本文主要是介绍关于单核/多核死机问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
以下信息来自https://www.cnblogs.com/jerry116/p/8799355.html。另外还未看代码进行验证
https://www.cnblogs.com/sky-heaven/p/16616530.html
linux-3.16
1、对于非抢占内核。如果代码中出现死锁(未屏蔽软中断、本cpu中断)或者死循环。那么出现死锁的这个cpu将一直卡住,无法进行任务调度。
对于这种情况需要一种检测机制去发现这种问题。具体就是每个核有一个喂狗线程(优先级最高?)和一个喂狗软中断(定时器??)。喂狗线程负责不断更新时间戳。喂狗软中断负责检测时间戳是否更新。
即使出现了cpu无法调度的情况(不考虑中断被屏蔽)。由于软中断能够打断线程或者进程的运行。当喂狗软中断触发时,先去检查上一次喂狗线程的时间。如果当前时间距离上一次喂狗的时间超过了一定的阈值。则认为未进行任务调度,打印调用栈信息(由于任务切换不了,那么软中断打断的一定是死锁的地方)。如果时间戳未超,说明喂狗线程还能被调度,cpu还能进行任务切换
编译内核的时候需要加上这些配置

static struct smp_hotplug_thread watchdog_threads = {.store = &softlockup_watchdog,.thread_should_run = watchdog_should_run,.thread_fn = watchdog,.thread_comm = "watchdog/%u",.setup = watchdog_enable,.cleanup = watchdog_cleanup,.park = watchdog_disable,.unpark = watchdog_enable,
};
喂狗线程
lockup_detector_init会为每个cpu创建一个watchdog内核线程
void __init lockup_detector_init(void)
{set_sample_period();if (watchdog_user_enabled)watchdog_enable_all_cpus(false);
}
static int watchdog_enable_all_cpus(bool sample_period_changed)
{
.................err = smpboot_register_percpu_thread(&watchdog_threads);
........................return err;
}__smpboot_create_thread->smpboot_thread_fn。
static int smpboot_thread_fn(void *data)
{
.......................................set_current_state(TASK_RUNNING);preempt_enable();ht->thread_fn(td->cpu);
...............................
}其中ht->thread_fn就对应了回调函数watchdog。可以看到喂狗线程的回调函数更新了一下时间戳(__touch_watchdog)。
那喂狗线程何时被调度呢?下面进行解析
static void watchdog(unsigned int cpu)
{__this_cpu_write(soft_lockup_hrtimer_cnt,__this_cpu_read(hrtimer_interrupts));__touch_watchdog();
}
static void __touch_watchdog(void)
{__this_cpu_write(watchdog_touch_ts, get_timestamp());
}喂狗软中断(其实就是高精度定时器),检测cpu是否无法调度
linux3.16 watchdog_enable是在这个地方进行注册的
watchdog_enable在smpboot_thread_fn第一次执行时得到执行,随后其状态设为HP_THREAD_ACTIVE。
static void watchdog_enable(unsigned int cpu)
{struct hrtimer *hrtimer = &__raw_get_cpu_var(watchdog_hrtimer);/* kick off the timer for the hardlockup detector */hrtimer_init(hrtimer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);hrtimer->function = watchdog_timer_fn;//高精度定时器回调函数/* Enable the perf event */watchdog_nmi_enable(cpu);/* 启动一个定时器 *//* done here because hrtimer_start can only pin to smp_processor_id() */hrtimer_start(hrtimer, ns_to_ktime(sample_period),HRTIMER_MODE_REL_PINNED);/* initialize timestamp */watchdog_set_prio(SCHED_FIFO, MAX_RT_PRIO - 1);__touch_watchdog();
}高精度定时器,看网上说都是在中断上下文中执行的(中断上半部以及软中断中)
linux 内核 高精度定时器(hrtimer)实现机制_hrtimer_start_老王不让用的博客-CSDN博客
- HRTIMER_MODE_SOFT:表示该定时器是否是“软”的,也就是定时器到期回调函数是在软中断(HRTIMER_SOFTIRQ,高精度定时器)下被执行的。
- HRTIMER_MODE_HARD:表示该定时器是否是“硬”的,也就是定时器到期回调函数是
- 在中断处理程序中被执行的。看打印好像确实是这样的 看打印好像确实是这样的
