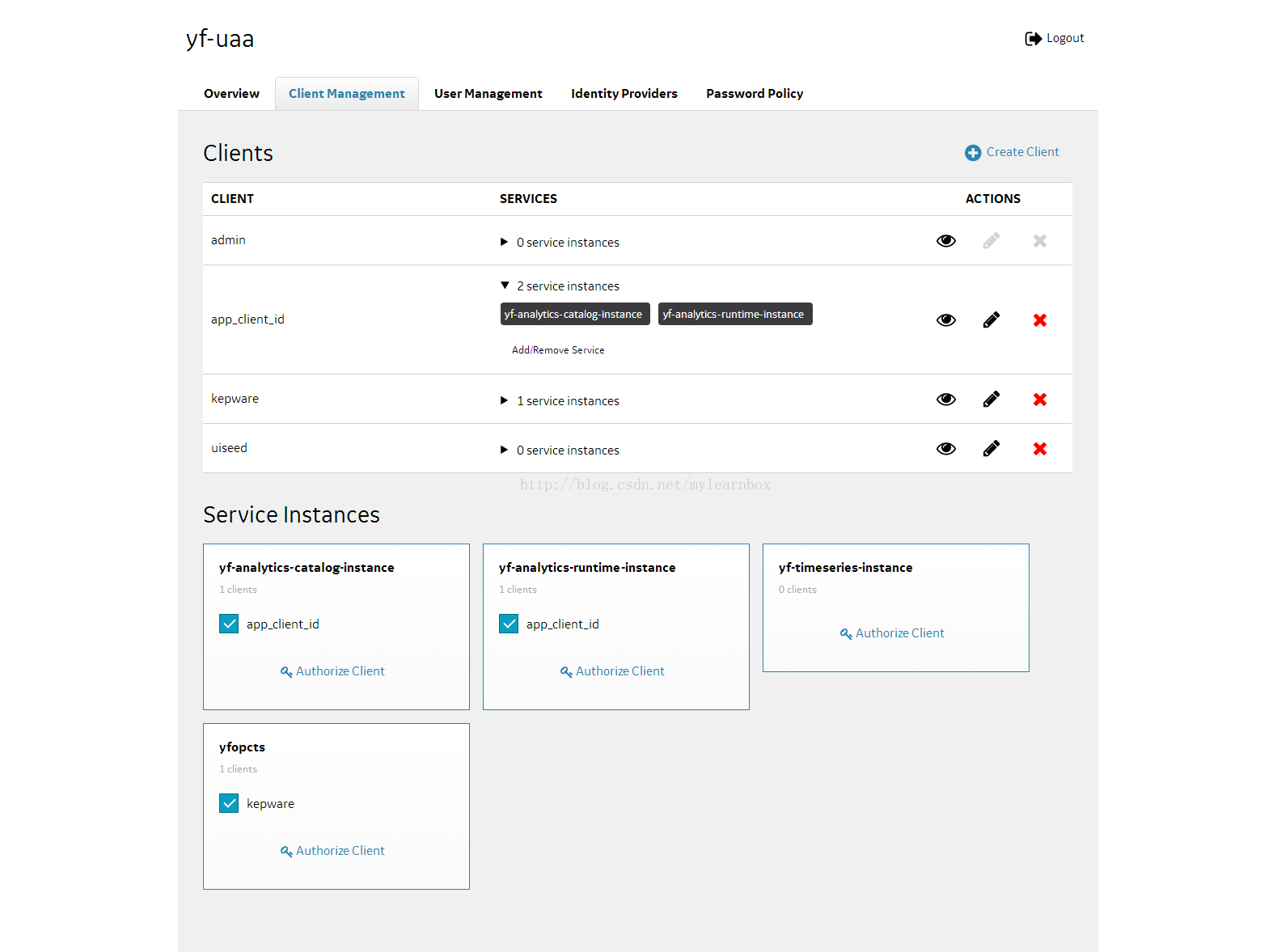
(4)在下图的client mangement页面中,在service instances面板中,我们看到新增的“yf-analytics-catalog-instance”和“yf-analytics-runtime-instance”两个模块,分别点击“Authorize Client”,并将app_client_id添加进去。
二、创建分析算法模块
(1)下载一个示例代码
git clone https://github.com/PredixDev/predix-analytics-sample.git
(2)使用maven编译打包,创建jar,该jar文件是一个算法,之后将通过predix tool kit上传到predix cloud
C:\Users\Administrator>cd predix-analytics-sample
C:\Users\Administrator\predix-analytics-sample>cd analytics
C:\Users\Administrator\predix-analytics-sample\analytics>cd demo-adder
C:\Users\Administrator\predix-analytics-sample\analytics\demo-adder>cddemo-adder-Java
C:\Users\Administrator\predix-analytics-sample\analytics\demo-adder\demo-adder-java>
