本文主要是介绍如何把GPT本地化,建立个人和小企业的知识库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文阅读约需要5分钟,新手跟着实操过程约15分钟。
本文章将教大家如何建立本地的GPT,它的内核是meta不是openAI的。该模型对电脑配置需求不高,因此能力天花板也较低,但是完全能为小企业和个人所用了。学会后甚至可以直接对接小型企业,为他们打造内部知识库赚钱钱,具体对接实操容我先试试水,先和大家分享一下想法。
模型的终极能力
- 只要放入高质量的企业产品信息,就可以打造成小企业的知识库,该知识库可以赋予给AI客服,让AI高水平地回答咨询者的任何问题,从而降本增效。另一方面,AI回答的水平取决于知识库的丰富程度。
实操最低配置
- 一台运行内存至少是4G的电脑,纯看CPU。
- 不需要API,因为是部署在本地的,电脑上限就是模型的上限。
本地化布置过程
- 直接下载“软件包”:链接
- 下载完成后,压缩包解压到当前文件夹内,见下图。
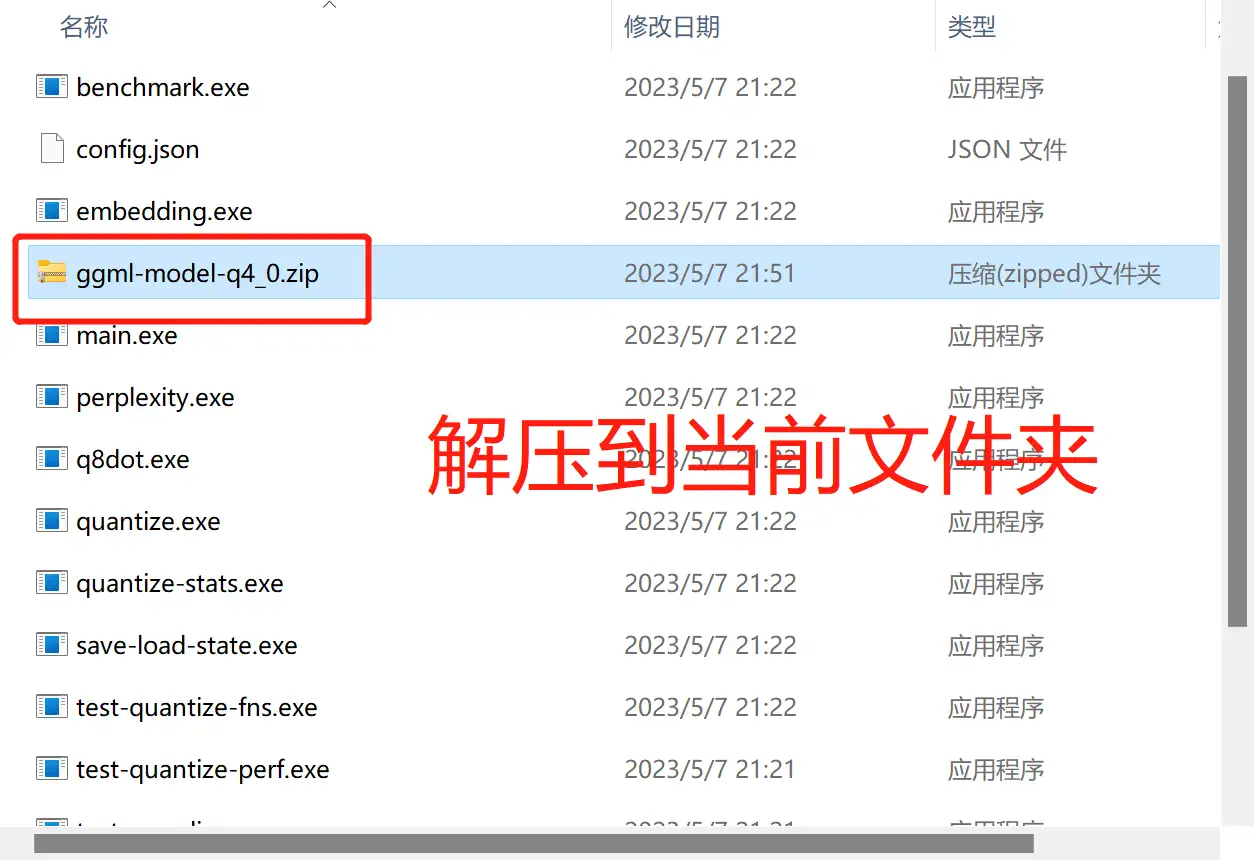
- 软件包内的是“7b”模型,如果想要“13b”模型,请下载这个:
跑13b模型需要至少8G的运行内存,但功能会比7b更强大。
7b是70亿个参数
13b是130亿个参数
- 试运行模型。如果没有“终端”两字,可以到WindowStore或者网上下载一个。
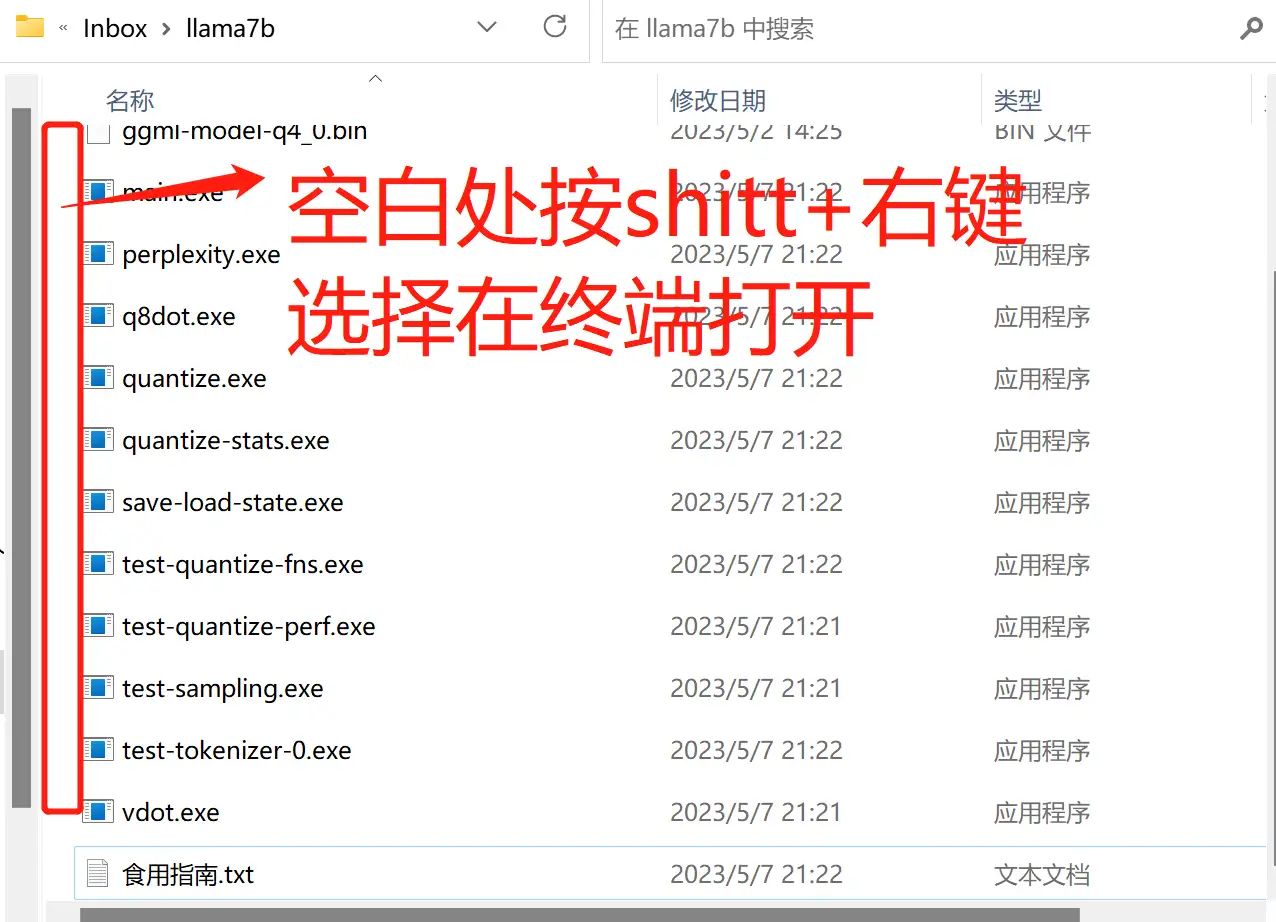
- 终端打开后的页面如下

- 输入“命令”到“终端”。命令格式如下:
