一、数据集介绍
数据来源:今日头条客户端
数据格式如下:
6551700932705387022_!_101_!_news_culture_!_京城最值得你来场文化之旅的博物馆_!_保利集团,马未都,中国科学技术馆,博物馆,新中国
6552368441838272771_!_101_!_news_culture_!_发酵床的垫料种类有哪些?哪种更好?_!_
6552407965343678723_!_101_!_news_culture_!_上联:黄山黄河黄皮肤黄土高原。怎么对下联?_!_
6552332417753940238_!_101_!_news_culture_!_林徽因什么理由拒绝了徐志摩而选择梁思成为终身伴侣?_!_
6552475601595269390_!_101_!_news_culture_!_黄杨木是什么树?_!_每行为一条数据,以_!_分割的个字段,从前往后分别是 新闻ID,分类code(见下文),分类名称(见下文),新闻字符串(仅含标题),新闻关键词
分类code与名称:
100 民生 故事 news_story
101 文化 文化 news_culture
102 娱乐 娱乐 news_entertainment
103 体育 体育 news_sports
104 财经 财经 news_finance
106 房产 房产 news_house
107 汽车 汽车 news_car
108 教育 教育 news_edu
109 科技 科技 news_tech
110 军事 军事 news_military
112 旅游 旅游 news_travel
113 国际 国际 news_world
114 证券 股票 stock
115 农业 三农 news_agriculture
116 电竞 游戏 news_gamegithub地址:https://github.com/fate233/toutiao-text-classfication-dataset
数据资源中给出了分类的实验结果:
Test Loss: 0.57, Test Acc: 83.81%precision recall f1-score supportnews_story 0.66 0.75 0.70 848news_culture 0.57 0.83 0.68 1531news_entertainment 0.86 0.86 0.86 8078news_sports 0.94 0.91 0.92 7338news_finance 0.59 0.67 0.63 1594news_house 0.84 0.89 0.87 1478news_car 0.92 0.90 0.91 6481news_edu 0.71 0.86 0.77 1425news_tech 0.85 0.84 0.85 6944news_military 0.90 0.78 0.84 6174news_travel 0.58 0.76 0.66 1287news_world 0.72 0.69 0.70 3823stock 0.00 0.00 0.00 53news_agriculture 0.80 0.88 0.84 1701news_game 0.92 0.87 0.89 6244avg / total 0.85 0.84 0.84 54999
下面我们就来用deeplearning4j来实现一个卷积结构对该数据集进行分类,看能不能得到更好的结果。
二、卷积网络可以用于文本处理的原因
CNN非常适合处理图像数据,前面一篇文章《deeplearning4j——卷积神经网络对验证码进行识别》介绍了CNN对验证码进行识别。本篇博客将利用CNN对文本进行分类,在开始之前我们先来直观的说说卷积运算在做的本质事情是什么。卷积运算,本质上可以看做两个向量的点积,两个向量越同向,点积就越大,经过relu和MaxPooling之后,本质上是提取了与卷积核最同向的结构,这个“结构”实际上是图片上的一些线条。
那么文本可以用CNN来处理吗?答案是肯定的,文本每个词用向量表示之后,依次排开,就变成了一张二维图,如下图,沿着红色箭头的方向(也就是文本的方向)看,两个句子用一幅图表示之后,会出现相同的单元,也就可以用CNN来处理。
三、文本处理的卷积结构
那么,怎么设计这个CNN网络结构呢?如下图:(论文地址:https://arxiv.org/abs/1408.5882)
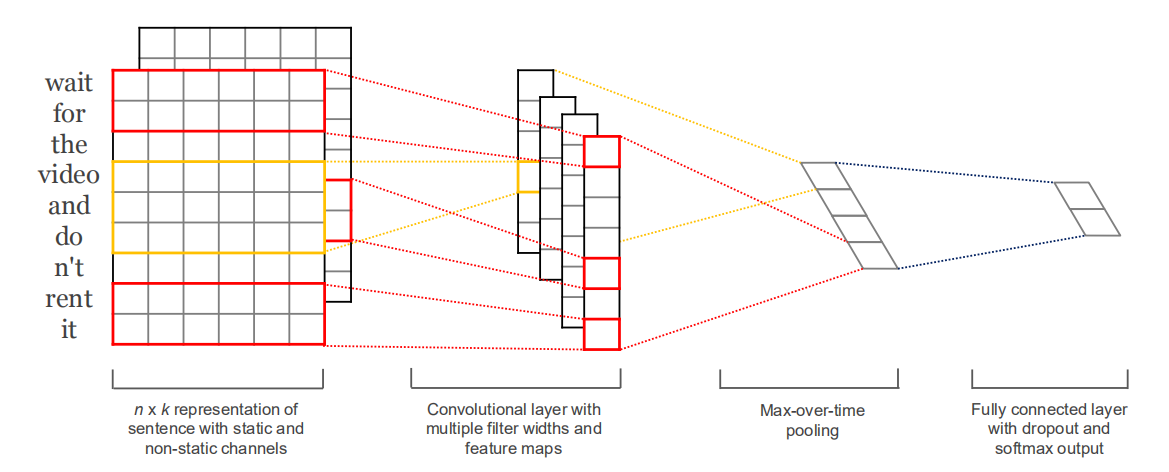
注意点:
1、卷积核移动的方向必须为句子的方向
2、每个卷积核提取的特征为N行1列的向量
3、MaxPooling的操作的对象是每一个Feature Map,也就是从每一个N行1列的向量中选择一个最大值
4、把选择的所有最大值接起来,经过几个Fully Connected 层,进行分类
四、数据的预处理与词向量
1、分词工具:HanLP
2、处理后的数据格式如下:(类别code_!_词,其中,词与词之间用空格隔开,_!_为分割符)

数据预处理代码如下:
public static void main(String[] args) throws Exception {BufferedReader bufferedReader = new BufferedReader(new InputStreamReader(new FileInputStream(new File("/toutiao_cat_data/toutiao_cat_data.txt")), "UTF-8"));OutputStreamWriter writerStream = new OutputStreamWriter(new FileOutputStream("/toutiao_cat_data/toutiao_data_type_word.txt"), "UTF-8");BufferedWriter writer = new BufferedWriter(writerStream);String line = null;long startTime = System.currentTimeMillis();while ((line = bufferedReader.readLine()) != null) {String[] array = line.split("_!_");StringBuilder stringBuilder = new StringBuilder();for (Term term : HanLP.segment(array[3])) {if (stringBuilder.length() > 0) {stringBuilder.append(" ");}stringBuilder.append(term.word.trim());}writer.write(Integer.parseInt(array[1].trim()) + "_!