mvn clean package
C:\Users\Administrator\predix-analytics-sample\analytics\demo-adder\demo-adder-java\target\demo-adder-java-1.0.0.jar
(3)按照路径打开DemoAdderJavaEntryPoint.java可以研读一下示例代码
C:\Users\Administrator\predix-analytics-sample\analytics\demo-adder\demo-adder-java\src\main\java\com\ge\predix\analytics\demo\java\DemoAdderJavaEntryPoint.java

(4)查阅算法配置
C:\Users\Administrator\predix-analytics-sample\analytics\demo-adder\demo-adder-java\src\main\resources\config.json
(5)以后可以自己参考这种模式编写自己的算法,切记一定要配置到config.json文件内
三、执行分析算法
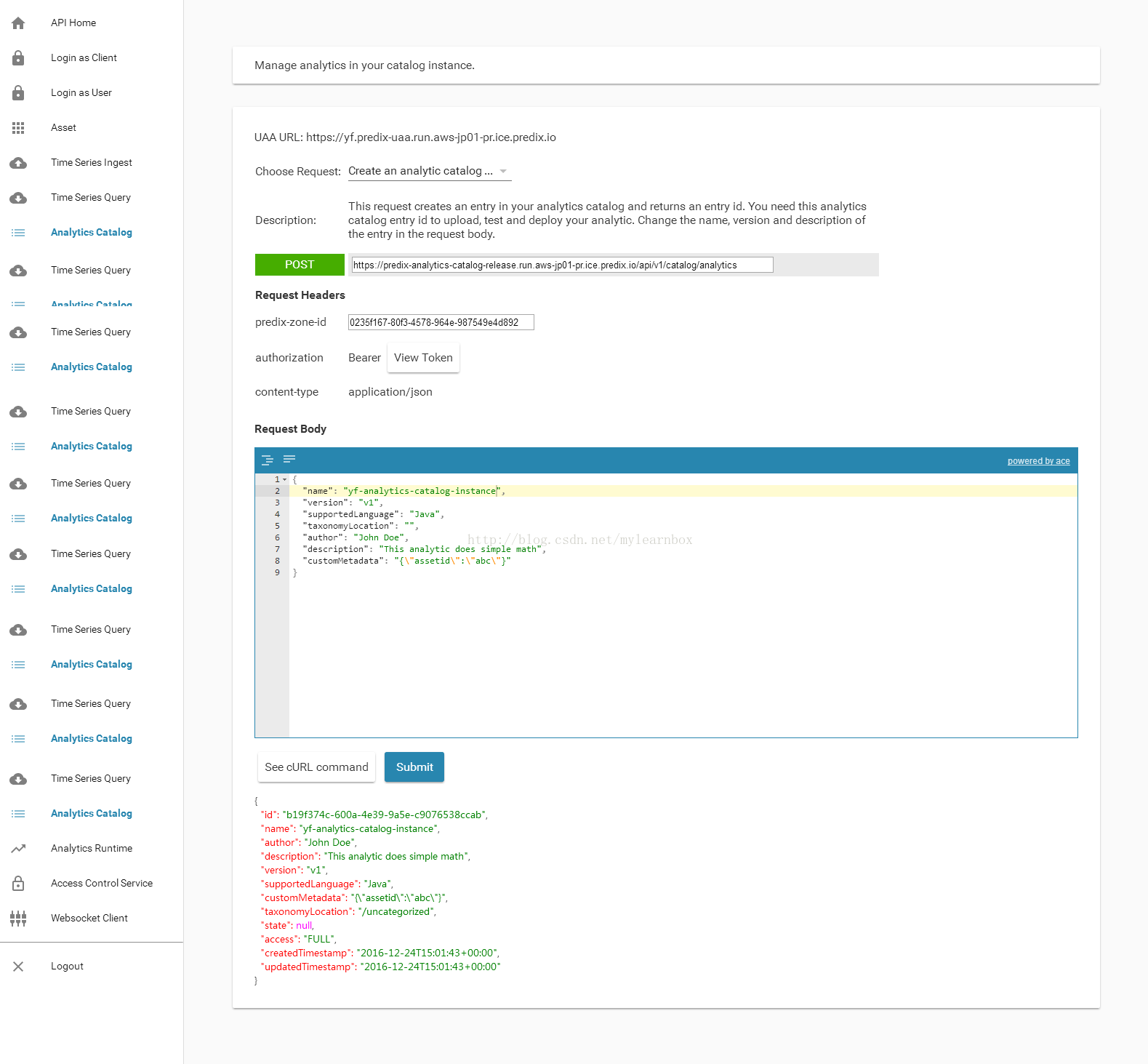
(1)在之前创建的分析分析实例(AnalyticsCatalog instance)中创建一个分类项。访问https://predix-starter.run.aws-jp01-pr.ice.predix.io,选择右上角 API Explorer,选择左侧菜单的Login as Client. ,成功登录之后,选择Analytics Catalog,
