本文主要是介绍贫血模型与充血模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
我们先了解一下事物脚本和领域模型的概念。
事物脚本: 事务脚本的核心是过程,通过过程的调用来组织业务逻辑,每个过程处理来自表现层的单个请求。大部分业务应用都可以被看成一系列事务,从某种程度上来说,通过事务脚本处理业务,就像执行一条条Sql语句来实现数据库信息的处理。事务脚本把业务逻辑组织成单个过程,在过程中直接调用数据库,业务逻辑在服务(Service)层处理。
领域模型: 领域模型的特点也比较明显, 属于面向对象设计,领域模型具备自己的属性行为状态,并与现实世界的业务对象相映射。各类具备明确的职责划分,领域对象元素之间通过聚合和引用等关系配合解决实际业务应用和规则。可复用,可维护,易扩展,可以采用合适的设计模型进行详细设计。缺点是相对复杂,要求设计人员有良好的抽象能力。
大家很奇怪吧,标题不是“贫血模型与充血模型的对比”吗,怎么扯到事物脚本和领域模型上了呢。我是这样理解的:在面向事物脚本编程中所使用的对象就是我们今天的主角之一“贫血模型”,当然领域模型自然也就对应着“充血模型”。那么他们最大的区别在哪里呢?其实Marth Folwer的贫血模型一文中已明确说明贫血模型是一种反模式,它根本就不是面向对象的产物,违反面向对象的核心思想,而充血模型则契合面向对象的思想。换句话说,贫血模型中只有属性,不存在领域操作,仅仅是被当做一种数据结构来使用。而充血模型有血有肉,既有属性,又有领域操作,贯彻面向对象的思想。啰嗦了…
又想起来一点,在阅读池建强老师在infoq上的领域驱动设计和实践与《领域驱动设计-软件核心复杂性应对之道》一书过程中才恍然大悟到:运用面向对象语言不一定编写出来的就是面向对象的程序。然觉悟到,原来从开始到现在所编写的程序统统与面向对象有出入,乃纯粹的面向事物脚本或者说面向过程化编程。
言归正传,首先我们从使用贫血模型与使用充血模型编程时,各自分包的特点。
贫血模型的包结构,如下图:
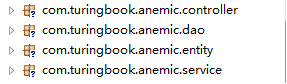