static enum hrtimer_restart watchdog_timer_fn(struct hrtimer *hrtimer) { .........................printk(KERN_EMERG "\r\n softlockup simulate, in_interrupt %u in_softirq %u, cpu id %d\n", in_interrupt(), in_softirq(), smp_processor_id()); ........................return HRTIMER_RESTART; }
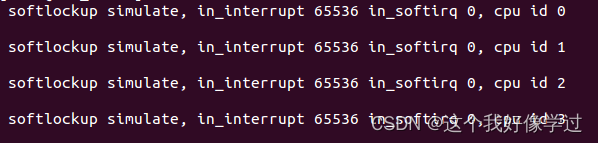
从函数watchdog_enable里面可以看到高精度定时器的回调函数是watchdog_timer_fn
1、可以看到喂狗线程就是在高精度定时器里面被唤醒的。
wake_up_process(__this_cpu_read(softlockup_watchdog));
2、定时器的下一次触发时间也是在这里更新
hrtimer_forward_now(hrtimer, ns_to_ktime(sample_period));
3、检测是否发生soft lockup也是在这个里面is_softlockup
/* 高精度定时器的回调是在中断上下文执行的 */
/* watchdog kicker functions */
static enum hrtimer_restart watchdog_timer_fn(struct hrtimer *hrtimer)
{unsigned long touch_ts = __this_cpu_read(watchdog_touch_ts);struct pt_regs *regs = get_irq_regs();int duration;int softlockup_all_cpu_backtrace = sysctl_softlockup_all_cpu_backtrace;/* kick the hardlockup detector */watchdog_interrupt_count();//增加计数,这个应该是hard lockup使用/* 唤醒喂狗线程 *//* kick the softlockup detector */wake_up_process(__this_cpu_read(softlockup_watchdog));/* 增加高精度定时器的超时时间,并重启定时器 *//* .. and repeat */hrtimer_forward_now(hrtimer, ns_to_ktime(sample_period));if (touch_ts == 0) {//为什么时间戳会是0呢?难道是第一次执行??if (unlikely(__this_cpu_read(softlockup_touch_sync))) {/** If the time stamp was touched atomically* make sure the scheduler tick is up to date.*/__this_cpu_write(softlockup_touch_sync, false);sched_clock_tick();}/* Clear the guest paused flag on watchdog reset */kvm_check_and_clear_guest_paused();__touch_watchdog();return HRTIMER_RESTART;}/* 现在时间到上次时间戳的位置已经超了 */duration = is_softlockup(touch_ts);if (unlikely(duration)) {//非0说明已经触发检测机制,cpu在规定时间内未进行调度if (kvm_check_and_clear_guest_paused())return HRTIMER_RESTART;/* only warn once */if (__this_cpu_read(soft_watchdog_warn) == true)return HRTIMER_RESTART;if (softlockup_all_cpu_backtrace) {if (test_and_set_bit(0, &soft_lockup_nmi_warn)) {/* Someone else will report us. Let's give up */__this_cpu_write(soft_watchdog_warn, true);return HRTIMER_RESTART;}}printk(KERN_EMERG "BUG: soft lockup - CPU#%d stuck for %us! [%s:%d]\n",smp_processor_id(), duration,current->comm, task_pid_nr(current));print_modules();print_irqtrace_events(current);if (regs)show_regs(regs);elsedump_stack();if (softlockup_all_cpu_backtrace) {trigger_allbutself_cpu_backtrace();clear_bit(0, &soft_lockup_nmi_warn);/* Barrier to sync with other cpus */smp_mb__after_atomic();}if (softlockup_panic)panic("softlockup: hung tasks");__this_cpu_write(soft_watchdog_warn, true);} else__this_cpu_write(soft_watchdog_warn, false);return HRTIMER_RESTART;
}static int is_softlockup(unsigned long touch_ts)
{unsigned long now = get_timestamp();/* 当前时间已经超过上一次的时间戳 + 检测阈值 *//* Warn about unreasonable delays: */if (time_after(now, touch_ts + get_softlockup_thresh()))return now - touch_ts;return 0;
}可以看到基于软件实现的喂狗原理大致如下:
首先存在一个喂狗线程,和一个喂狗软中断(其实就是高精度定时器)。其中喂狗线程被调度的时候就更新时间戳watchdog_touch_ts(per cpu变量,每个cpu都有一个)。喂狗定时器里面负责唤醒喂狗线程去更新时间戳,并且检查当前时间和时间戳的差值。如果差值超过一定的阈值,则认为触发soft lockup.
