本文主要是介绍论文笔记《FID_A_Faster Image_Distribution_System_for_Docker_Platform》,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
论文笔记:《FID:_A_Faster Image_Distribution_System_for_Docker_Platform》
会议:FASW@SASO/ICCAC 2017
时间:2017
参考文献:Kangjin W, Yong Y, Ying L, et al. Fid: A faster image distribution system for docker platform[C]//2017 IEEE 2nd International Workshops on Foundations and Applications of Self Systems (FAS* W). IEEE, 2017: 191-198.
该博客中文字部分为个人总结,图片和代码等有部分出自文献,如有侵权,请指出
梗概
大规模容器平台进行镜像拉取时容易使得流量泛滥,给 docker 仓库导致负担或失败;继而推出 P2P 大规模镜像分布式系统。通过充分利用Docker Registry以及群集中其他节点的带宽,能够加快Docker映像分发的速度。
实验表明,FID 能有效减少网络流量和减少镜像分配时间
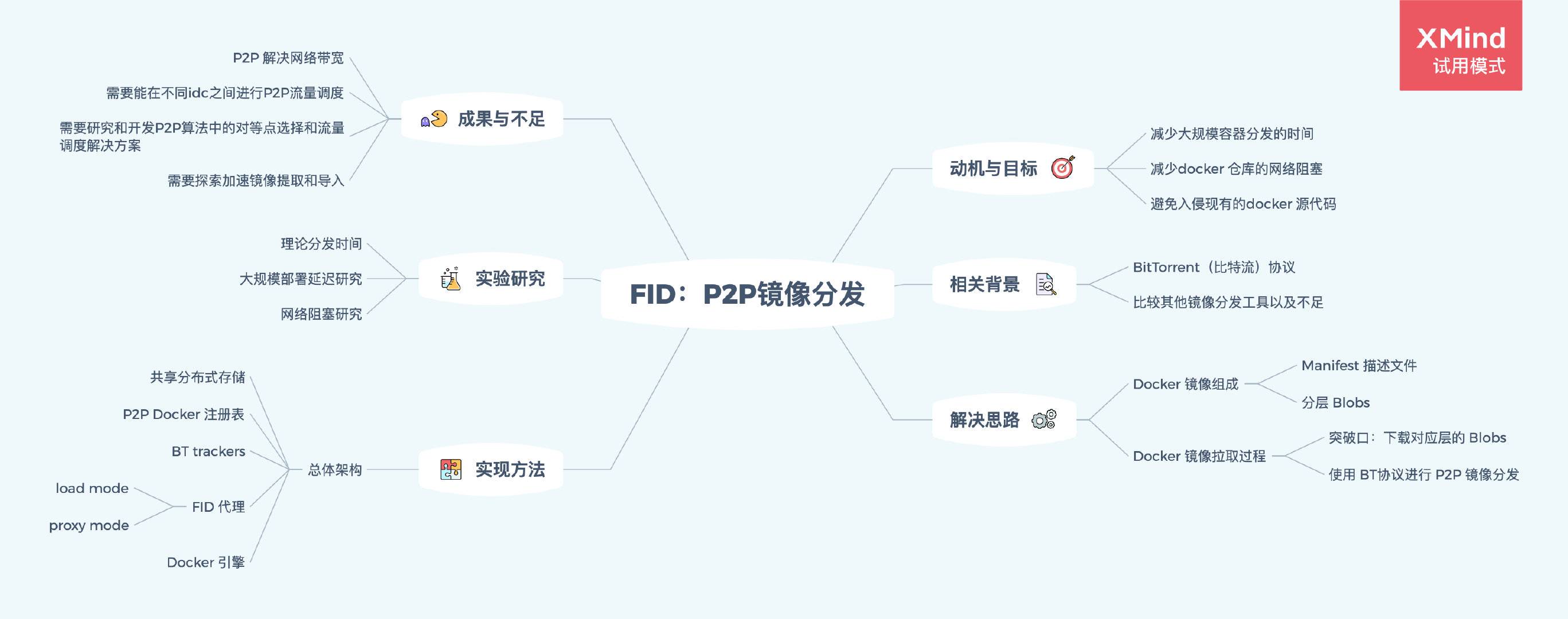
笔记思维导图:
1. 介绍
腾讯容器管理平台:Gaia
P2P镜像分发系统:FID
参考 Docker Distribution
2. 动机与目标
大型容器部署作业的特点
- 高并发:相同的镜像拉取请求同时发送
- 简单的网络结构:内部互联
- 稳固的P2P网络:节点不会频繁加入或删除
部署更多的Dokcer Reigstry 可以一定程度上解决问题,但是不能完美解决,而且会影响共享的存储
Docker 镜像分发目标:
-
减少大规模容器分发的时间
分发时间定义:所有目标节点提取图像的平均时间。
区别分发时间和拉动时间:拉动时间指单个实例拉取镜像的耗时,而分发时间指一组拉动实例
