本文主要是介绍SIGIR'22 | 广告间排序和广告内创意优选联合优化,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1. 摘要
广告创意是展示商品内容、传达商家营销信息的直接载体。商家通常会为一个商品创作多种不同的创意,由于不同用户的关注点不同,这些候选创意所对应的投放效果则相差甚远。创意优选的目的是学习用户对于广告创意的偏好,为用户挖掘及展现最具吸引力的广告创意内容以最大化广告收益。然而,目前业内普遍的做法是将创意优选放在排序阶段之后,这将导致排序模型无法感知到广告创意,即广告内的创意选择无法影响广告间的排序,一个好的创意排在前面,会影响后面广告间的排序。针对这些问题,本文提出了一种新颖的创意优选级联结构(Cascade Architecture of Creative Selection,简称CACS),在广告排序阶段之前构建创意优选模型,以实现广告内创意优选和广告间排序的联合优化。
考虑创意优选前置所带来的效率和效果问题,我们主要做了以下工作: 1)设计一个经典的双塔结构来降低计算成本,并允许创意优选模型生成的创意表征与下游排序模型共享,避免重复计算;2)提出一种基于软标签序学习蒸馏方法(soft label list-wise ranking distillation),从强大的排序模型中提取知识来指导创意优选模型中广告内创意序的学习。除此之外,设计一种自适应 dropout 网络,鼓励模型以一定概率忽略 ID 特征,而偏向于内容特征,来平衡 ID 特征的记忆性和内容特征的泛化性,以学习创意的多模态表示。最重要的是,排序模型从 CACS 中获取到了每个广告的最优创意信息,并最终提升排序模型的效果。大量的实验结果证明了该方法在离线和在线评估中的有效性和优越性。基于该项工作整理的论文已发表在SIGIR 2022,欢迎感兴趣同学阅读交流。
论文:Joint Optimization of Ad Ranking and Creative Selection
2. 背景
创意是广告的呈现方式,它可以将丰富的产品信息以视觉的方式快速地传递给用户。尽管同一广告的不同创意代表了相同的产品,但因为展现样式上的差异,它们的点击率通常会相差甚远,因此根据用户的偏好个性化展示创意是至关重要的。淘宝搜索广告系统目前采用客户、计划、推广单元、创意的多级账户体系,如图1(a),推广单元(ad)和商品(item)通常为一一对应关系,在每个推广单元(adgroup)下广告主可以提供多组创意(creative),每组创意可以设置单独的创意标题和创意图片,这种产品设计一定程度上给广告商品提供了个性化样式展示的空间。

考虑到系统性能和效果的平衡,传统广告多阶段系统分为召回(Ad matching)、排序(Ad ranking)和创意优选(Creative selection)阶段。现有的创意优化工作都是在这个架构下集中在创意优选环节,虽然取得了不错进展但是影响面有限。排序阶段考虑到系统性能问题无法扩展到创意粒度,否则打分规模需要翻数倍无法接受,所以该阶段无法感知实际展现的最优创意(包括打分粒度在 Ad、随机选择创意、离线选择非个性化最热门创意等手段)这对于 CTR 预估而言有较大的提升空间。
理想的多阶段架构应该是召回、创意优选、排序,即先进行广告内的创意优选,然后排序阶段可以感知最优创意,从而使得系统收益最大化。但理想的架构会面临性能和效果的双重挑战,1)性能方面:创意优选前置打分个数量级的扩大,计算开销显著增加;2)效果方面:创意优选前置会面临更多没有机会展现的创意或者展现机会较少的创意,加剧了数据稀疏问题,使得基于历史反馈的学习策略有很大挑战且内容侧与id侧特征的联合学习尤为重要。
