本文主要是介绍论文 | 翻译 ——A Novel K-medoids clustering recommendation algorithm……(2019:协同过滤RS),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录 <SCI 2>
0.专有词汇
0.Abstract
1.Introduction
2.Literature overview
2.1.Similarity measure
2.2.Clustering technique
3.Research framework
3.1.Item similarity based on KL divergence
3.2.A novel K-medoids clustering algorithm based on probability distribution
3.2.1.K cluster centers selection algorithm based on KL distance
3.2.2.Item clustering algorithm
3.3.Top-n recommendation
3.3.1.Selection of nearest neighbor set
3.3.2.Online top-n recommendation
4.The experiments
4.1.Experimental dataset
4.2.Evaluation indicator
4.3.Experimental result and analysis
4.3.1.ML-Latest-Small dataset
4.3.2.Yahoo Music dataset
4.4.Kolmogorov–Smirnov test
4.5.Comparison analysis
5.Conclusion and further work
0.专有词汇
probalility distribution:概率分布 Kullback–Leibler (KL) divergence:KL散度
asymmetric relationship :非对称关系 geometric distance:几何关系
mean squared difference:均方差 heuristic:启发式的
Bhattacharyya coefficient:巴氏系数 empirical cumulative distributions:经验累积分布
treatment group : 实验组 control group:对照组
0.Abstract

1.Introduction
【论述过程】
①研究背景:信息过载 → ②解决办法:信息过滤(推荐系统) → ③ 聚类推荐算法运作过程和优点论述 → ④确定文章研究框架:聚类推荐算法 → ⑤前人研究表明:距离计算公式重要性程度高 → ⑥提出问题:现有距离计算公式在稀疏矩阵上表现不好 → ⑦确定文章研究方向
【聚类推荐的运作过程】
①聚类中心选择算法确定聚类中心
②计算各对象到聚类中心的相似度,并划分,最终确定最近邻用户
③预测未知评分,生成推荐列表
【研究创新点】
①传统聚类推荐算法相似度(距离)计算公式仅考虑共有评分值:KL散度(距离)计算方法
②传统聚类推荐算法相似度(距离)计算公式对重叠对象的划分敏感度较低:KL散度(距离)的最大贡献度
③传统聚类推荐算法对象间相似度计算是对称的,含有不同评分数量的对象影响应不同:算法强调对象间非对称关系

2.Literature overview
【论述过程】
①定义CF模型空间 → ② 指出评分矩阵稀疏问题 → ③相似度计算方法 → ④聚类技术
2.1.Similarity measure
【论述过程】
①传统相似度计算方法 → ②新背景下存在问题:数据稀疏、冷启动和覆盖范围有限 →③提出新相似度测量方法 →④引出文章研究内容:KL散度的优化
2.2.Clustering technique
【论述过程】
①从聚类算法分类引出K-means →②K-means主要问题:对离群点和噪声敏感 →③引出k-means改进算法K-medoids →④K-mediods算法存在问题:几何距离很难对重叠对象进行分类 →⑤引出文章研究内容:以K-mediods为基础寻找新的距离计算方法
3.Research framework
【论述过程】
①给出新聚类推荐算法的框架并粗略解释框架流程
②KL散度(距离/相似度)公式原理说明
③商品聚类算法说明
④Top-N推荐
【框架流程】
①首先使用基于KL散度公式来计算项目之间的相似度
②基于KL散度中心选择算法确定k个聚类中心,并且相似项被聚类到同一类中
③找到类中目标项的最近邻,以计算活动用户对未分级项的预测等级,按预测分值的大小生成推荐列表

3.1.Item similarity based on KL divergence
【论述过程】
①KL散度(距离)定义(item i, item j)
②公式问题:尽管充分利用了评分信息(评价过该商品的用户数量),但忽略了商品评分的数量
③添加调节因子λ → ④改进KL散度(距离/相似度) → ⑤KL散度(距离/相似度)的其他性质:非负性 / 非对称性
- 非对称性解释:D'(i)≠D'(j),商品i的最近邻为j,但j的最近邻不一定为i