在“Choose Request”中选择Create an analytic catalog entry ,输入predix-zone-id ,点击submit提交。返回结果:
{
"id": "b19f374c-600a-4e39-9a5e-c9076538ccab",<!--此为analyticCatalogEntryId后面要用-->
"name": "yf-analytics-catalog-instance",
"author": "John Doe",
"description": "This analytic does simple math",
"version": "v1",
"supportedLanguage": "Java",
"customMetadata":"{\"assetid\":\"abc\"}",
"taxonomyLocation": "/uncategorized",
"state": null,
"access": "FULL",
"createdTimestamp": "2016-12-24T15:01:43+00:00",
"updatedTimestamp": "2016-12-24T15:01:43+00:00"
}
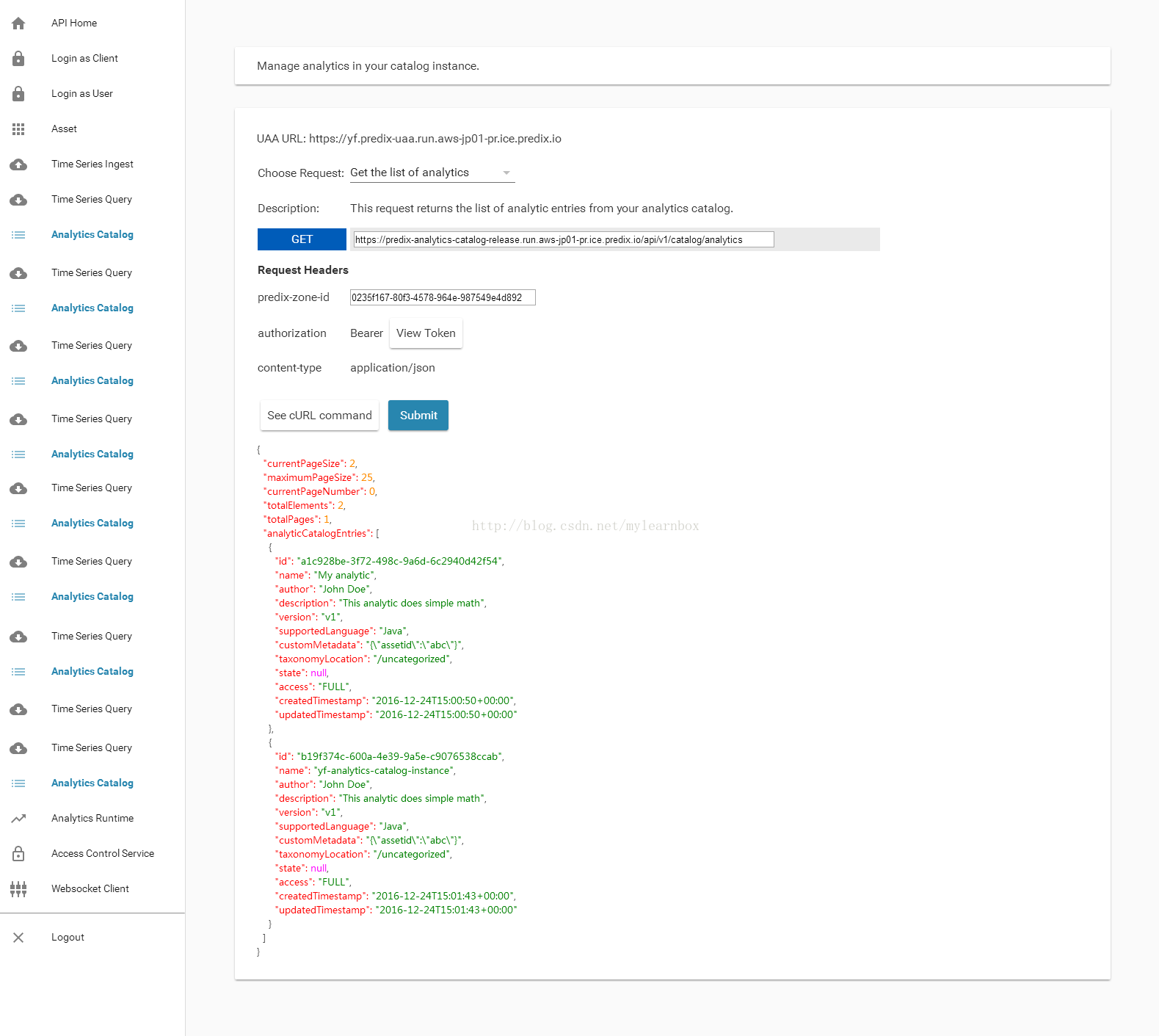
(2)Choose Request: 中选择Get the list of analytics. ,填写predix-zone-id,点击Submit.