针对上述问题,本文提出了一种新颖的创意优选级联架构(Cascade Architecture of Creative Selection,简称CACS),将创意优选模块前置到排序阶段之前,以关联广告内的创意优选和广告间的排序,如图1(b)。为了提高系统性能,我们做了以下工作: 1)设计了一种经典的双塔结构,可以通过简单的双塔内积直接预测分数; 2) 创意优选模型产生的创意表征与下游排序模型共享。为了提高系统的效果性,我们提出了 1)基于软标签序学习蒸馏方法(soft label list-wise ranking distillation),学习同一个广告内创意的相对顺序而不是绝对分数,并提取排序模型的知识来指导创意优选模型的学习;2)融合创意 ID 特征与内容(图像、标题)特征,以缓解数据稀疏问题。通过自适应 dropout 网络,根据展现量自适应调整 dropout 比例,以鼓励模型忽略 ID 特征,而选择内容特征来学习创意的多模态表征。
该项工作主要成果总结如下:
我们将创意优选模块构建在排序阶段之前,同时通过高效的级联结构,优化了广告内的创意选择和广告间的排序;
从效率和效果上考虑,我们设计了以下策略: 1)设计经典的双塔结构,降低计算成本,此外在创意优选和排序之间共享创意表征,避免重复计算; 2)提出一种基于软标签序学习蒸馏方法,从强大的排序模型中“蒸馏”知识来指导 CACS 学习,并设计一个自适应 dropout 网络来平衡 ID 特征的记忆性和内容特征的泛化性;
大量的实验结果证明了我们的 CACS 方法在离线和在线实验中的有效性和优越性。
3. 方法
CACS 的总体框架如图2所示。与传统的创意优选方法相比,CACS 将创意优选模块置于广告排序阶段之前,以关联广告内的创意优选和广告间的排序。具体来说,我们提出了一个基于双塔模型 soft label list-wise loss,用来预测广告中创意的相对顺序,而不是预测绝对点击率。对于 Ad 塔,考虑到一个创意包含多个异质模态特征,我们设计了一个自适应 dropout 网络来学习多模态创意表征。值得注意的是,创意表征与下游排序模型共享。下文将详细描述 CACS 中的两个关键组件。

3.1 软标签序学习蒸馏方法 (List-wise Ranking Distillation)
训练创意优选模型,最直接的方法是预测点击率。但是存在两个问题: 1)创意选择只需要学习同一个广告内不同创意的相对顺序,而不需要准确预测 CTR 值;2)很大比例的创意无法得到充分展示,简单的双塔模型难以优化 CTR预估。在本文中,我们将这一任务视为一个序学习问题,以对同一个广告内的创意进行排序。受蒸馏学习的启发,我们提出了一种软标签序学习蒸馏方法,从教师模型(排序模型)中提取知识来指导学生模型(CACS)的学习。由于排序模型泛化能力更强大,能够较为准确地预测创意的点击率,所以我们利用排序模型来预测每条广告中创意的点击率,并将 CTR 值作为离线训练阶段创意序的 label。
与其他双塔模型相似,我们的模型由两个主要组件组成。对于 QU(query / user)塔,我们使用 Query、User 和其他上下文特性通过 DNN 生成 QU 的表征。对于广告塔,我们使用 Ad 粒度的信息和创意粒度(图片,标题和创意 ID)特征,通过 DNN 生成 Ad 的表征。然后,通过 QU 和 Ad 的双塔内积产生一个得分。对于每个广告,有多个创意得分及其对应的 soft label 。我们首先将创意序列的预测得分和 soft label CTR值 分别映射到一个排列概率分布中,然后采用交叉熵作为度量来衡量两个分布之间的差异,并最小化两个分布距离。我们使用 top1 概率,这与创意优选的目标是一致的,因为对于广告的一次 pv,只有一个创意能够被展示。每个创意成为候选集中 top1 的概率被定义为:
soft label 也采用类似的方法进行映射:
402 Payment Required
