本文主要是介绍pandas读取excel问题解答 python3-No CODEPAGE record, no encoding_override: will use ‘ascii‘,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
*** No CODEPAGE record, no encoding_override: will use 'ascii' 报错信息
UnicodeDecodeError: 'ascii' codec can't decode byte 0xb6 in position 0: ordinal not in range(128)
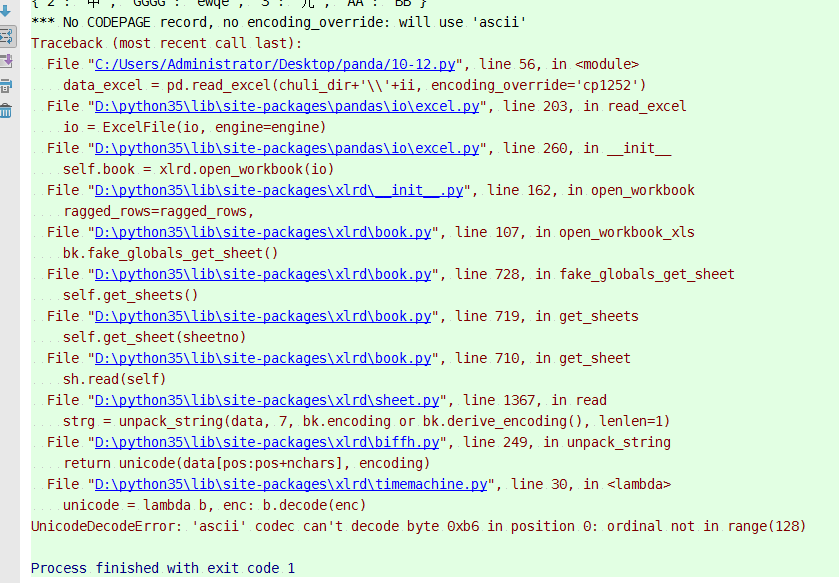
前几天在用 python3 pandas读取旧的excel(2003版本)时, 遇到了这样的报错。
在stackoverflow 和百度都搜了搜。感觉还是找不到原因所在
参考了这个 改编码的方式, workbook=xlrd.open_workbook('harvest.xls',encoding_override='cp1252')
encoding_override='cp1252'试了 , "ISO-8859-1"这编码也试了,都不能成功。
然而,这些excel 在电脑上用微软excel手工打开保存后,接着跑程序处理就没问题了。
于是想到折中的办法,用自带的os模块, xlutils.copy ,唤起excel程序。 copy重新保存一遍试试,
(感兴趣的朋友可自行尝试).
方法如下: (ii 是excel文件名)
from xlutils.copy import copy
file1= xlrd.open_workbook(chuli_dir +'\\'+ii ,encoding_override=sys.getfilesystemencoding() )
file = copy(file1)
chulihou ='D:\处理表格\hc'+'\\'+ii
file.save('D:\处理表格\hc'+'\\'+ii)
新建个hc文件夹, 旧excel是 file1 ,用from xlutils.copy import copy 。
先用sys模块的获取当前文件编码 ,来打开旧excel。
然后复制一份到 hc 目录下,再从hc 目录开始工作:
data_excel= pd.read_excel(chulihou ,dtype=str)
得到pandas 的dataframe 格式的data_excel 。
成功了!
这篇关于pandas读取excel问题解答 python3-No CODEPAGE record, no encoding_override: will use ‘ascii‘的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