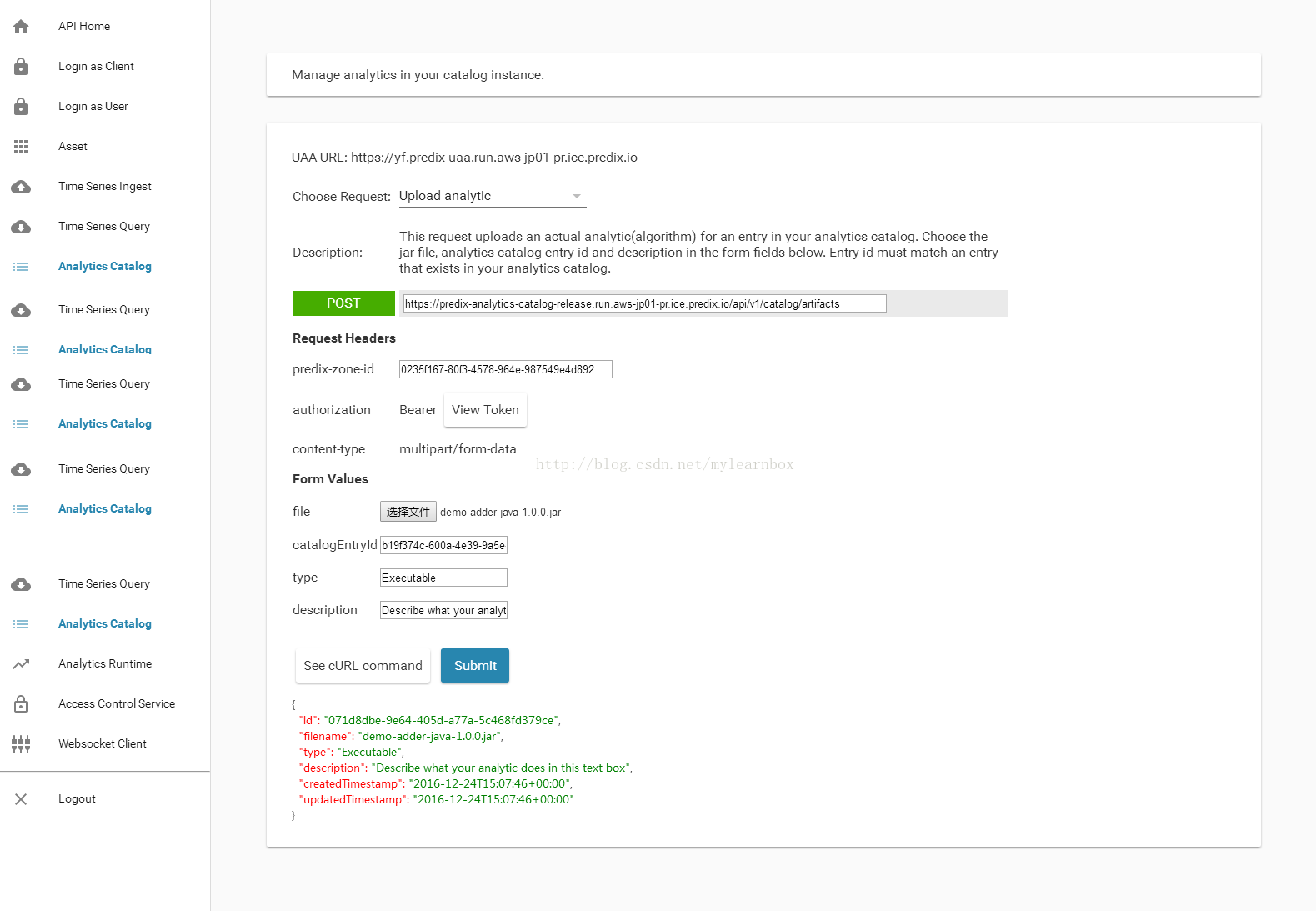
(3)Choose request:选择Upload analytic. 在Form Values区域中,将demo-adder-java-1.0.0.jar上传, 在catalogEntryId输入框中,输入analyticCatalogId ,并添加 predix-zone-id, ,点击submit,并自行保存一下结果,因为里面的id数值后面会用到。
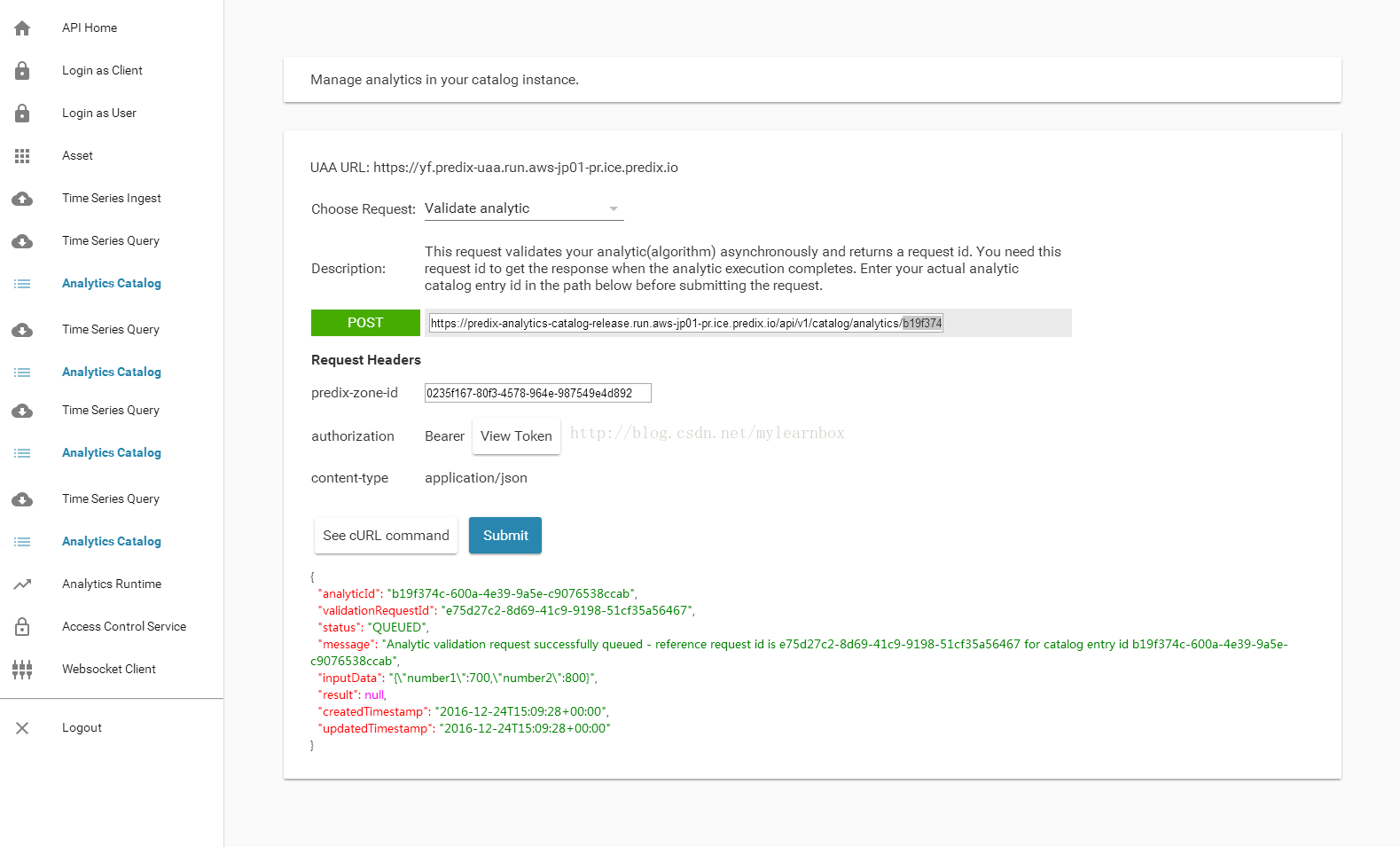
(4)Choose request: 选择 Validate analytic. 在POST的 URL中,把地址后面的analyticCatalogEntryId 填充一下,点击submit提交,并自行保存结果,其中的 validationRequestId后面会用到。
结果:
{
"analyticId": "b19f374c-600a-4e39-9a5e-c9076538ccab",
"validationRequestId":"e75d27c2-8d69-41c9-9198-51cf35a56467",<!--后面要用到 重要-->