代码示例:非抢占内核
从调用栈也能看到是test_thread里面出了问题
创建了一个内核线程进行死循环
static struct task_struct *test_task; int test_thread(void* a) {unsigned long flags;printk(KERN_EMERG "\r\n softlockup simulate, in_interrupt %u in_softirq %u, cpu id %d\n", in_interrupt(), in_softirq(), smp_processor_id());while (1){}return 0; }softlockup simulate, in_interrupt 0 in_softirq 0, cpu id 3 BUG: soft lockup - CPU#3 stuck for 23s! [test_task:586] Modules linked in:CPU: 3 PID: 586 Comm: test_task Not tainted 3.16.0 #41 task: ee01c800 ti: ee206000 task.ti: ee206000 PC is at test_thread+0x30/0x38 LR is at test_thread+0x30/0x38 pc : [<c0305d58>] lr : [<c0305d58>] psr: 60000013 sp : ee207f60 ip : 00000001 fp : 00000000 r10: 00000000 r9 : 00000000 r8 : 00000000 r7 : c0305d28 r6 : 00000000 r5 : 00000000 r4 : ee1fd400 r3 : 000004f0 r2 : c089f494 r1 : 20000093 r0 : 0000003d Flags: nZCv IRQs on FIQs on Mode SVC_32 ISA ARM Segment kernel Control: 10c53c7d Table: 8e2f806a DAC: 00000015 CPU: 3 PID: 586 Comm: test_task Not tainted 3.16.0 #41 [<c00142d0>] (unwind_backtrace) from [<c0010f64>] (show_stack+0x10/0x14) [<c0010f64>] (show_stack) from [<c045cb60>] (dump_stack+0x74/0x90) [<c045cb60>] (dump_stack) from [<c0087e08>] (watchdog_timer_fn+0x158/0x1bc) [<c0087e08>] (watchdog_timer_fn) from [<c003f1d0>] (hrtimer_run_queues+0xcc/0x23c) [<c003f1d0>] (hrtimer_run_queues) from [<c002c244>] (run_local_timers+0x8/0x14) [<c002c244>] (run_local_timers) from [<c002c27c>] (update_process_times+0x2c/0x58) [<c002c27c>] (update_process_times) from [<c006a8e8>] (tick_periodic+0x34/0xbc) [<c006a8e8>] (tick_periodic) from [<c006a9e4>] (tick_handle_periodic+0x2c/0x94) [<c006a9e4>] (tick_handle_periodic) from [<c00138d8>] (twd_handler+0x2c/0x40) [<c00138d8>] (twd_handler) from [<c005cd88>] (handle_percpu_devid_irq+0x68/0x84) [<c005cd88>] (handle_percpu_devid_irq) from [<c00594e0>] (generic_handle_irq+0x20/0x30) [<c00594e0>] (generic_handle_irq) from [<c000ecf4>] (handle_IRQ+0x38/0x94) [<c000ecf4>] (handle_IRQ) from [<c00085b0>] (gic_handle_irq+0x28/0x5c) [<c00085b0>] (gic_handle_irq) from [<c0011a40>] (__irq_svc+0x40/0x50) Exception stack(0xee207f18 to 0xee207f60) 7f00: 0000003d 20000093 7f20: c089f494 000004f0 ee1fd400 00000000 00000000 c0305d28 00000000 00000000 7f40: 00000000 00000000 00000001 ee207f60 c0305d58 c0305d58 60000013 ffffffff [<c0011a40>] (__irq_svc) from [<c0305d58>] (test_thread+0x30/0x38) [<c0305d58>] (test_thread) from [<c003c49c>] (kthread+0xcc/0xe8) [<c003c49c>] (kthread) from [<c000e4b8>] (ret_from_fork+0x14/0x3c) Kernel panic - not syncing: softlockup: hung tasks CPU: 3 PID: 586 Comm: test_task Not tainted 3.16.0 #41 [<c00142d0>] (unwind_backtrace) from [<c0010f64>] (show_stack+0x10/0x14) [<c0010f64>] (show_stack) from [<c045cb60>] (dump_stack+0x74/0x90) [<c045cb60>] (dump_stack) from [<c0459fb8>] (panic+0x90/0x204) [<c0459fb8>] (panic) from [<c0087e50>] (watchdog_timer_fn+0x1a0/0x1bc) [<c0087e50>] (watchdog_timer_fn) from [<c003f1d0>] (hrtimer_run_queues+0xcc/0x23c) [<c003f1d0>] (hrtimer_run_queues) from [<c002c244>] (run_local_timers+0x8/0x14) [<c002c244>] (run_local_timers) from [<c002c27c>] (update_process_times+0x2c/0x58) [<c002c27c>] (update_process_times) from [<c006a8e8>] (tick_periodic+0x34/0xbc) [<c006a8e8>] (tick_periodic) from [<c006a9e4>] (tick_handle_periodic+0x2c/0x94) [<c006a9e4>] (tick_handle_periodic) from [<c00138d8>] (twd_handler+0x2c/0x40) [<c00138d8>] (twd_handler) from [<c005cd88>] (handle_percpu_devid_irq+0x68/0x84) [<c005cd88>] (handle_percpu_devid_irq) from [<c00594e0>] (generic_handle_irq+0x20/0x30) [<c00594e0>] (generic_handle_irq) from [<c000ecf4>] (handle_IRQ+0x38/0x94) [<c000ecf4>] (handle_IRQ) from [<c00085b0>] (gic_handle_irq+0x28/0x5c) [<c00085b0>] (gic_handle_irq) from [<c0011a40>] (__irq_svc+0x40/0x50) Exception stack(0xee207f18 to 0xee207f60) 7f00: 0000003d 20000093 7f20: c089f494 000004f0 ee1fd400 00000000 00000000 c0305d28 00000000 00000000 7f40: 00000000 00000000 00000001 ee207f60 c0305d58 c0305d58 60000013 ffffffff [<c0011a40>] (__irq_svc) from [<c0305d58>] (test_thread+0x30/0x38) [<c0305d58>] (test_thread) from [<c003c49c>] (kthread+0xcc/0xe8) [<c003c49c>] (kthread) from [<c000e4b8>] (ret_from_fork+0x14/0x3c) CPU0: stopping CPU: 0 PID: 0 Comm: swapper/0 Not tainted 3.16.0 #41 [<c00142d0>] (unwind_backtrace) from [<c0010f64>] (show_stack+0x10/0x14) [<c0010f64>] (show_stack) from [<c045cb60>] (dump_stack+0x74/0x90) [<c045cb60>] (dump_stack) from [<c0012e9c>] (handle_IPI+0x134/0x170) [<c0012e9c>] (handle_IPI) from [<c00085dc>] (gic_handle_irq+0x54/0x5c) [<c00085dc>] (gic_handle_irq) from [<c0011a40>] (__irq_svc+0x40/0x50) Exception stack(0xc088ff60 to 0xc088ffa8) ff60: ffffffed 00000000 ffffffed 00000000 c088e000 00000000 00000000 c0896464 ff80: c0463dc4 00000000 c088cb30 0000004c 00000000 c088ffa8 c000efd4 c000efd8 ffa0: 60000013 ffffffff [<c0011a40>] (__irq_svc) from [<c000efd8>] (arch_cpu_idle+0x28/0x30) [<c000efd8>] (arch_cpu_idle) from [<c0052150>] (cpu_startup_entry+0x1ac/0x1f0) [<c0052150>] (cpu_startup_entry) from [<c05d1b3c>] (start_kernel+0x328/0x38c) CPU1: stopping CPU: 1 PID: 0 Comm: swapper/1 Not tainted 3.16.0 #41 [<c00142d0>] (unwind_backtrace) from [<c0010f64>] (show_stack+0x10/0x14) [<c0010f64>] (show_stack) from [<c045cb60>] (dump_stack+0x74/0x90) [<c045cb60>] (dump_stack) from [<c0012e9c>] (handle_IPI+0x134/0x170) [<c0012e9c>] (handle_IPI) from [<c00085dc>] (gic_handle_irq+0x54/0x5c) [<c00085dc>] (gic_handle_irq) from [<c0011a40>] (__irq_svc+0x40/0x50) Exception stack(0xee891f90 to 0xee891fd8) 1f80: ffffffed 00000000 ffffffed 00000000 1fa0: ee890000 00000000 00000000 c0896464 c0463dc4 00000000 c088cb30 0000004c 1fc0: 00000000 ee891fd8 c000efd4 c000efd8 60000013 ffffffff [<c0011a40>] (__irq_svc) from [<c000efd8>] (arch_cpu_idle+0x28/0x30) [<c000efd8>] (arch_cpu_idle) from [<c0052150>] (cpu_startup_entry+0x1ac/0x1f0) [<c0052150>] (cpu_startup_entry) from [<60008684>] (0x60008684) CPU2: stopping CPU: 2 PID: 0 Comm: swapper/2 Not tainted 3.16.0 #41 [<c00142d0>] (unwind_backtrace) from [<c0010f64>] (show_stack+0x10/0x14) [<c0010f64>] (show_stack) from [<c045cb60>] (dump_stack+0x74/0x90) [<c045cb60>] (dump_stack) from [<c0012e9c>] (handle_IPI+0x134/0x170) [<c0012e9c>] (handle_IPI) from [<c00085dc>] (gic_handle_irq+0x54/0x5c) [<c00085dc>] (gic_handle_irq) from [<c0011a40>] (__irq_svc+0x40/0x50) Exception stack(0xee893f90 to 0xee893fd8) 3f80: ffffffed 00000000 ffffffed 00000000 3fa0: ee892000 00000000 00000000 c0896464 c0463dc4 00000000 c088cb30 0000004c 3fc0: 00000000 ee893fd8 c000efd4 c000efd8 60000013 ffffffff [<c0011a40>] (__irq_svc) from [<c000efd8>] (arch_cpu_idle+0x28/0x30) [<c000efd8>] (arch_cpu_idle) from [<c0052150>] (cpu_startup_entry+0x1ac/0x1f0) [<c0052150>] (cpu_startup_entry) from [<60008684>] (0x60008684) PANIC: softlockup: hung tasksEntering kdb (current=0xee01c800, pid 586) on processor 3 due to Keyboard Entry [3]kdb>
2、单核挂死并屏蔽了本cpu中断的情况。eg local_irq_save, spin_lock_irqsave。对于这种情况由于CPU无法接受到中断信息了。显然中断都无法接收了,上面第一种方法就失效了。但是某些芯片有不可屏蔽中断NMI。
在多核系统里面,每个核都可以去检测其他核的中断接受情况,如果检测到某个核未接受中断了,就可以给该核发生一个不可屏蔽中断的消息,同样在这个中断处理函数里面把调用栈打出来。
该方法有部分也是和方法1公用的
watchdog_enable->watchdog_nmi_enable
static void watchdog_enable(unsigned int cpu)
{struct hrtimer *hrtimer = &__raw_get_cpu_var(watchdog_hrtimer);..................../* Enable the perf event */watchdog_nmi_enable(cpu);
..............................
}watchdog_nmi_enable里面注册了一个hard lockup检测事件。其回调函数是watchdog_overflow_callback
我感觉可能arm也是这个样子把。看x86就是每个一段时间发出一个NMI中断。然后在回调函数里面检查中断触发的次数是否增加吧
这个硬件在x86里叫performance monitoring,这个硬件有一个功能就是在cpu clock经过了多少个周期后发出一个NMI中断出来。
static int watchdog_nmi_enable(unsigned int cpu)
{......................wd_attr->sample_period = hw_nmi_get_sample_period(watchdog_thresh);/* Try to register using hardware perf events */event = perf_event_create_kernel_counter(wd_attr, cpu, NULL, watchdog_overflow_callback, NULL);............................
}hard lockup判定:watchdog_overflow_callback->is_hardlockup
is_hardlockup:可以看到它先去读取中断被触发的次数。然后再去比较上一次NMI中断触发时保存的中断次数(hrtimer_interrupts_saved)。如果相等说明出现了hard lockup.
