本文主要是介绍XML学习---XML文档类型定义~DTD学习,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
写这篇博客主要是为了更加深刻的巩固学的DTD。同时也是为了以后复习.
主要学习DTD的以下几部分
- DTD的作用
- DTD的元素
- DTD的属性
- DTD的实体
- DTD的使用
DTD的作用
我们在学习XML的时候知道XML是可拓展语言,所以呢,写XML文档的时候我们可以任意写,xml是用来共享、存储数据。如果我们大家都任意写XML文档,那么就不好互相共享数据。所以就需要一个规范,来控制我们写的XML文档,这就是DTD的最大作用。作用主要表现在以下几个方面
- 使用DTD可以提供一种统一的格式。XML的可扩展性为文档的作者提供了很高的灵活性,可有时候需要的是统一,要求某一类文档具有相同的结构。
- 使用DTD可以保证数据交流和共享的顺利进行。
- DTD使用户能够不依赖具体的数据就知道文档的逻辑结构。在没有XML文档的时候,也可以根据DTD为XML文档编写样式单,编写处理程序,这样可以有效地提高工作效率。
- 使用DTD可以验证数据的有效性。DTD对文档的逻辑结构进行了约束,这种约束可以比较宽松,也可以十分严格。可以根据DTD检查数据,以验证其是否符合规定和要求,这可以保证数据的正确和有效。
DTD元素
DTD定义元素的格式
<!ELEMENT Element_Name type>固定格式 ELEMENT 关键字 + 元素名+ 元素类型
元素的基本类型
- 简单型(#PCDATA):(Parsed Character Data)表示标记的内容是可解析文本,所谓的可解析文本就是非标记文本。用“#PCDATA”规范了的元素不能再包含子元素
复杂类型:复合型元素与简单型元素相对,复合型元素可包含其他元素
两种类型实例
<!ELEMENT bookinfo (title,author,publish,price)>
<!ELEMENT publisher (#PCDATA)>“#PCDATA”的用法实例
<?xml version="1.0" encoding="gb2312" ?>
<!DOCTYPE bookinfo [
<!ELEMENT bookinfo (title,author,publisher,price)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT publisher (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<bookinfo><title>计算机导论</title><author>丁跃潮等</author><publisher>高等教育出版社</publisher><price>19.7</price>
</bookinfo>复合型元素的用法,
<?xml version="1.0" encoding="gb2312" ?>
<!DOCTYPE bookinfo [
<!ELEMENT bookinfo (title,author,publish,price)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT publish (publisher,ISBN,pubdate)>
<!ELEMENT publisher (#PCDATA)>
<!ELEMENT ISBN (#PCDATA)>
<!ELEMENT pubdate (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<bookinfo><title>计算机导论</title><author>丁跃潮等</author><publish><publisher>高等教育出版社</publisher><ISBN>7-04-014768-8</ISBN><pubdate>2004.6</pubdate></publish><price>19.7</price>
</bookinfo>简单来说:简单类型就是一个可解析的文本,复杂类型就是可以包含多个字元素
元素的声明
元素可以申明成一下几种;
1.空元素的声明
格式
<ELEMENT Element_Name EMPTY>
类似Java语言的
<aa />2.不限定元素的声明:对元素不做限定,相当于没有
格式
<!ELEMENT Element_Name ANY>元素出现次数的控制
- 一个元素可能出现一次,也可能不出现。这时可通过在元素名后面加上一个“?”来实现。
- 一个元素可能不出现,也可能出现多次。这时可通过在元素名后面加上一个“*”来实现。
- 一个元素可能出现一次,也可能出现多次,但至少也要出现一次。这时可通过在元素名后面加上一个“+”来实现。
(感觉和正则表达式中的很像嘛)
DTD属性
在DTD中,属性的声明格式:
<!ATTLIST Element_name Attribute_name TYPE Default_value>其中,ATTLIST为属性声明的关键字,Element_name为元素名,Attribute_name为属性名,TYPE是属性类型,Default_value为没有设定属性值时的默认值。
简单的实例
<?xml version="1.0" encoding="gb2312" ?>
<!DOCTYPE bookinfo [
<!ELEMENT bookinfo (title,author,publisher,price)>
<!ATTLIST bookinfo ISBN CDATA "7-04-014768-8">
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ELEMENT publisher (#PCDATA)>