-
减少docker 仓库的网络阻塞
在集群中执行大规模部署任务时,会增加Docker仓库负担,也会导致其他请求延迟加大
为日后集群扩展方便
-
避免入侵现有的docker 源代码
这里不是指 网络安全 方面的侵入,是指源代码的修改,运行和维护
即对于源码的修改侵入
3. 相关工作
BitTorrent(比特流)协议
BitTorrent(简称BT)是一个文件分发协议,每个下载者在下载的同时不断向其他下载者上传已下载的数据。而在FTP,HTTP协议中,每个下载者在下载自己所需文件的同时,各个下载者之间没有交互。当非常多的用户同时访问和下载服务器上的文件时,由于FTP服务器处理能力和带宽的限制,下载速度会急剧下降,有的用户可能访问不了服务器。BT协议与FTP协议不同,特点是下载的人越多,下载速度越快,原因在于每个下载者将已下载的数据提供给其他下载者下载,充分利用了用户的上载带宽。通过一定的策略保证上传速度越快,下载速度也越快。在很短时间内,BitTorrent协议成为一种新的变革技术。
DID by VMWare Harbor
DID(Harbor P2P 版本): P2P 镜像分发,通过使用 Bit Torrent 协议达成
使用 P2P 分发还是 Docker 原生拉取,这里有一个平衡点,取决于镜像大小和集群规模
在 DID 中,控制器必须先下载整个镜像,这会增加镜像分发的时间,P2P 分发只能在控制器拉取整个镜像后并成为seeder后才能开始
Quay
商业项目
支持基于 rkt 的镜像格式(注重安全,基于标准的容器引擎)
和 DID 类似,不支持 P2P,流程如下:
一个节点必须先下载整个映像,而其他节点正在等待或从Docker Registry中拉取映像,一旦完成第一个下载过程,并且该节点成为第一个种子,那么P2P网络中的所有其他节点都可以通过BitTorrent将Docker映像下载到本地磁盘。
Docket
Dokcet 为整个Docker 镜像生成 torrent 文件,然后客户端使用文件下载镜像的原始码文件
下载整个镜像文件是的 Dokcet 无法复用已存在于本地磁盘的 layer 文件,这将导致网络资源的浪费
三者的通病
都需要为整个 Docker 镜像下载文件,尽管一些 layers 文件已经存在了