"status": "QUEUED",
"message": "Analytic validation request successfullyqueued - reference request id is e75d27c2-8d69-41c9-9198-51cf35a56467 forcatalog entry id b19f374c-600a-4e39-9a5e-c9076538ccab",
"inputData": "{\"number1\":700,\"number2\":800}",
"result": null,
"createdTimestamp": "2016-12-24T15:09:28+00:00",
"updatedTimestamp": "2016-12-24T15:09:28+00:00"
}
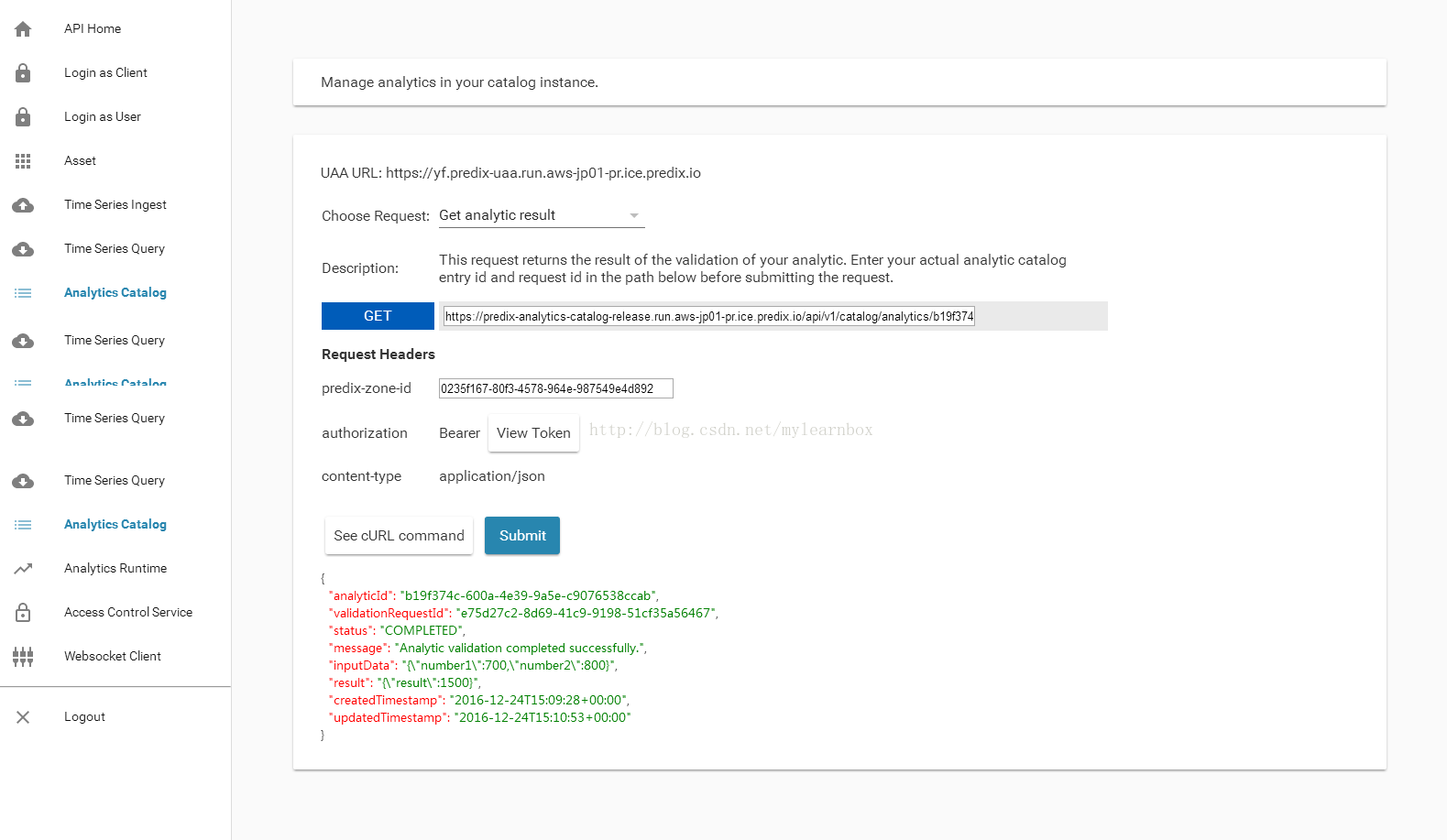
(5)Choose request:选择 Get analytic result. 在 GET的 URL,中替换两个字符串 ,分别是 analyticCatalogEntryId和request id ,点击submit,结果中的result就是计算结果。