这个结构是我在实际开发中使用的,大家看着是否有熟悉的感觉!解释起来也很轻松,entity自然就是放实体(也就是贫血模型聚居地),dao自然是与数据库或其他持久策略交互的地方,service作为整个应用的核心,负责处理所有的逻辑,处理完成后交给dao做持久,controller起到调度的作用,其实就是一个个servlet。嘿嘿,熟悉吧,MVC模式。
《领域驱动设计》中建议的,使用充血模型时的包结构(更准确的说是DDD的包结构),如下图:
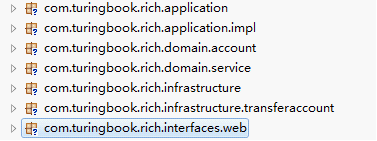
这个解释起来就比上一个要费劲很多,用两幅借来的图解释。 图中就是DDD中的四层结构,交互关系如下图:
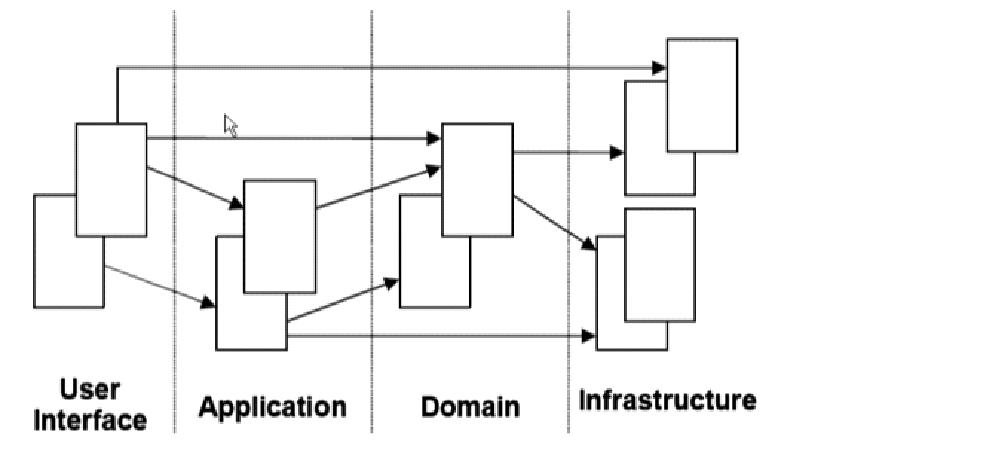
四层的职责分配:
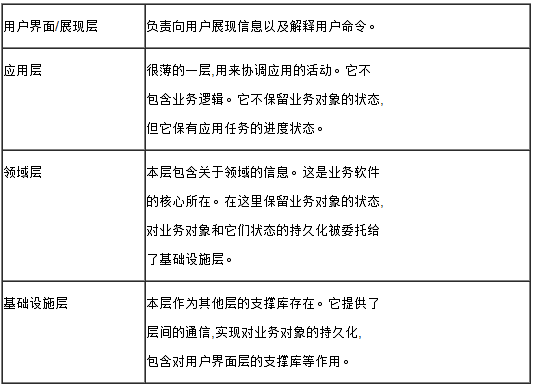
其中值得注意的地方是,应用的核心是领域层。
呀,说了好多,也不知道大家是否能理解,估计看到这里都厌烦了吧。
稍微总结一下:我的体会是,贫血模型与充血模型之间的差别一定程度上造成了面向过程化编程和面向对象编程的两个分支。那么差别到底是什么呢?说起来很简单,就是业务逻辑由谁去处理。贫血模型仅仅被当做数据结构来使用,而充血模型会持有业务逻辑方法。
其次我们通过一个例子,展现一个贫血模型与充血模型中显而易见的差别。 场景:一个网上银行的简单示例,要求可以存钱、取钱、转账、操作成功后需发送邮件给持卡人。要求提供贫血模型和充血模型两种实现方式。(例子不是那么恰当,网银怎么取钱、存钱啊,只为说明问题。)
首先我们看下贫血模型是如何实现的。
类图如下:
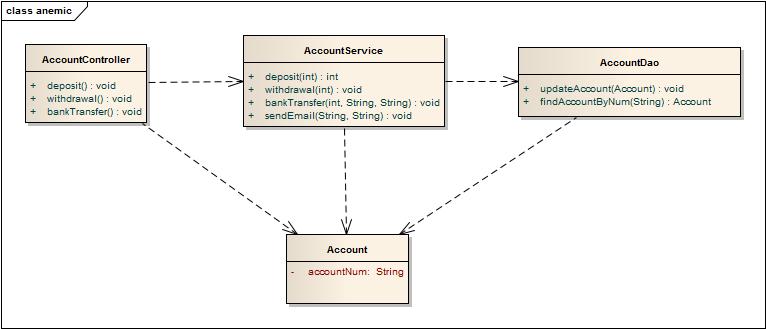
转账序列图如下:
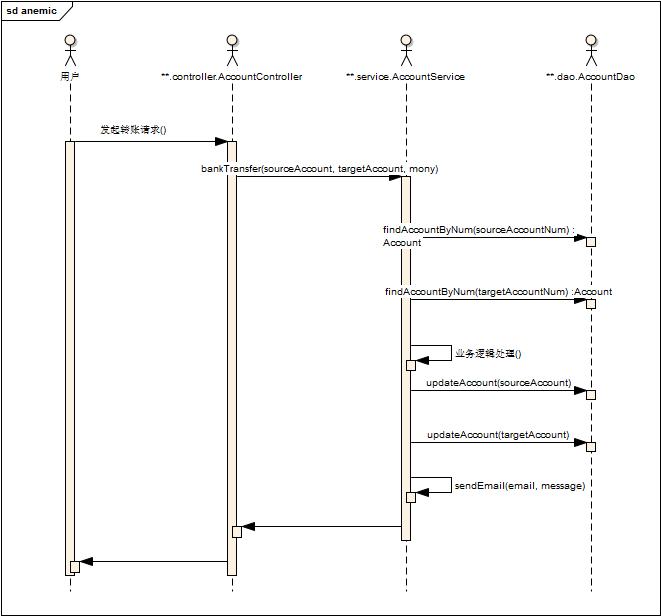
在交互的过程中,你会发现,核心确实是service层。
其他部分都省略,在图中也能看个究竟,只贴出Account.java的代码:
public class Account implements Serializable {
private static final long serialVersionUID = 2248636870918341727L;private String accountNum;
private int totalAcount;