因为CTR通常是比较小的,为了突出top1概率(使分布趋向于尖锐),我们设置了温度系数。我们采用交叉熵计算了两个分布之间的距离,损失函数为:
通过最小化目标函数,获取了广告下不同创意的相对排序,并将排序模型的知识“蒸馏”传递到我们的 CACS 中。
3.2 Adaptive Dropout Network (自适应 Dropout 网络 )
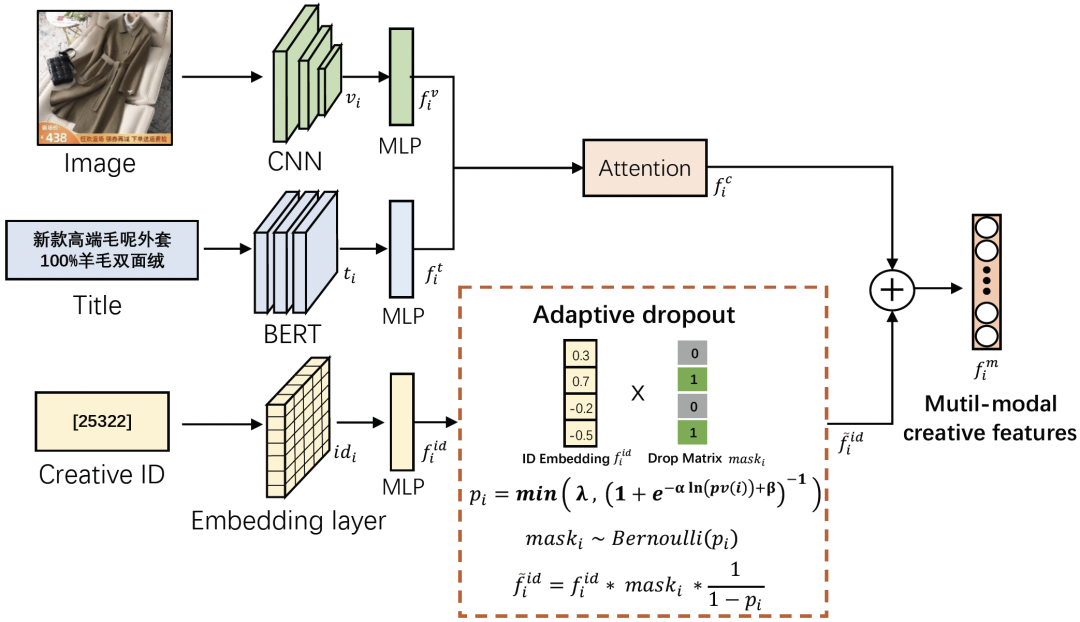
多模态创意表征的建模细节如下图3所示。首先考虑内容特征,对于输入的图文特征,我们设计两个编码器,将图像和标题特征映射到公共空间中。对于不同类别的广告,用户对图片和标题的关注度是不同的。因此,我们使用一种简单的注意力机制来学习图片和创意标题的动态权重。此外,融合创意 ID 特征和内容特征是关键,现有的方法通常使用注意力来学习不同模态的动态权重。但实验中我们发现,细粒度的 ID 强特征(比如 image_id )在多模态信息融合中会占据主导作用,导致内容信息无法有效训练,为了缓解该问题,在 Ad 侧多模态信息融合时我们提出了自适应 Dropout 网络,在训练过程中 ID 特征的 embedding 以一定的概率进行 drop,迫使模型学习图文信息的表征,drop 比例可以根据创意的展现 pv 量进行设置,考虑到 ID 特征经过一定次数的更新后,表征会逐渐趋于稳定,所以 pv 越丰富的素材可以腾出一定的比例辅助内容信息的学习,也就是说 drop 比例可以越高。
其中代表最大 drop rate,表示展现量。我们使用来规范化展现量,使用小数字防止的情况。等式右边是带有 rescale和 offset的 sigmoid 函数。pv 越大,模型在训练过程中越依赖于 ID 特征,因此我们设置了一个平滑函数来控制 drop rate,随着 pv 次数的增加, drop rate 也会增加。但不能超过阈值,以保证 ID 特征不被全部丢弃。
我们的自适应 dropout 网络避免了使用复杂的模型来融合多模态特征,能够用一个简单有效的网络来提高创意优选模型的效果。值得注意的是,在每次用户请求中,排序模型可以直接使用自适应dropout网络生成的创意表征,并与排序模型其他特征一起预测点击率,避免了重复计算。
4. 实验
4.1 在线效果
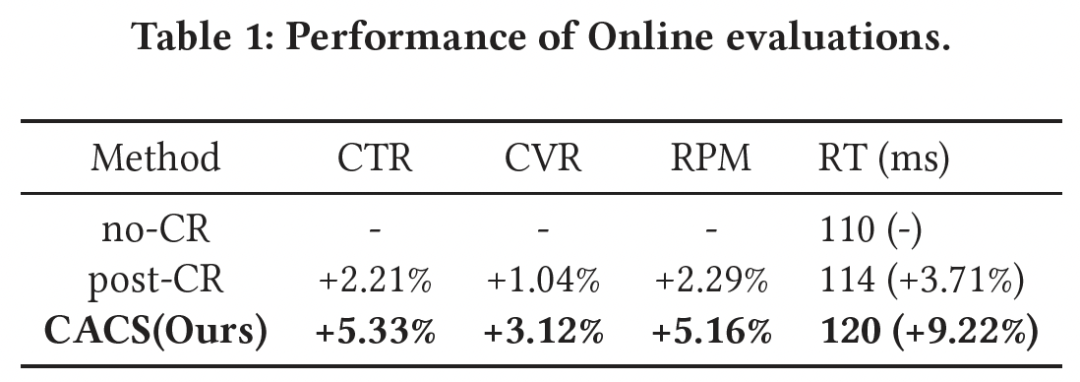
为了探究创意优选位置,我们通过在线实验对比了随机创意优选(no-CR),精排后优选(post-CR)和精排前优选(CACR)的效果收益。从表(1)可以看出,相比随机创意优选和精排后优选,精排前优选的效果提升相当显著。其中精排后优选相比随机优选 CTR+2.2%、RPM+2.2%,精排前优选相比随机优选 CTR+5.3%,RPM+5.2%,说明广告商品之间采用最优创意进行 pk 比采用平均创意 pk,能够更有效地选出优质广告。而且,由于我们采用高效双塔模型,相比精排后的复杂优选模型,性能开销上增加并不明显,rt增幅在5%左右。
4.2 离线效果
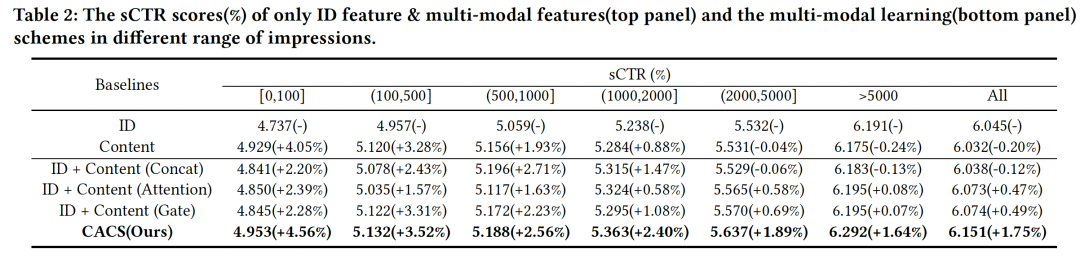
我们采用 sCTR 来离线评估不同优选模型的有效性,sCTR 指标的计算方式可以参考文献[19],主要思想是离线对每条样本的 ad 进行创意优选,如果选出创意与在线一致(样本中展现的创意)则认为这条样本是新模型产出的,统计这些样本的 ctr 来模拟新模型的效果记作 sCTR。不同版本创意优选模型的效果对比如表(2)所示,模型定义如下:
ID:表示创意侧仅采用创意 ID 特征;
Content:表示创意侧仅采用内容特征;
ID+Content (concat) :表示创意侧采用 ID 和内容特征,两者通过 concat 方式进行融合;
ID+Content (Attention) :表示创意侧采用 ID 和内容特征,两者通过 attention 方式进行融合;