类似的解决办法
VDN方法:将虚拟镜像切割成块,但考虑到 Docker 镜像是由许多层级组成的,分发Docker 镜像在块级别可能会破坏Docker 的层级结构
4. 解决办法
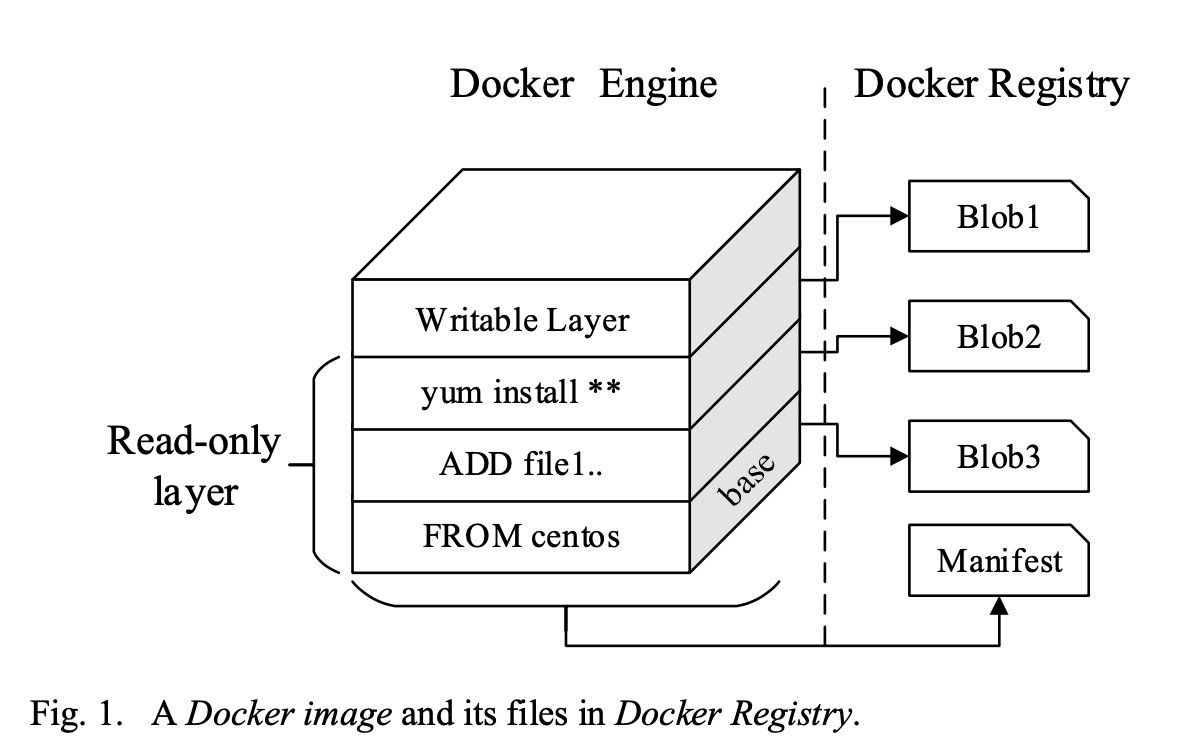
Docker 镜像组成
一个 Docker 镜像由一组 layers 层组成。每层是一个只读的文件系统,一层包括一些文件或文件夹。
一个 Docker 镜像在 Docker 注册表中是以两种主要类型的静态文件存储的:Manifest(清单)和 Blobs(块)
Manifest 描述镜像的元信息,指出镜像的层信息以及每层的 Blob。
Blob 是一个层的压缩文件,每层对应一个 Blob
在Docker 引擎 和 在 Docker 注册表中,镜像的表示和存储方式是不同的,但是都能对应上
Docker 镜像拉取过程
- 获取镜像的 Manifest 信息文件
- 找出不在本地的 layers
- 下载 Blobs 如果对应层找不到
- 解压 Blobs 并导入到 Docker 引擎
Manifest 文件很小,所以该优化的点应该是 Blob 文件下载
若打算使用 P2P 镜像拉取优化,可以在第三步中找到突破口
内部网络拓扑结构比因特网更稳固,在英特网中节点可以任意加入和退出
故我们可以使用 BT协议进行 P2P 镜像分发。
每个 blob 都需要一个 torrent 文件, docker 仓库应该是 torrent 文件的生产者和初始的seeder;生成 torrent 文件的时机是 blob 上传成功的时候,所以 Docker 注册表需要提供 torrent 文件拉取接口
注册中心提供了通过HTTP获取清单和Blob的接口。
另一种方法是通过 Docker load 方式获得 blobs 和层配置的 tar 压缩包文件
5. 实现
FID 架构图如下:
这篇关于论文笔记《FID_A_Faster Image_Distribution_System_for_Docker_Platform》的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