另外hrtimer_interrupts这个变量在方法1的喂狗软中断里面就会更新。
static int is_hardlockup(void)
{unsigned long hrint = __this_cpu_read(hrtimer_interrupts);if (__this_cpu_read(hrtimer_interrupts_saved) == hrint)return 1;__this_cpu_write(hrtimer_interrupts_saved, hrint);return 0;
}下面这种hard lockup怎么构造不出来呢? 反而一直报rcu相关的问题
int test_thread(void* a) {unsigned long flags;printk(KERN_EMERG "\r\n softlockup simulate, in_interrupt %u in_softirq %u, cpu id %d\n", in_interrupt(), in_softirq(), smp_processor_id());local_irq_disable();while (1){}return 0; }
[root@arm_test ]# INFO: rcu_sched detected stalls on CPUs/tasks: { 1} (detected by 0, t=8407 jiffies, g=-62, c=-63, q=308)
Task dump for CPU 1:
test_task R running 0 653 2 0x00000002
[<c045de78>] (__schedule) from [<c003c49c>] (kthread+0xcc/0xe8)
[<c003c49c>] (kthread) from [<c000e4b8>] (ret_from_fork+0x14/0x3c)
INFO: rcu_sched detected stalls on CPUs/tasks: { 1} (detected by 0, t=14712 jiffies, g=-62, c=-63, q=308)
Task dump for CPU 1:
test_task R running 0 653 2 0x00000002
[<c045de78>] (__schedule) from [<c003c49c>] (kthread+0xcc/0xe8)
[<c003c49c>] (kthread) from [<c000e4b8>] (ret_from_fork+0x14/0x3c)
通过top和interrupt能看到是哪个进程出问题了。
softlockup simulate, in_interrupt 0 in_softirq 0, cpu id 1//内核线程在1核上
[root@arm_test ]# cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
29: 9131 1444 9128 9112 GIC 29 twd
root@arm_test ]# cat /proc/interrupts
CPU0 CPU1 CPU2 CPU3
29: 9357 1444 9350 9332 GIC 29 twd
34: 6 0 0 0 GIC 34 timer
可以看到cpu1的twd中断不增加top可以看到test_task一直占用cpu1
Mem: 19528K used, 1013232K free, 0K shrd, 252K buff, 8944K cached
CPU: 0.3% usr 1.5% sys 0.0% nic 96.4% idle 0.0% io 0.0% irq 1.5% sirq
Load average: 1.65 0.55 0.19 2/54 787
PID PPID USER STAT VSZ %VSZ CPU %CPU COMMAND
653 2 0 RW 0 0.0 1 3.2 [test_task]
787 781 0 R 2432 0.2 0 0.2 top
7 2 0 SW 0 0.0 2 0.0 [rcu_sched]
后面知道为啥构造不出来了
hard lockup:需要CPU支持NMI(不可屏蔽中断,通常是通过CPU里的PMU单元实现的),如果PMU发现长时间(这个cycle是借助NMI来计算的,因为定时器可能不工作了)一个中断都不来,就知道发生了hard lockup,这时(触发NMI中断,中断处理函数中)分析栈就知道在哪里锁住中断的。需要把CONFIG_HARDLOCKUP_DETECTOR打开。
由于ARM里面没有NMI,因此内核不支持ARM的hard lockup detector。但有一些内核patch可以用,比如用FIQ模拟MNI(如果FIQ用于其他地方了,这里就用不了了),或者用CPU1去检测CPU0是否被hard lockup(但CPU1没办法获得线程的栈,只能知道lockup了),但这两个patch都没在主线上。FIQ在Linux中基本不用的(一般只做特殊的debugger,常规代码不用)。
————————————————
版权声明:本文为CSDN博主「落尘纷扰」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/jasonchen_gbd/article/details/79465405
如果没有这种不可屏蔽中断的芯片(例如arm),这种怎么处理呢??要不明天试试自己构造一个检测的
还是利用is_hardlockup里面的两个每cpu变量。起一个高精度定时器。每隔一段时间检查一下这两个值是不是相等。如果是相等的说明该cpu关中断了。唯一需要注意的是:假设cpu0关中断了,它自己是不能发现的,只有其他cpu帮忙检查才行。
主要代码如下watch_dog.c:
主要使用者三个变量
/*****************************************/