ID+Content (Gate) :表示创意侧采用 ID 和内容特征,两者通过 gate 方式进行融合;
CACR (Ours) :表示我们的模型,创意侧采用 ID 和内容特征,两者通过自适应 Dropout 方式进行融合;
(1)多模态信息有效性对比
引入内容特征是常见的解决冷启动问题的方法,如表(2)上半部分所示,我们通过对比纯 ID 特征和内容侧特征,在展现次数较少(0~1000)时,加入图像特征能够有效提高优选效果,因为图像特征的泛化性更强,在低频时表现更好。然而随着展现次数的增加,仅使用id特征的模型由于记忆能力较强,效果变得越来越好,最后反超仅使用内容特征的模型。说明引入内容侧特征对于低频 Ad 的优选是有效的,但是会影响高频 Ad 的效果。
(2)多模态融合方式对比
为了平衡低频 Ad 和高频 Ad 的优选效果,我们在优选模型中同时引入了 ID 特征和 Content 特征,并探究了不同的多模态信息融合策略。对比表(2)下半部分的效果,可以看出两类特征同时加入模型,能够在低频部分取得正向收益,同时在高频部分取得接近持平的效果。而我们的模型 CACS 在低频和高频时都能有效的提高优选效果,CACS 模型由于对部分 ID 特征进行 drop,迫使模型更好地学习图像表征,所以对低频 Ad 优选比较友好;对于高频部分,引入 drop 机制能一定程度缓解过拟合风险,优选效果有小幅提升;
4.3 参数敏感性
此外,我们研究了公式(4) 中 的影响,它被用来控制最大 drop rate。如图4(a)所示,随着 的逐渐增加,效果逐渐提高,在达到的峰值后开始下降,当速率 drop rate = 0.6 时 sCTR 得分最高。此外,对于公式(4) 中控制缩放和偏移量的 ,我们将设置在 [1,1.35] 的范围内,设置在 [9,9.6] 的范围内,逐步增加。从图4(b)所示的结果中,我们可以看到性能随参数的不同值而变化,最优值分别为 1.05 和 9.1。

5. 总结
本文提出了一种新颖的创意优选级联结构,该模块在排序阶段之前构建,以关联广告内部的创意优选和广告间的排序。此外,我们设计了几个关键的策略来解决效率和效果问题,最终提高创意优选和广告排序的效果。该方案已在淘宝搜索广告平台部署上线,在线下和线上的实验中都获得显著提升。
参考文献
[1] Dzmitry Bahdanau, Kyunghyun Cho, and Yoshua Bengio. 2014. Neural ma- chine translation by jointly learning to align and translate. arXiv preprint arXiv:1409.0473 (2014).
[2] Zhe Cao, Tao Qin, Tie-Yan Liu, Ming-Feng Tsai, and Hang Li. 2007. Learning to rank: from pairwise approach to listwise approach. In Proceedings of the 24th international conference on Machine learning. 129–136.
[3] Heng-TzeCheng,LeventKoc,JeremiahHarmsen,TalShaked,TusharChandra, Hrishi Aradhye, Glen Anderson, Greg Corrado, Wei Chai, Mustafa Ispir, et al. 2016. Wide & deep learning for recommender systems. In Proceedings of the 1st workshop on deep learning for recommender systems. 7–10.
