本文主要是介绍爬取猎聘网招聘信息,我竟发现了最实用的程序员学习路线!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转自:https://mp.weixin.qq.com/s/lmGsjZdNP9HVlegBRMOZQw
前两天,刚好看到网上的一些学习路线图,又对比了招聘网站上的要求,发现这两者其实差不多。
所以就用爬虫爬取了猎聘网上的岗位信息,对这些招聘信息进行处理,从中找出需要掌握的一些语言和工具,从而有目的地进行学习,更快的提高自己的能力,让自己不再为不知道学习线路而烦恼,也能够更好的符合招聘要求。

查看网页
搜索首页
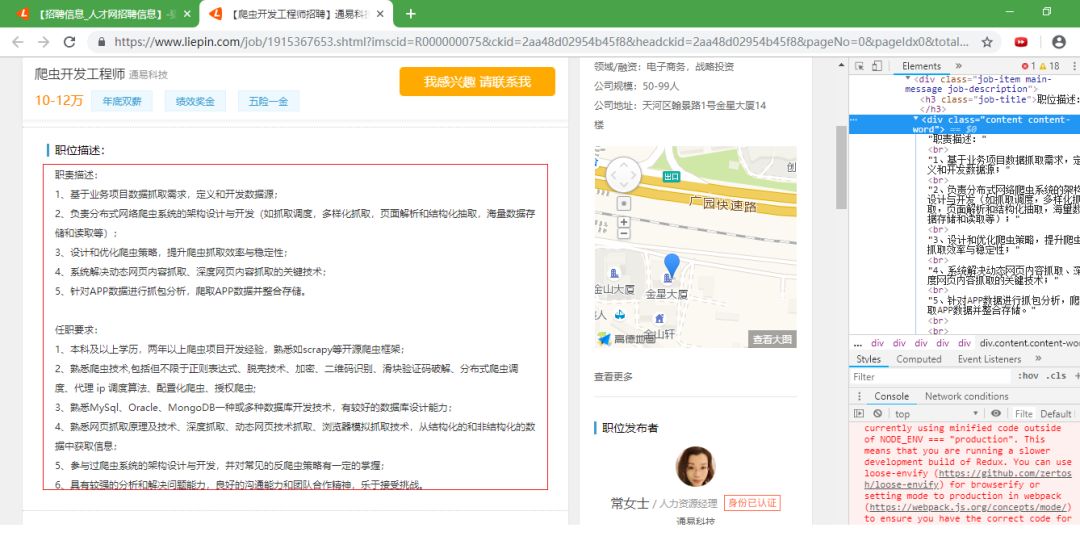
详细要求
从这个岗位职责中,可以看出需要掌握的工具或语言绝大多数都是以英文为主。所以主要提取英文就行了。至于其他的信息就不进行提取了
![]()

流程
-
爬取搜索到的岗位链接;
-
进一步爬取详细的岗位要求;
-
提取其中英文单词;
-
pyecharts展示。
-
爬取招聘岗位
-
使用BeautifulSoup进行解析,主要将岗位名称、详细链接、公司、薪资、位置和学历要求这几个信息存到MongoDB中就好。
-
def getLink(seachname, pagenum):for i in range(pagenum):url = "https://www.liepin.com/zhaopin/?init=-1&key={}&curPage={}".format(seachname, i)web_data = requests.get(url=url, headers=header)soup = BeautifulSoup(web_data.content, 'lxml')job_list = soup.select(".sojob-list > li")for item in job_list:name = item.select(".job-info > h3")[0]['title']link = item.select(".job-info > h3 > a")[0]['href']company = item.select(".company-name > a")[0].textsalary = item.select(".text-warning")[0].textlocation = item.select(".area")[0].texteducation = item.select(".edu")[0].textdata = {"title": name,"link": link,"company": company,"salary": salary,"location": location,"education": education,}pywork.insert(data) #使用MongoDB存储
-


详细岗位要求
由于任职要求中有<br>标签,需要将其切除,而且由于使用BeautifulSoup解析,所以<br>是tag对象,需要创建对象再删除。被这个问题困住了好久。之后将所有爬取到的岗位要求都写到一个文件中,方便后期使用JieBa切分。
def getInfo(url, demands_text):web_data = requests.get(url, headers=header)soup = BeautifulSoup(web_data.content, 'lxml')try:demands = soup.select(".content-word")[0].contentsdemands = sorted(set(demands), key=demands.index)# 删除<br/>delete_str = "<br/>"br_tag = BeautifulSoup(delete_str, "lxml").brdemands.remove(br_tag)# 拼接所有要求for item in demands:demands_text += item.replace("
", "")#写入文件f = open('demands.txt', mode='a+', encoding='UTF-8')f.write(demands_text + "
")f.close()except:logging.log("warning...")