<!ELEMENT price (#PCDATA)>
]>
<bookinfo ISBN="7-04-014768-8"><title>计算机导论</title><author>丁跃潮等</author><publisher>高等教育出版社</publisher><price>19.7</price>
</bookinfo>属性声明中有几个要知道的点;
1.可以多次为一个元素声明其中所包含的属性:
DTD中属性声明
<!ATTLIST bookinfo id CDATA "001">
<!ATTLIST bookinfo bookcategory CDATA "文艺" >
<!ELEMENT bookinfo (#PCDATA)>对于的XML语句
<bookinfo id="001" bookcategory="文艺" >
</bookinfo>2.属性的声明在文档中的次序没有严格的要求,可位于与其相连的元素声明之前或之后。
DTD语句
<!ATTLIST bookinfo bookcategory CDATA "文艺" >
<!ATTLIST bookinfo id CDATA "001">
<!ELEMENT bookinfo (#PCDATA)>
对于的XML语句
<bookinfo id="001" bookcategory="文艺" >
</bookinfo>属性有4种不同类型的默认值,可在属性声明中的Default_value部分指定。
- default:表示使用提供的默认值,default不是一个关键字,它代表一个预设的字符串
- #REQUIRED:表示属性值必须指定。
- * #IMPLIED*:表示元素的这个属性可用可不用。
- * #FIXED*:表示元素的这个属性值是一个固定值,且必须是指定的值
* 属性的类型*
在属性的声明中TYPE部分为属性的类型设定,DTD中属性的类型有10种。
- CDATA型:简单的文本类型
- Enumerated型:枚举型,从固定类型的里面选
- ID型:和身份证一样的,唯一。所有元素的ID类型属性的属性值必须是唯一的,不可重复,
- IDREF与IDREFS型:参照ID型,就像是在固定的ID类型中选吧
<?xml version="1.0" encoding="gb2312"?>
<!DOCTYPE school [<!ELEMENT school (teacher, subject*)><!ELEMENT teacher (#PCDATA)><!ELEMENT subject (#PCDATA)><!ATTLIST teacher teach IDREFS #IMPLIED ><!ATTLIST subject number ID #REQUIRED >
]>
<school><teacher teach="c0001 c0002 c0003">丁潇</teacher><subject number="c0001">PowerBuilder</subject><subject number="c0002">AutoCAD</subject><subject number="c0003">XML</subject>
</school>- ENTITY与ENTITIES型把外部二进制形式的文件(如.jpeg、.mp3等)和外部不可解析实体链接到XML文档的功能
- NMTOKEN与NMTOKENS型:类似变量的命名规范属性
DTD中的实体
自定义实体的思想,类似于编程语言中的:变量声明和引用、自定义函数定义和调用
内部一般实体:可以在DTD 和XML中使用。
格式
<!ENTITY Eentity_name "Replacement" >Eentity_name:“变量名” Replacement:“变量值”
&Eentity_name; 调用变量
实例代码演示:

内部一般实体在DTD中引用时,有以下几方面需注意
1.不能在元素及属性的声明中引用内部一般实体,如下面的语句即为非法的
<!ENTITY pcd (#PCDATA)>
<!ELEMENT title &pcd;>2.语句中不能出现循环,如下面的语句即为非法的:
<!ENTITY thepub "北大&pub;">
<!ENTITY pub "出版社&thepub;">外部一般实体:
所谓外部一般实体就是在文档实体以外定义的,要通过一个URL才能引用到的实体。外部一般实体为独立的文件,可被多个文档所引用。正因为每一个完整的XML文档都是一个合法的实体,所以XML通过对外部一般实体的引用,可以在一个XML文档中嵌入另一个XML文档,或者将多个文档组合成一个文档。其定义的语法格式如下:
<!ENTITY Eentity_name "URL" > 使用 &Eentity_name;在引用外部一般实体时,有以下几方面需注意。
1.因为在一个文档中需引用某些外部文件,所以该文档声明中的standalone属性不再是默认值yes,而应该为no。(xml文档中的第一句)
<?xml version="1.0" encoding="utf-8" standalone="no"?>2.作为外部一般实体的文档,若使用的是XML的默认字符集即UTF-8或UNICODE,则可以在文档头部不进行XML声明,否则,必须有XML声明,且声明时,一定要说明encoding属性。
外部实体店第一句和 使用的XML文档的第一句,一样,实体的第一句可以省略。没什么用
内部参数实体:只能在DTD中引用的实体
在引用形式上,一般实体的引用为“&Eentity_name;”,而参数实体的引用则为“%Eentity_name;”
语法格式:
<!ENTITY % Eentity_name "Replacement" >实例:注意pub
<?xml version="1.0" encoding="gb2312" ?>