[4] Jacob Devlin, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. 2018. Bert: Pre-training of deep bidirectional transformers for language understanding. arXiv preprint arXiv:1810.04805 (2018).
[5]HongliangFei,JingyuanZhang,XingxuanZhou,JunhaoZhao,XinyangQi,and Ping Li. 2021. GemNN: gating-enhanced multi-task neural networks with feature interaction learning for CTR prediction. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval. 2166–2171.
[6] Tiezheng Ge, Liqin Zhao, Guorui Zhou, Keyu Chen, Shuying Liu, Huimin Yi, Zelin Hu, Bochao Liu, Peng Sun, Haoyu Liu, et al. 2018. Image matters: Visually modeling user behaviors using advanced model server. In Proceedings of the 27th ACM International Conference on Information and Knowledge Management. 2087–2095.
[7]HuifengGuo,RuimingTang,YunmingYe,ZhenguoLi,andXiuqiangHe.2017. DeepFM: a factorization-machine based neural network for CTR prediction. arXiv preprint arXiv:1703.04247 (2017).
[8] Kaiming He, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. 2016. Deep residual learning for image recognition. In Proceedings of the IEEE conference on computer vision and pattern recognition. 770–778.
[9] Po-Sen Huang, Xiaodong He, Jianfeng Gao, Li Deng, Alex Acero, and Larry Heck. 2013. Learning deep structured semantic models for web search using clickthrough data. In Proceedings of the 22nd ACM international conference on Information & Knowledge Management. 2333–2338.
[10]TongwenHuang,QingyunShe,ZhiqiangWang,andJunlinZhang.2020.GateNet: Gating-Enhanced Deep Network for Click-Through Rate Prediction. arXiv preprint arXiv:2007.03519 (2020).