static DEFINE_PER_CPU(struct hrtimer, hardlock_check_hrtimer);
static DEFINE_PER_CPU(unsigned long, hrtimer_interrupts);
static DEFINE_PER_CPU(unsigned long, hrtimer_interrupts_saved);
/*****************************************/watchdog_enable里面再起一个定时器,检查是否有hardlockup
static void watchdog_enable(unsigned int cpu)
{
............................................................./* 添加hardlock定时器,用于检查hardlock的情况 */hrtimer = &__raw_get_cpu_var(hardlock_check_hrtimer);/* kick off the timer for the hardlockup detector */hrtimer_init(hrtimer, CLOCK_MONOTONIC, HRTIMER_MODE_REL);hrtimer->function = hardlock_check_callback;__this_cpu_write(hrtimer_interrupts_saved, 0);__this_cpu_write(hrtimer_interrupts, 0);/* done here because hrtimer_start can only pin to smp_processor_id() */hrtimer_start(hrtimer, ns_to_ktime(sample_period * 2),HRTIMER_MODE_REL_PINNED);
}定时器回调函数
static void hardlock_check_callback(struct hrtimer *hrtimer)
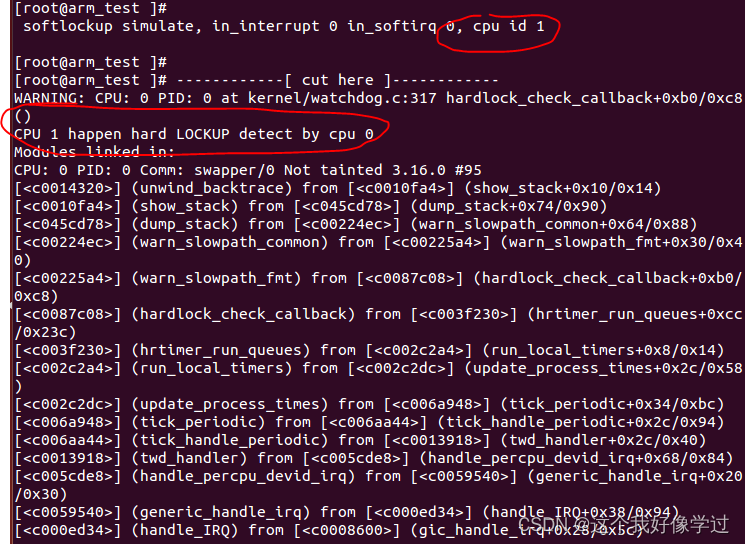
{/* check for a hardlockup* This is done by making sure our timer interrupt* is incrementing. The timer interrupt should have* fired multiple times before we overflow'd. If it hasn't* then this is a good indication the cpu is stuck*/if (is_hardlockup()) {int this_cpu = smp_processor_id();WARN(1, "CPU %d happen hard LOCKUP detect by cpu %d", (this_cpu + 1) % 4, this_cpu);//return;}/* 增加高精度定时器的超时时间,并重启定时器 *//* .. and repeat */hrtimer_forward_now(hrtimer, ns_to_ktime(sample_period * 2));return;
}watchdog_timer_fn->watchdog_interrupt_count:这个里面会更新这个值的,所以我们不用管自己用即可hrtimer_interrupts
cpu0->cpu1->cpu2->cpu3。cpu3反过来监控cpu0的计数
static int is_hardlockup(void)
{/* 每次进来先更新当前cpu的中断计数 */unsigned long cur_hrint = __this_cpu_read(hrtimer_interrupts);__this_cpu_write(hrtimer_interrupts_saved, cur_hrint);/* 读取需要监控的cpu的计数,判断是否出现hardlock */int cpu = smp_processor_id();int check_cpu = (cpu + 1) % 4;unsigned long hrint = per_cpu(hrtimer_interrupts, check_cpu);unsigned long saved_hrint = per_cpu(hrtimer_interrupts_saved, check_cpu);if (saved_hrint == hrint){return 1;}/*更新监控的cpu计数当我监控完之后,该cpu出现了一直关中断的情况,如果不更新,那么interrupts和saved是一直不相等的 */per_cpu(hrtimer_interrupts_saved, check_cpu) = hrint;return 0;
}测试代码
int test_thread(void* a)
{unsigned long flags;printk(KERN_EMERG "\r\n softlockup simulate, in_interrupt %u in_softirq %u, cpu id %d\n", in_interrupt(), in_softirq(), smp_processor_id());local_irq_disable();while (1){}//f1(10, 20);return 0;
}运行在cpu1上,cpu0负责监控cpu1(实测有误报的情况)
3、对于所有核都挂死的情况。可以借用狗叫重启设备。异常现场信息记录,可以在挂死前把所有的寄存器记录下来。
这篇关于关于单核/多核死机问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