无提示词:./main -m ggml-model-q4_0.bin --color -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3 -t (此处删掉括号填你的CPU线程数)
有提示词:./main -m ggml-model-q4_0.bin --color -f chat.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3 -t (此处删掉括号填你的CPU线程数)
- 命令示范(无提示词):


- 【重点】⭐命令示范(有提示词):(演示用的是7b模型)
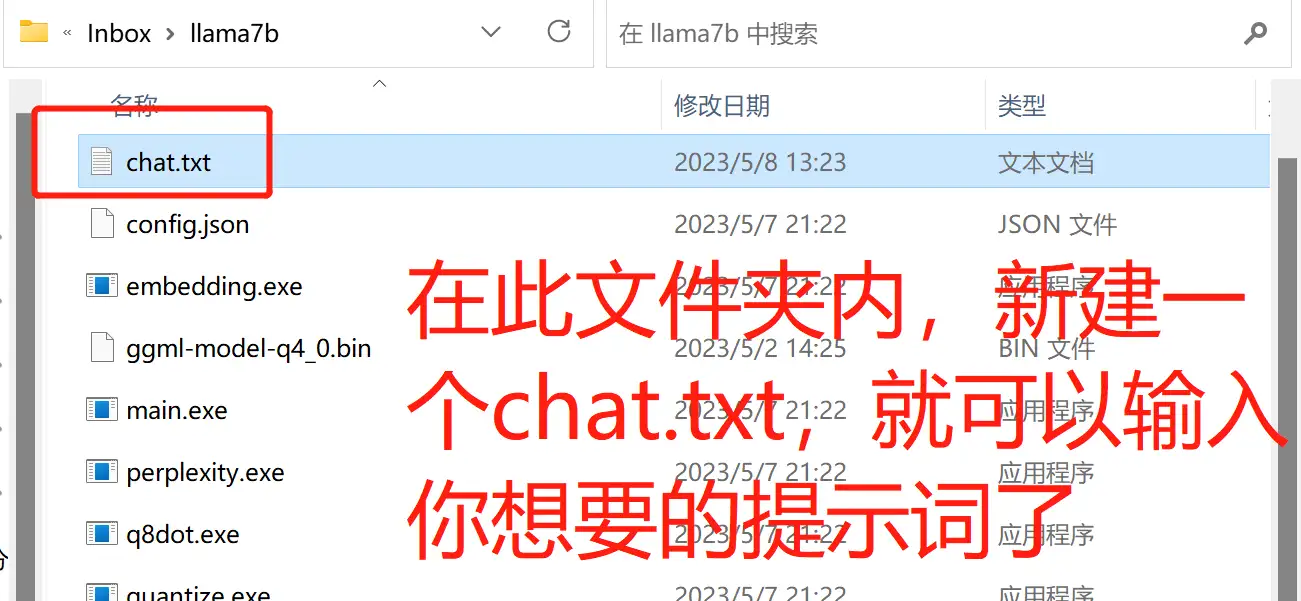
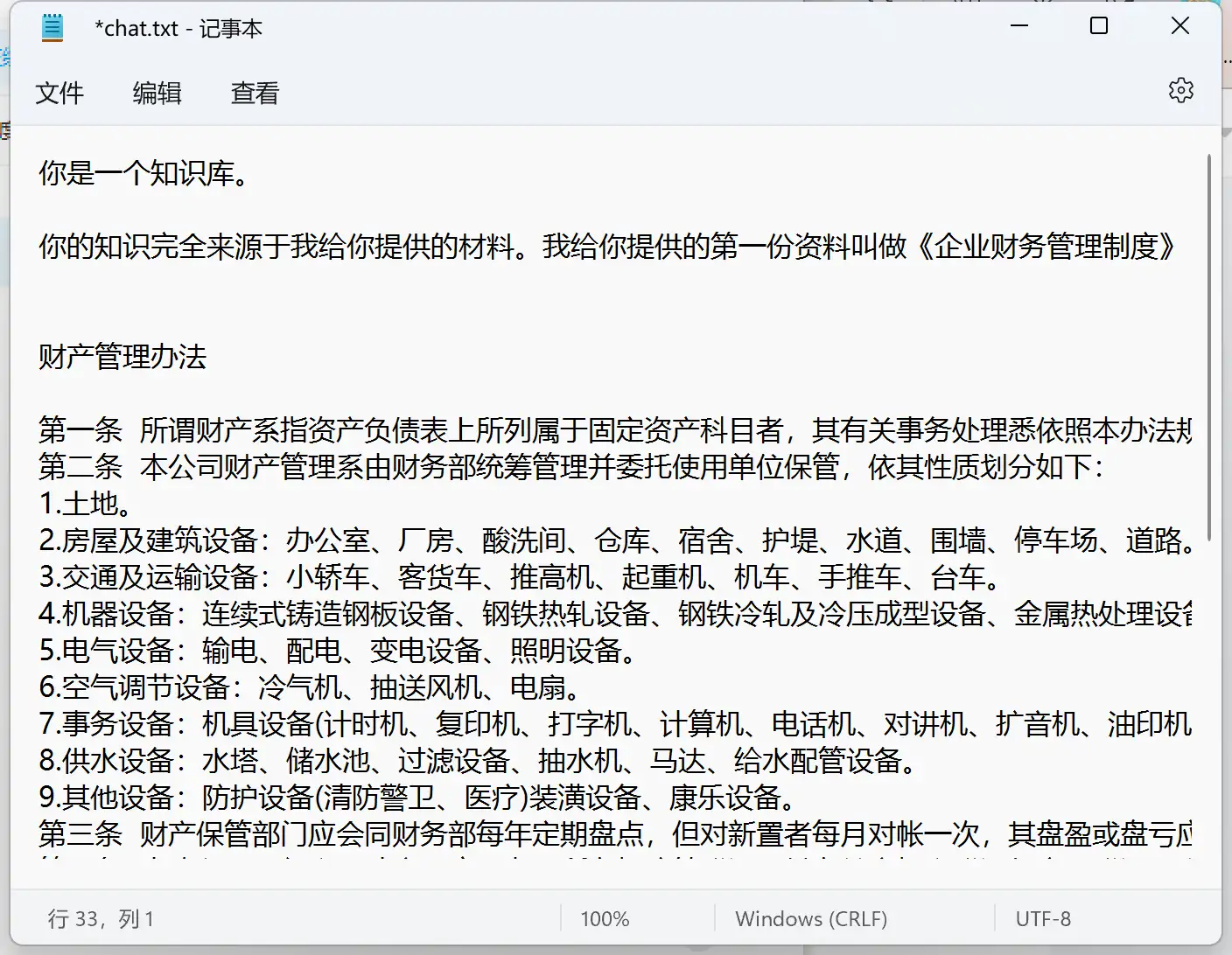