[11]SeongKuKang,JunyoungHwang,WonbinKweon,andHwanjoYu.2020.DE-RRD: A knowledge distillation framework for recommender system. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 605–614.
[12]XiangLi,ChaoWang,JiweiTan,XiaoyiZeng,DanOu,DanOu,andBoZheng. 2020. Adversarial multimodal representation learning for click-through rate prediction. In Proceedings of The Web Conference 2020. 827–836.
[13]HBrendanMcMahan,GaryHolt,DavidSculley,MichaelYoung,DietmarEbner, Julian Grady, Lan Nie, Todd Phillips, Eugene Davydov, Daniel Golovin, et al. 2013. Ad click prediction: a view from the trenches. In Proceedings of the 19th ACM SIGKDD international conference on Knowledge discovery and data mining. 1222–1230.
[14] Sashank Reddi, Rama Kumar Pasumarthi, Aditya Menon, Ankit Singh Rawat, Felix Yu, Seungyeon Kim, Andreas Veit, and Sanjiv Kumar. 2021. Rankdistil: Knowledge distillation for ranking. In International Conference on Artificial Intelligence and Statistics. PMLR, 2368–2376.
[15]NitishSrivastava,GeoffreyHinton,AlexKrizhevsky,IlyaSutskever,andRuslan Salakhutdinov. 2014. Dropout: a simple way to prevent neural networks from overfitting. The journal of machine learning research 15, 1 (2014), 1929–1958.
[16] Hossein Talebi and Peyman Milanfar. 2018. NIMA: Neural image assessment. IEEE Transactions on Image Processing 27, 8 (2018), 3998–4011.
[17] Jiaxi Tang and Ke Wang. 2018. Ranking distillation: Learning compact ranking models with high performance for recommender system. In Proceedings of the 24th ACM SIGKDD international conference on knowledge discovery & data mining. 2289–2298.
[18] Maksims Volkovs, Guang Wei Yu, and Tomi Poutanen. 2017. DropoutNet: Addressing Cold Start in Recommender Systems.. In NIPS. 4957–4966.
[19] Shiyao Wang, Qi Liu, Tiezheng Ge, Defu Lian, and Zhiqiang Zhang. 2021. A Hybrid Bandit Model with Visual Priors for Creative Ranking in Display Advertising. In Proceedings of the Web Conference 2021. 2324–2334.
[20]ChuhanWu,FangzhaoWu,MingxiaoAn,JianqiangHuang,YongfengHuang, and Xing Xie. 2019. Neural news recommendation with attentive multi-view learning. arXiv preprint arXiv:1907.05576 (2019).
[21] Zhichen Zhao, Lei Li, Bowen Zhang, Meng Wang, Yuning Jiang, Li Xu, Fengkun Wang, and Weiying Ma. 2019. What You Look Matters? Offline Evaluation of Advertising Creatives for Cold-start Problem. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management. 2605–2613.
[22] Guorui Zhou, Na Mou, Ying Fan, Qi Pi, Weijie Bian, Chang Zhou, Xiaoqiang Zhu, and Kun Gai. 2019. Deep interest evolution network for click-through rate prediction. In Proceedings of the AAAI conference on artificial intelligence, Vol. 33. 5941–5948.
[23] Guorui Zhou, Xiaoqiang Zhu, Chenru Song, Ying Fan, Han Zhu, Xiao Ma, Yanghui Yan, Junqi Jin, Han Li, and Kun Gai. 2018. Deep interest network for click-through rate prediction. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 1059–1068.
END

也许你还想看
丨NAACL22 & SIGIR22 | 面向 CTR 的外投广告动态创意优化实践
丨SIGIR'22 | 大规模推荐系统中冷启动用户预热的融合序列建模
丨SIGIR 2022 | AdaCalib: 后验引导的特征自适应预估校准
丨阿里妈妈技术团队5篇论文入选 SIGIR 2022!


喜欢要“分享”,好看要“点赞”哦ღ~
↓欢迎留言参与讨论↓
这篇关于SIGIR'22 | 广告间排序和广告内创意优选联合优化的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