分词
使用JieBa分词之后,还需要将一些单词例如:or,pc等上删除,本着“宁可错杀一千,不可放过一个”的原则,所以将少于1个字母的单词使用正则去掉
def CutWordByJieBa(txt, seachname):seg_list = jieba.cut(txt, cut_all=True)w1 = "/ ".join(seg_list) # 全模式fil = re.findall('[a-zA-Z]{1,}/', w1) # 提取英文strl = ""for i in fil:strl += istrl = strl.lower() # 全部转换为小写

可视化
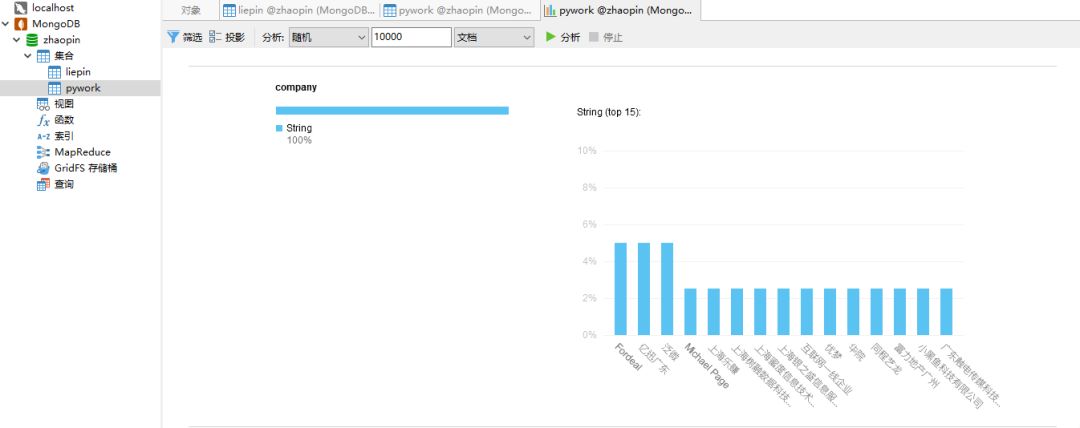
在这部分,之前只想着将需要掌握的工具用词云进行展示就好。然而,有点幸运呀!当使用Navicat12连接到MongoDB的时候,发现它有自动作图分析的功能。所以先用Navicat中的功能,简单的来看一下总体情况:
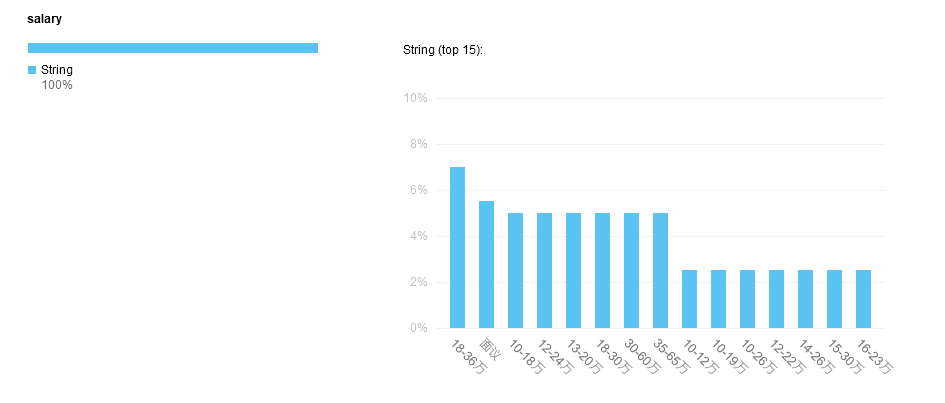
以爬虫工程师为关键词查询后,使用pyecharts进行数据展示:

重点
![]()

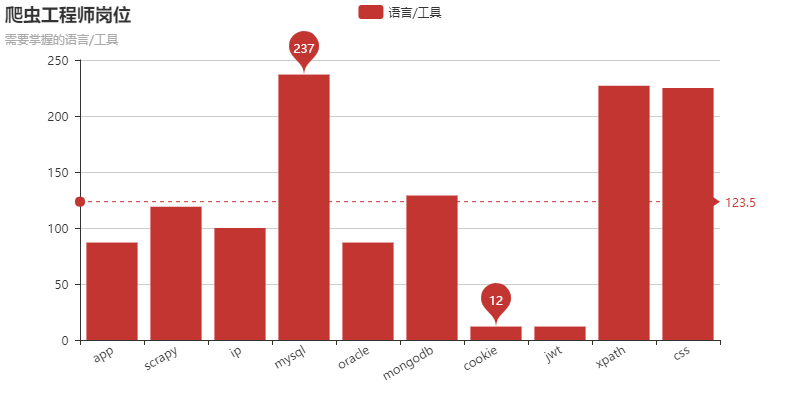
对比词云和bar图,感觉词云更加准确。但是柱状图却更便于分类,比如上图就可以发现需要掌握的工具可以分为三类:
-
数据库:MySQL、Oracle、MongoDB;
-
解析:XPath、CSS;
-
反爬:Cookie、IP、Scrapy、JWT。
其中JWT(JSON Web Token)我就不认识。所以通过这种方式,我就可以找到自己的盲区,就算不深入了解学习,但是百度一下,大概了解它是什么,还是可以的

最后
如果有感兴趣的小伙伴,可以自己动手试一下。个人感觉这些排名前10的工具对自己的学习线路、职业规划还是有点帮助的。也希望能够对那些正在迷茫的朋友有所帮助!
作者简介:Don Lex,在校大学生,正在发育并且渴望成为一个有技术、有情怀的coder。个人公众号 Python绿洲。
声明:本文为作者投稿,版权归对方所有。
这篇关于爬取猎聘网招聘信息,我竟发现了最实用的程序员学习路线!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