- 喂内容!例如我需要输入《财务管理办法》里的内容,则需要手动复制粘贴进“chat.txt”里面保存。
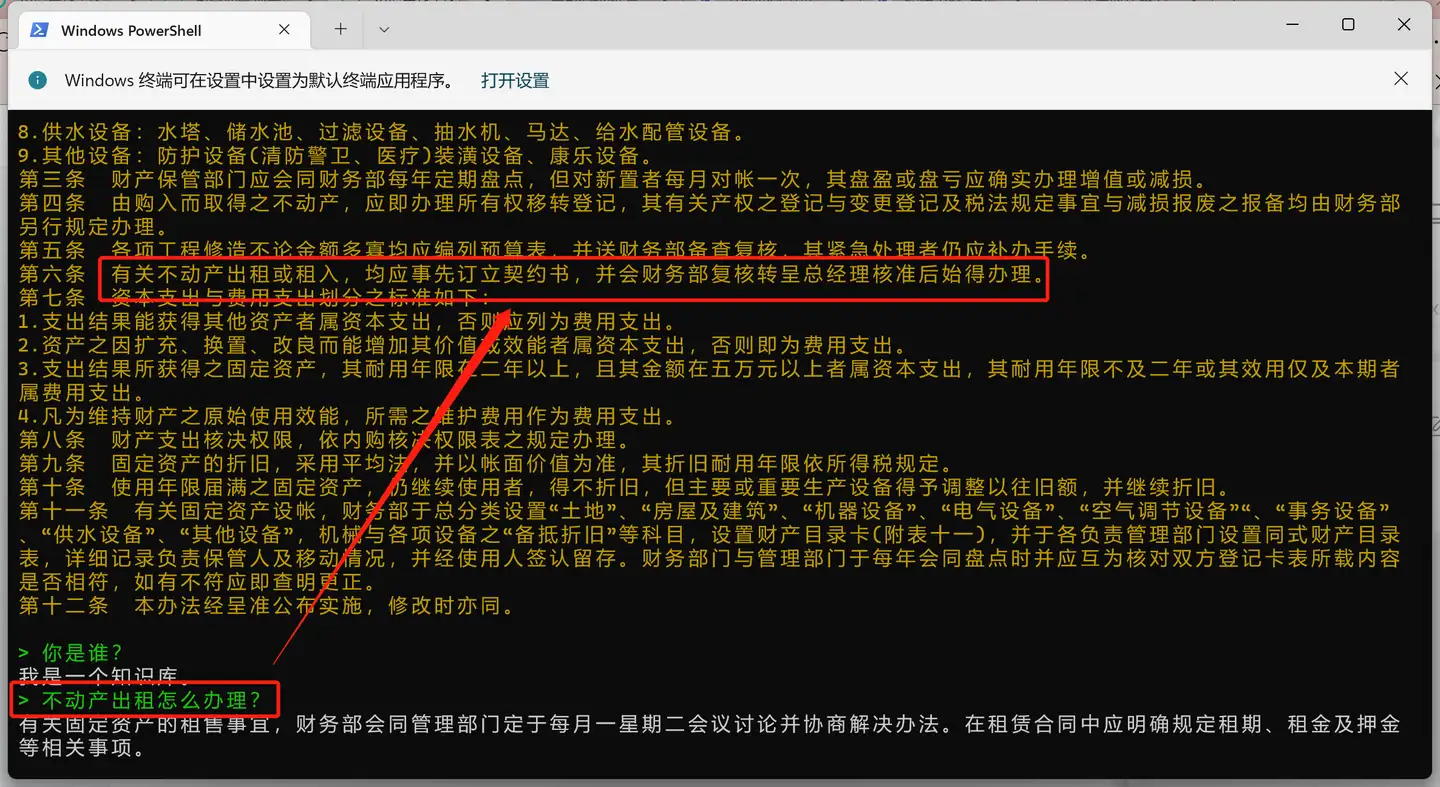
- 输入完毕后,让我们再来打开终端,输入“命令”来问问他。看起来还可以。
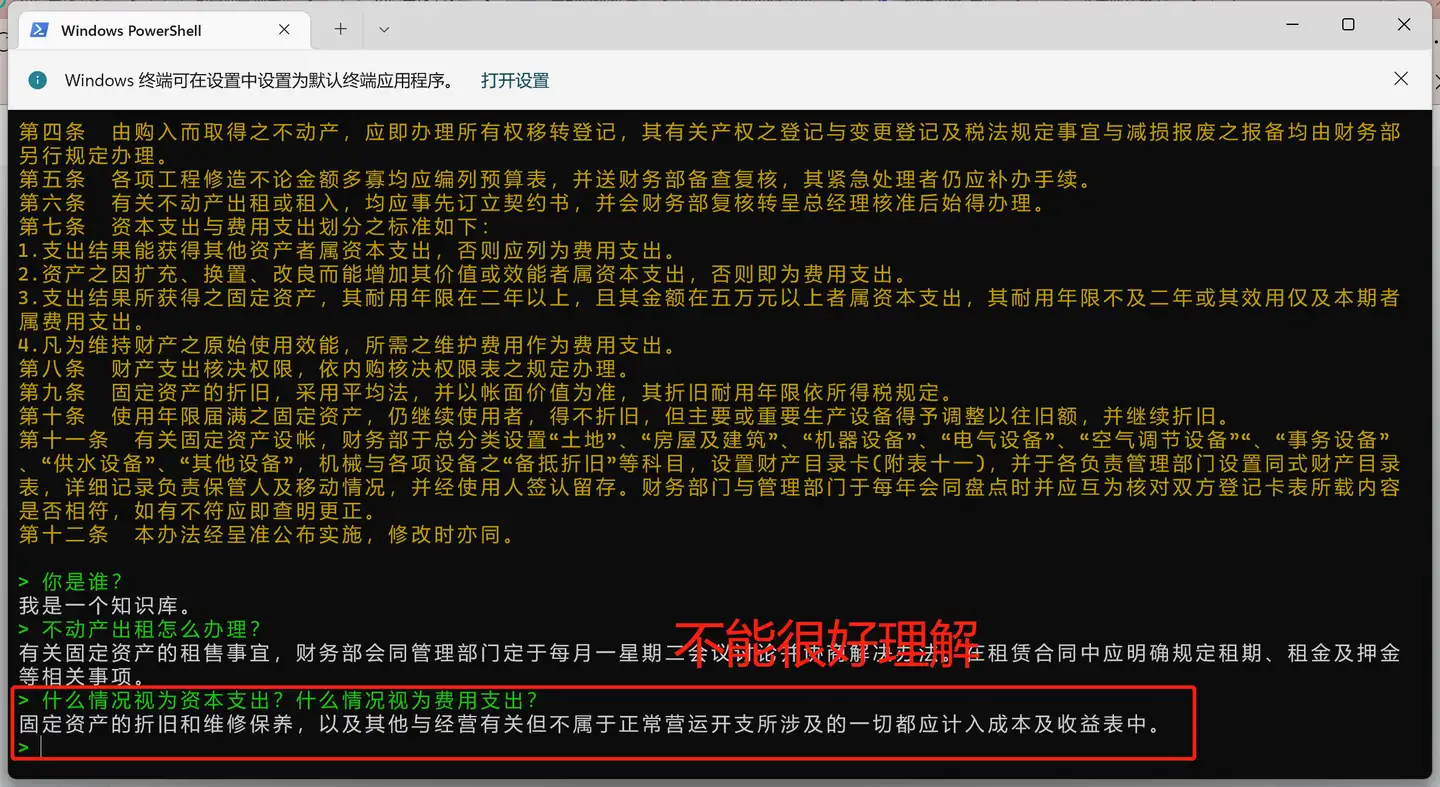
- 存在缺陷:答非所问,可能是模型参数太少的缘故。
- 缺陷二:初次进入,模型需要遍历一遍你的知识库,换而言之,知识库越大,读取时间越长。
- 缺陷三:毕竟是本地模型,理解能力有限,需要较高的prompt水平才能较好的驾驭模型
“命令”里可携带的参数
命令指的是
无提示词:./main -m ggml-model-q4_0.bin --color -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3 -t (此处删掉括号填你的CPU线程数)