private String name;
private String cardNum;//此处省略get、set方法
充血模型的实现
类图如下:
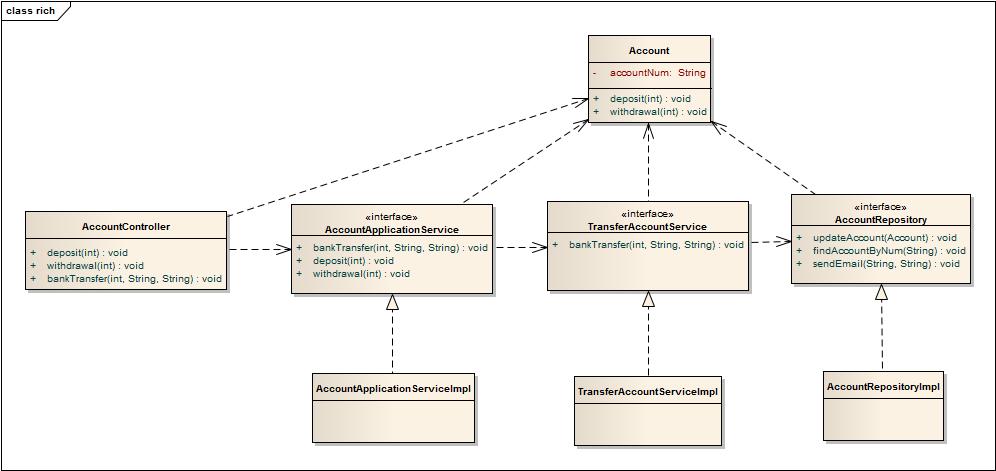
转账序列图:
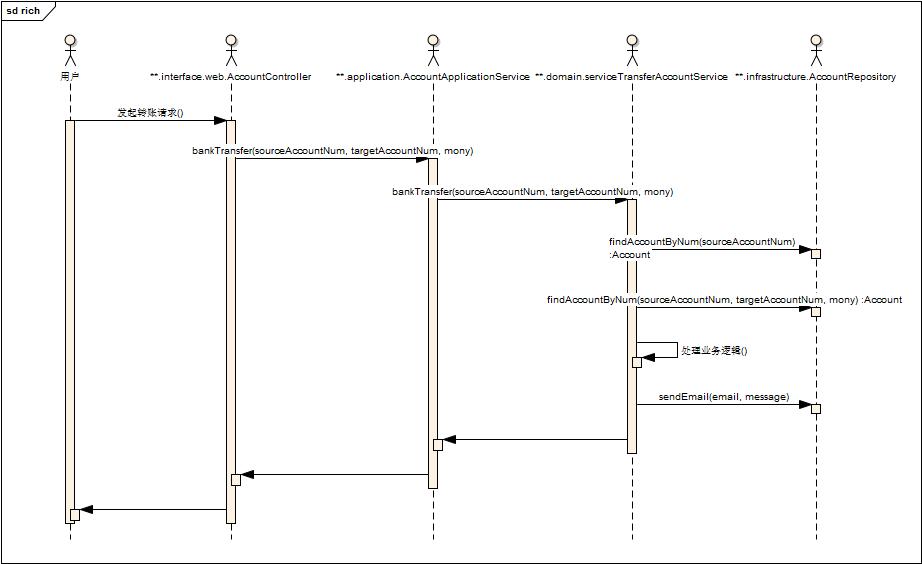
同样贴出Account.java:
public class Account implements Serializable {
private static final long serialVersionUID = -4767597926507768285L;private AccountRepository accountRepository;private String accountNum;
private int totalAcount;
private String name;
private String cardNum;public void deposit(int mony){if(mony <= 0)return;this.totalAcount = this.totalAcount + mony;accountRepository.updateAccount(this);
}public void withdrawal(int mony){if(mony <= 0)return;if(mony > this.totalAcount)return;this.totalAcount = this.totalAcount - mony;accountRepository.updateAccount(this);
}
不知道大家看出来区别了没有,充血模型是有血有肉的,核心领域方法都放到模型去去,而不是把领域方法放到模型之上的service层中去。
引用别人对贫血模型和充血模型的总结(没记错的话应该是javaeye的robbin总结的):
对于Java来说,更加适合采用贫血的模型,Java比较适合于把一个复杂的业务逻辑分离到n个小对象中去,每个小对象描述单一的职责,n个对象 互相协作来表达一个复杂的业务逻辑,这n个对象之间的依赖和协作需要通过外部的容器例如IoC来显式的管理。但对于每个具体的对象来说,他们毫无疑问是贫 血的。