3.2.A novel K-medoids clustering algorithm based on probability distribution
【论述过程】
①目的:提升K-medoids聚类算法的效率和聚类结果,基于“改进的KL散度(距离/相似度)”对其进行改进 → KL-KM
②KL-KM算法步骤:1)找出k个聚类中心 → 基于KL散度的聚类中心选择算法
2)迭代生成聚类结果 → 商品聚类算法
3.2.1.K cluster centers selection algorithm based on KL distance
【基于KL散度的聚类中心选择算法的步骤】 共k个聚类中心
①依据“KL散度(距离/相似度)和”确定第一个聚类中心C1
②依据公式(4)迭代确定剩余k-1个聚类中心
③算法实现:



3.2.2.Item clustering algorithm
分别计算商品j∈N\{C}到各聚类中心的KL散度(距离/相似度)值,并将其划分到最小散度值对应的聚类中。

3.3.Top-n recommendation
【论述过程】
①最近邻域的选择
②在线Top-n推荐
3.3.1.Selection of nearest neighbor set
【邻域选择规则】
分别计算待预测评分的商品i所在簇Ci中其他商品到该商品的KL散度,并将计算结果升序排列,选取前n个作为商品i的邻域
3.3.2.Online top-n recommendation
【论述过程】
借助待预测评分商品的邻域计算评分,并按照评分高低进行推荐

4.The experiments
【论述过程】
①实验数据说明
②评价指标介绍
③实验结果及分析(分块实验对比)
④Kolmogorov–Smirnov检验
⑤比较分析(总体实验对比)
4.1.Experimental dataset
MovieLens 和 Yahoo Music
4.2.Evaluation indicator
评价指标分为两类:预测准确性+推荐准确性
①预测准确性:平均绝对误差(MAE)和均方根误差(RMSE)
②推荐准确性:精度(Precision)、召回率(Recall)和F1系数(F1-value)
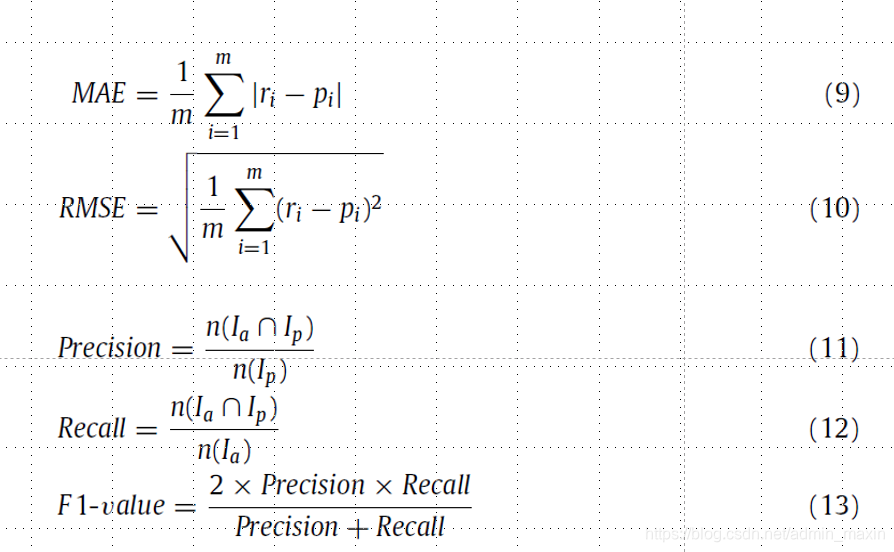
4.3.Experimental result and analysis
【论述过程】
①说明聚类数k对推荐准确性和算法表现影响很大 → ②指明评价指标:Section 4.2 → ③指明对照算法:Pearson correlation based CF、new heuristic similarity model、ombining Jaccard and MSD、Bhattacharyya Coefficient based CF。
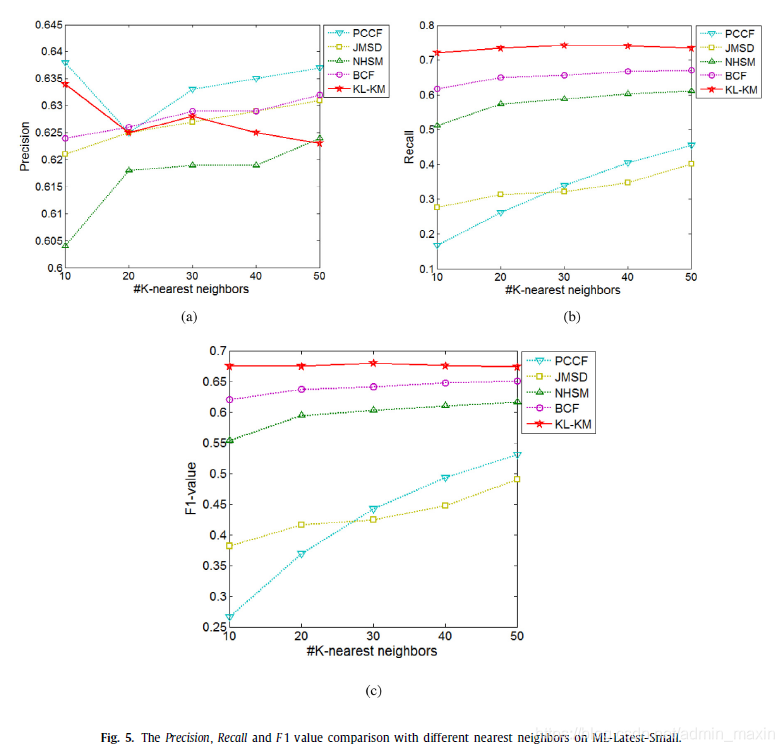
4.3.1.ML-Latest-Small dataset
【论述过程】
①聚类数k对结果的影响(图三)
②最近邻域大小对结果的影响(图四)