有提示词:./main -m ggml-model-q4_0.bin --color -f chat.txt -ins -c 2048 --temp 0.2 -n 256 --repeat_penalty 1.3 -t (此处删掉括号填你的CPU线程数)
-ins 启动类ChatGPT对话交流的运行模式
-f 指定prompt模板,alpaca模型请加载prompts/alpaca.txt
-c 控制上下文的长度,值越大越能参考更长的对话历史(默认:512)
-n 控制回复生成的最大长度(默认:128)
-b 控制batch size(默认:8),可适当增加
-t 控制线程数量(默认:4),可适当增加
--repeat_penalty 控制生成回复中对重复文本的惩罚力度
--temp 温度系数,值越低回复的随机性越小,反之越大
--top_p, top_k 控制解码采样的相关参数
关于线程
- 怎么查看电脑内存:电脑内存怎么看?查看内存的详细图文教程
- 怎么查看电脑线程请点击:怎么查看电脑cpu核心数,线程数
往期文章回顾:
- AI自动帮你完成任务——小白也能实操的AgentGPT
欢迎交流!
参考文献:
- johnlui/chinese-alpaca-7b-and-13b-quantized at main
编辑于 2023-05-18 21:10・IP 属地安徽
这篇关于如何把GPT本地化,建立个人和小企业的知识库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!