eg:GETURL=https://predix-analytics-catalog-release.run.aws-jp01-pr.ice.predix.io/api/v1/catalog/analytics/b19f374c-600a-4e39-9a5e-c9076538ccab/validation/e75d27c2-8d69-41c9-9198-51cf35a56467
(6)Choose request:选择Deploy analytic.在 POST 的URL,替换填充 analyticCatalogEntryId,点击 Submit.并将结果自行保存么,待后面使用resultid。
eg:POSTURL=https://predix-analytics-catalog-release.run.aws-jp01-pr.ice.predix.io/api/v1/catalog/analytics/b19f374c-600a-4e39-9a5e-c9076538ccab/deployment
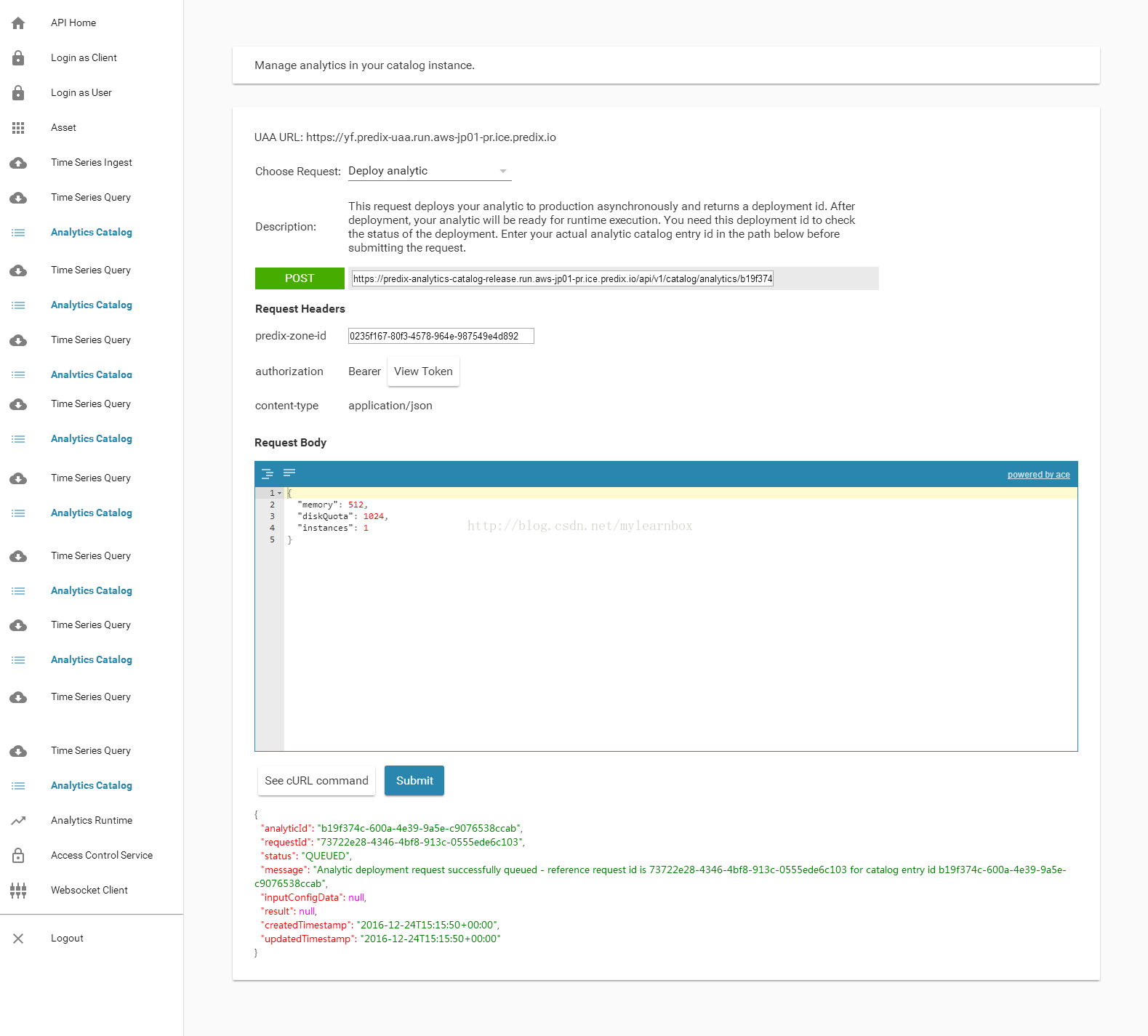