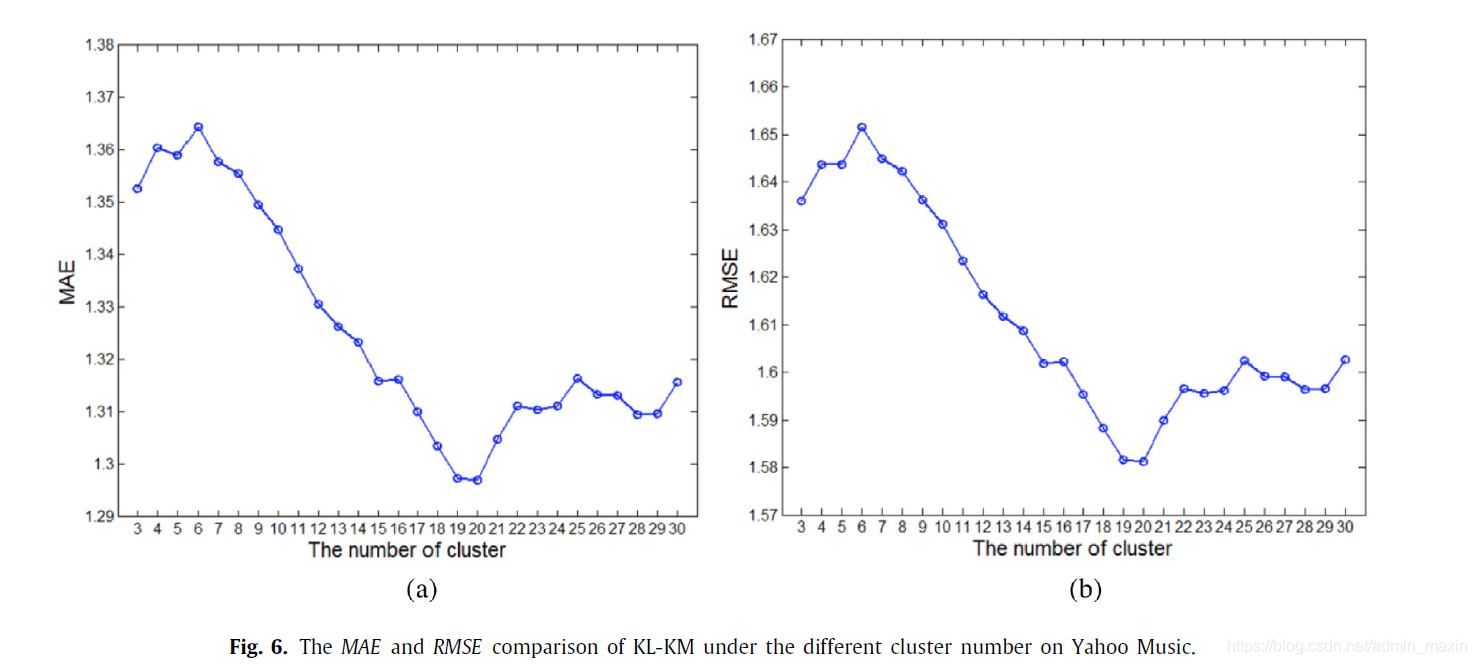
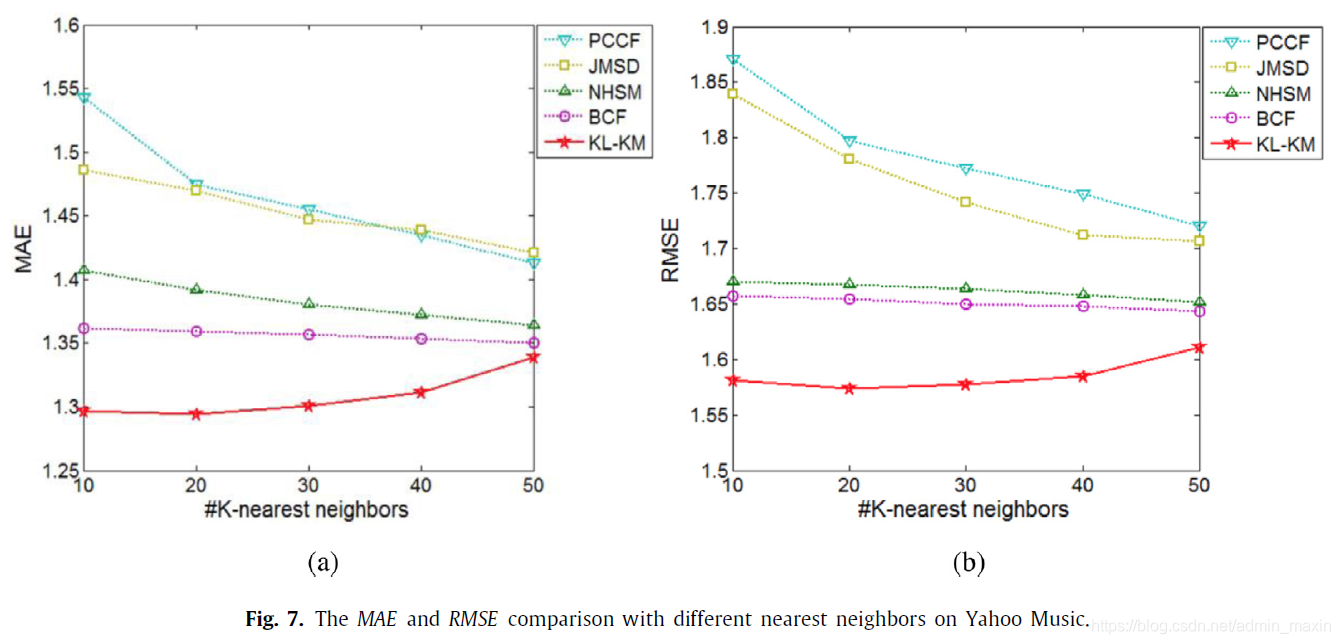
4.3.2.Yahoo Music dataset
论述过程同4.3.1,只不过实验数据集不同