这种贫血的模型好处是:
1、每个贫血对象职责单一,所以模块解藕程度很高,有利于错误的隔离。
2、非常重要的是,这种模型非常适合于软件外包和大规模软件团队的协作。每个编程个体只需要负责单一职责的小对象模块编写,不会互相影响。
贫血模型的坏处是:
1、由于对象状态和行为分离,所以一个完整的业务逻辑的描述不能够在一个类当中完成,而是一组互相协作的类共同完成的。因此可复用的颗粒度比较 小,代码量膨胀的很厉害,最重要的是业务逻辑的描述能力比较差,一个稍微复杂的业务逻辑,就需要太多类和太多代码去表达(针对我们假定的这个简单的工时管 理系统的业务逻辑实现,ruby使用了50行代码,但Java至少要上千行代码)。
2、对象协作依赖于外部容器的组装,因此裸写代码是不可能的了,必须借助于外部的IoC容器。
对于Ruby来说,更加适合充血模型。因为ruby语言的表达能力非常强大,现在用ruby做企业应用的DSL是一个很热门的领域,DSL说白了就是用来描述某个行业业务逻辑的专用语言。
充血模型的好处是:
1、对象自洽程度很高,表达能力很强,因此非常适合于复杂的企业业务逻辑的实现,以及可复用程度比较高。
2、不必依赖外部容器的组装,所以RoR没有IoC的概念。
充血模型的坏处是:
1、对象高度自洽的结果是不利于大规模团队分工协作。一个编程个体至少要完成一个完整业务逻辑的功能。对于单个完整业务逻辑,无法再细分下去了。
2、随着业务逻辑的变动,领域模型可能会处于比较频繁的变动状态中,领域模型不够稳定也会带来web层代码频繁变动。
好像在里面掺杂了好多东西,如果大家觉得罗嗦,可以看看这篇讲领域模型的文章,比我写的好,哈哈。链接在此:http://www.blogjava.net/GandofYan/archive/2006/05/30/48954.html
其实仅仅就这个例子的两种实现,还有太多太多的东西要去讲,但不是本篇的重点。学海无涯啊,领域驱动设计这方面的文章,在看书的过程中有任何感悟时我会陆续发到社区中。
参考资料:http://www.infoq.com/cn/articles/cjq-ddd
这篇关于贫血模型与充血模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