<!ELEMENT bookinfo (title,author,publish,price)>
<!ELEMENT title (#PCDATA)>
<!ELEMENT author (#PCDATA)>
<!ENTITY % pub "(publisher,ISBN,pubdate)">
<!ELEMENT publish %pub;>
<!ELEMENT publisher (#PCDATA)>
<!ELEMENT ISBN (#PCDATA)>
<!ELEMENT pubdate (#PCDATA)>
<!ELEMENT price (#PCDATA)>外部参数实体
语法格式
<!ENTITY % Eentity_name "URL" >外部DTD的使用
引用私有DTD文件的语法格式:
<!DOCTYPE Root_Element_name SYSTEM "URL">其中,URL为外部DTD文件的相对路径或绝对路径,该语句必须置于XML文档的头部,且在XML文档处理指令中要将standalone属性值设定为no。
引用公开DTD文件的语法格式:
<!DOCTYPE Root_Element_name PUBLIC "Public_Dtd_name" " Public_Dtd_URL">
例子
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transitional//EN" "http://www.w3.org/TR/html4/loose.dtd">其中,PUBLIC为公开DTD文件的关键字。Public_Dtd_name为公开DTD文件的文件名,这个文件名由4个部分组成:第一部分为DTD的发布者,若是ISO发布,则第一部分为ISO;若是非ISO的标准组织发布,则为“+”;若是非标准组织发布,则为“-”。第二部分为所有者的名字。第三部分为表明这个DTD文件的主要内容或类别的简要文本。第四部分为所使用的语言,该语言标志必须是ISO639所定义过的标准标志。这4部分之间用“//”隔开。Public_Dtd_URL为公开DTD文件的相对路径或绝对路径。
就下来是三个DTD使用的实例
实例一:author
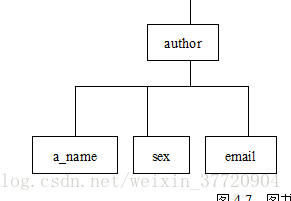
代码
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE authors[<!ELEMENT authors (author)*><!ELEMENT author (a_name,sex,email*)><!ATTLIST author id ID #REQUIRED><!ATTLIST author ISBN IDREFS #REQUIRED><!ELEMENT a_name (#PCDATA)><!ELEMENT sex (#PCDATA)><!ELEMENT email (#PCDATA)>
]>
<authors><author id="a0001" ISBN="a0001"><a_name>丁跃潮</a_name><sex>男</sex><email> ding@jmu.edu.cn</email></author><author id="a0002" ISBN="a0001"><a_name>龚涛</a_name><sex>男</sex></author>
</authors>实例一:book
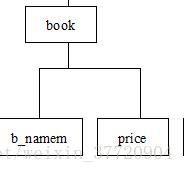
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE books[<!ELEMENT books (book*)><!ELEMENT book (b_name,price)><!ATTLIST book ISBN ID #REQUIRED><!ELEMENT b_name (#PCDATA)><!ELEMENT price (#PCDATA)>
]>
<books><book ISBN="ISBN04-014768-8"><b_name>计算机导论</b_name><price>19.7</price></book><book ISBN="ISBN04-014768-2"><b_name>JAVA大神的进阶之路</b_name><price>70000000000</price></book>
</books>实例一:publisher
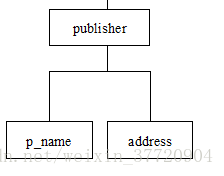
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE publishers[<!ELEMENT publishers (publisher*)><!ELEMENT publisher (p_name,address)><!ATTLIST publisher ISBN ID #REQUIRED><!ELEMENT p_name (#PCDATA)><!ELEMENT address (#PCDATA)>]>
<publishers><publisher ISBN="ISBN7-04-014768-8"><p_name>高等教育出版社</p_name><address>北京市东城区沙滩后街55号</address></publisher><publisher ISBN="ISBN7-113-05892-2"><p_name>中国铁道出版社</p_name><address>北京市宣武区右安门西街8号</address></publisher>
</publishers>
这篇关于XML学习---XML文档类型定义~DTD学习的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