4.4.Kolmogorov–Smirnov test
Kolmogorov-Smirnov检验(KS检验)是一种一维概率分布均匀性的非参数检验;它可以用来比较一个样本与一个参考概率分布,或评价两个样本。双样本KS检验是比较两个样本最有用的方法之一,因为它对两个样本的经验累积分布的位置和形状的差异都很敏感。(KS检验原理)
【双样本KS测试过程】
①每个用户的预测评分作为实验组,真实评分作为对照组
②组中的每对评分在显著性水平α=0.05下进行KS检验
③最后,使用累积测试值q作为命中数来统计KS测试的结果。
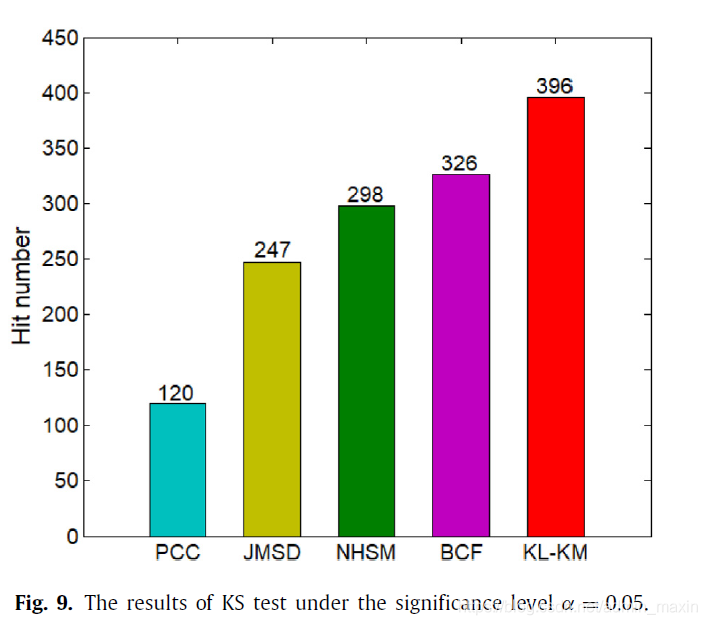
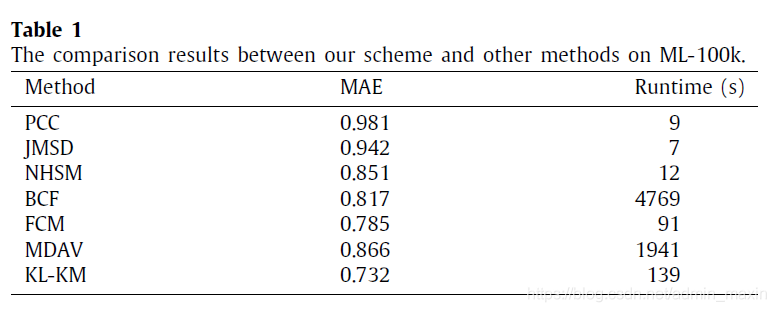
4.5.Comparison analysis
【论述过程】(总体实验对比)
①对照算法选择:分块对照实验算法+2.2节综述中聚类算法
②实验数据集:ML-100k
③实验结果分析
5.Conclusion and further work

这篇关于论文 | 翻译 ——A Novel K-medoids clustering recommendation algorithm……(2019:协同过滤RS)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





![BUUCTF靶场[web][极客大挑战 2019]Http、[HCTF 2018]admin](https://i-blog.csdnimg.cn/direct/ed45c0efd0ac40c68b2c1bc7b6d90ebc.png)