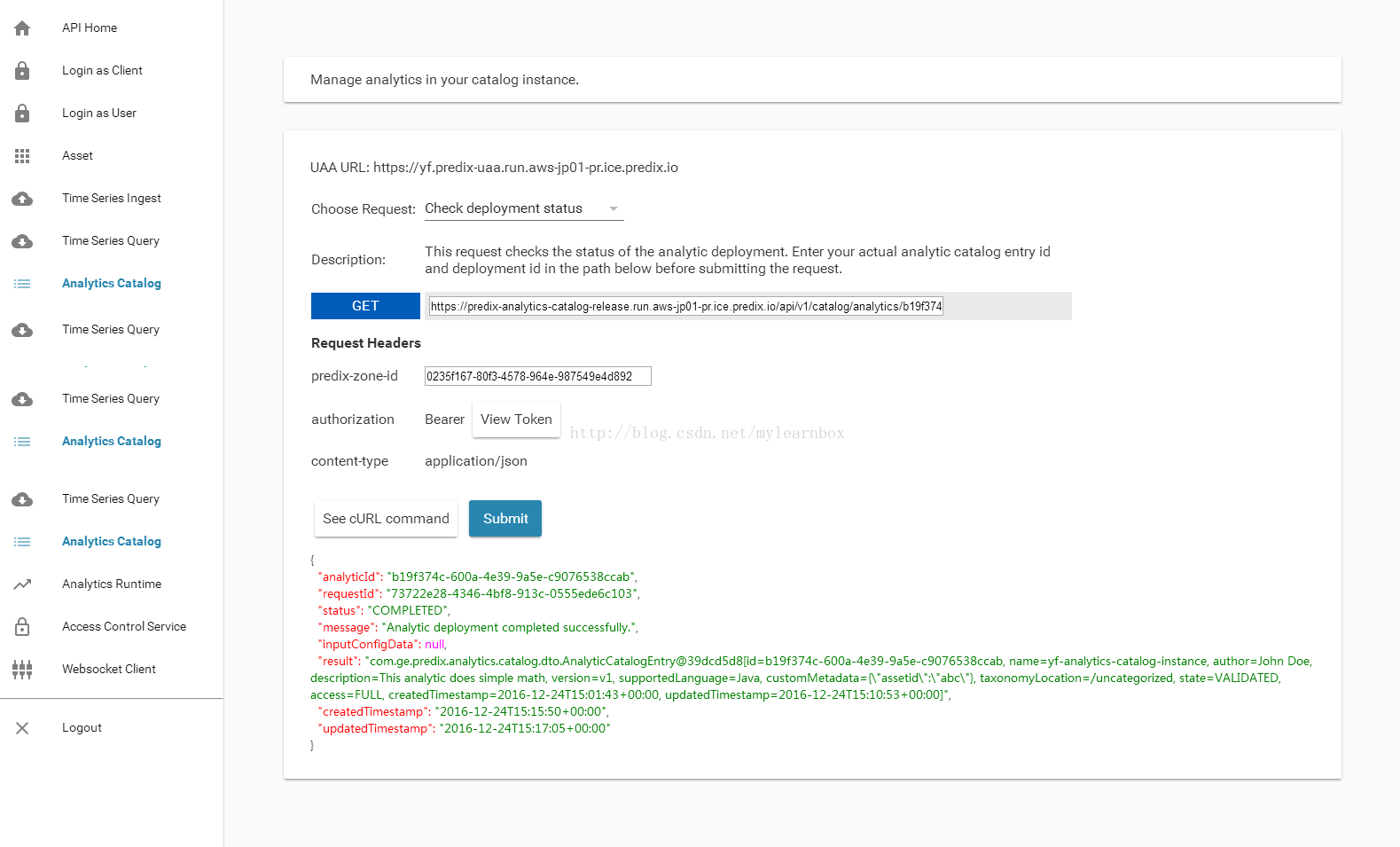
(7)Choose request: 选择Check deployment status. 在GET 的URL中,替换两个字符串,分别为 analyticCatalogEntryId和deployment requestid点击 Submit.。
eg:GET URL=https://predix-analytics-catalog-release.run.aws-jp01-pr.ice.predix.io/api/v1/catalog/analytics/b19f374c-600a-4e39-9a5e-c9076538ccab/deployment/73722e28-4346-4bf8-913c-0555ede6c103
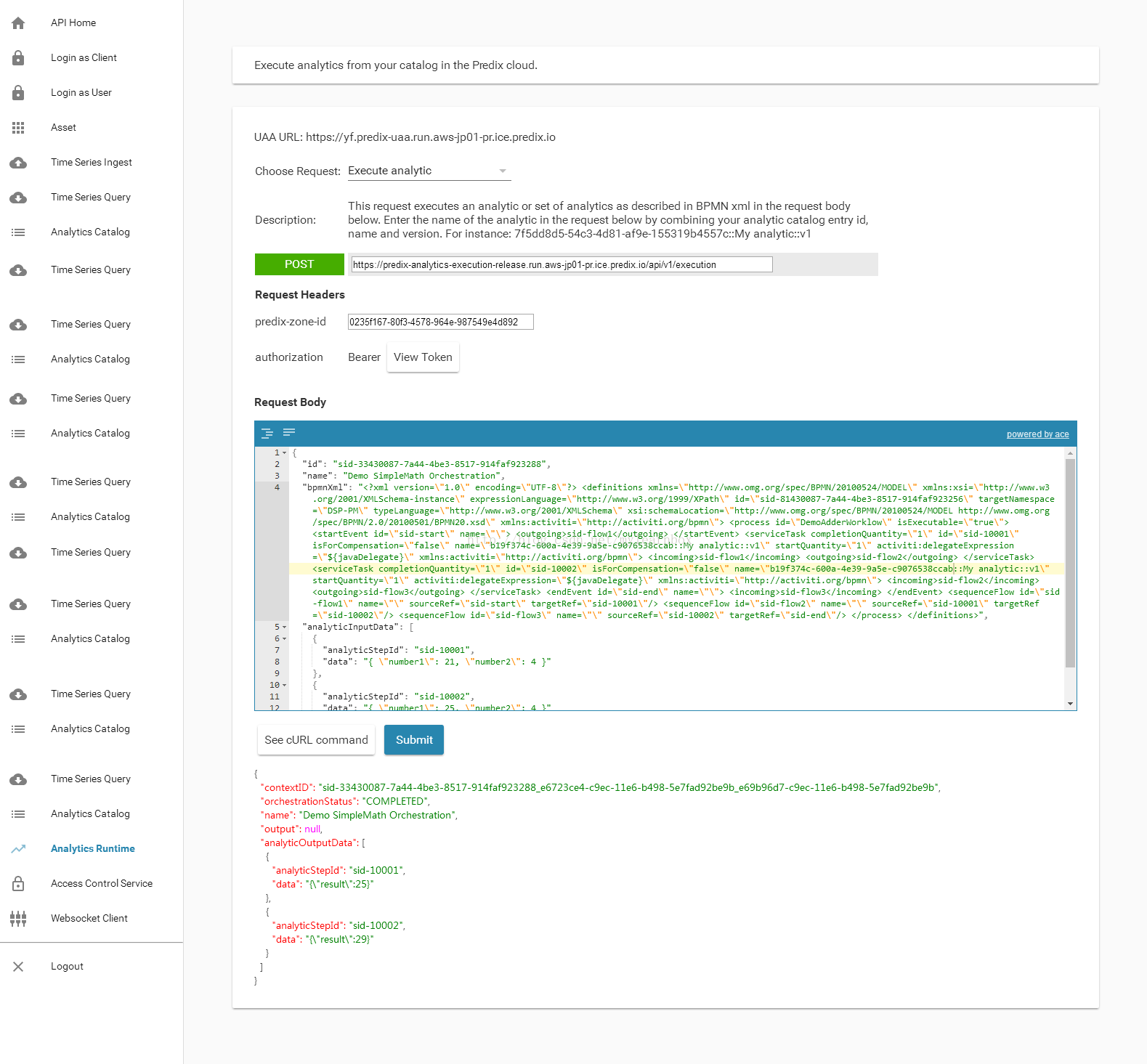
(8)Choose request:选择 Execute Analytic. 此处请求执行一个分析或者设置BPMN的配置,BPMN ( Business Process Modeling Notation)描述如何在predix的分析执行运行环境中定义分析工作流
例如:在这个工作流中,这里两个数字相加的算法命名为DemoAdder Analytic 。修改一下Request Body 中的BPMN XML ,搜索一下serviceTask字符串,找到位置,将现在的示例数值替换为上面的analyticcatalog entry id=b19f374c-600a-4e39-9a5e-c9076538ccab,点击submit执行分析流程,即可在result获取结果 25 and 29.
参考
https://predix-io.run.aws-jp01-pr.ice.predix.io/resources/tutorials/journey.html#1615
在使用中您有任何问题,请访问我们的论坛http://bbs.csdn.net/forums/GEPredix
GE数字集团的技术专家们会在线回答您的问题。
也请访问我们在CSDN的Predix专区http://predix.csdn.net 了解更多Predix的内容和相关活动。
这篇关于袁芳的学习笔记(6)基于Predix的在线分析服务的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




