本文主要是介绍设备能力指数cmk计算公式_【数据发布】2018年我国经济发展新动能指数比上年增长28.7%...,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

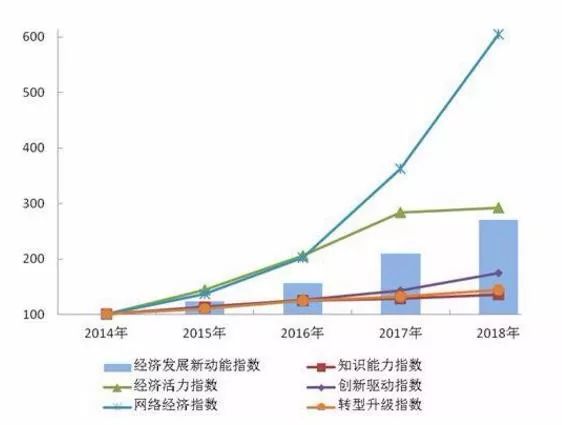
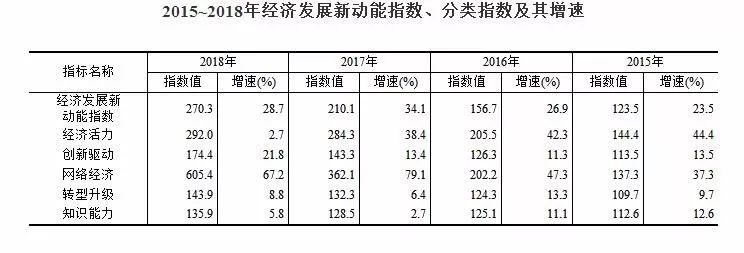
为动态监测我国经济发展新动能变动情况,国家统计局统计科学研究所在《新产业新业态新商业模式统计监测制度》和经济发展新动能统计指标体系的基础上,采用定基指数方法,测算了2015~2018年我国经济发展新动能指数。据测算,以2014年为100,2015~2018年我国经济发展新动能指数分别为123.5、156.7、210.1和270.3,分别比上年增长23.5%、26.9%、34.1%和28.7%,持续较快增长势头。2018年,五个分类指数均实现了不同程度的提高。
一、网络经济指数。2018年,网络经济指数为605.4,比上年增长67.2%,对总指数增长的贡献率为80.8%。
二、创新驱动指数。2018年,创新驱动指数为174.4,比上年增长21.8%,对总指数增长的贡献率为10.3%。
三、转型升级指数。2018年,转型升级指数为143.9,比上年增长8.8%,对总指数增长的贡献率为3.9%。
四、经济活力指数。2018年,经济活力指数为292.0,比上年增长2.7%,对总指数增长的贡献率为2.6%。
五、知识能力指数。2018年,知识能力指数为135.9,比上年增长5.8%,对总指数增长的贡献率为2.4%。
2015~2018年经济发展新动能指数及分类指数
附件:
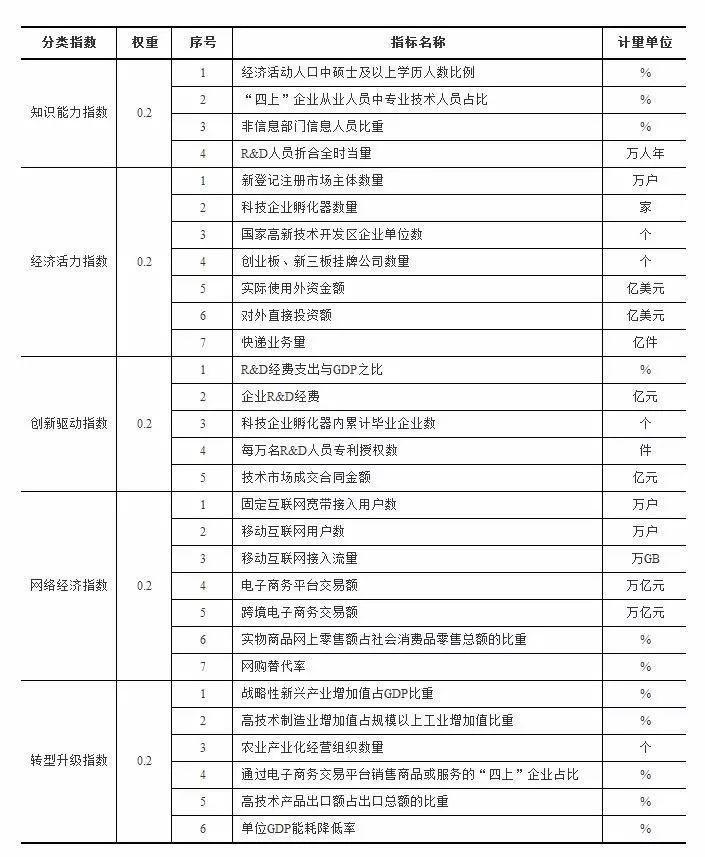
经济发展新动能指数统计指标体系及测算方法
一、经济发展新动能指数统计指标体系
经济发展新动能指数是指以新产业、新业态、新商业模式(简称“三新”)为主要内容的统计指标体系,具体如下:
二、经济发展新动能指数测算方法
经济发展新动能指数是利用“三新”调查基础数据,采用线性加权的综合评价方法构建而成的复合指数,用来反映经济新动能发展的趋势和进程。为更好反映新动能的长期变化趋势,动态监测新动能的聚集过程,经济发展新动能指数测算方法为定基法,即以2014年为基期,指数值表示报告期与2014年相比经济发展新动能的变化趋势。具体步骤如下:
1.基础指标的标准化
基础指标的标准化处理为:
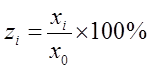
其中,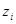 为
为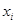 的指数,为报告期值,
的指数,为报告期值,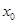 为基期值。
为基期值。
另外,当基础评价指标为逆指标时,通过倒数方式转化为正指标再采用上述公式计算指数。
2.分类指数的计算
经济发展新动能指数的分类指数计算公式为:

其中,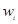 为
为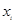 的权数,
的权数,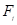 为第j个分类指数值,
为第j个分类指数值, 为第j个类别中第1个基础指标在整个指标体系中的序数,
为第j个类别中第1个基础指标在整个指标体系中的序数,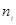 为第j个类别中最后1个基础指标在整个指标体系中的序数。
为第j个类别中最后1个基础指标在整个指标体系中的序数。
3.经济发展新动能指数的计算
计算公式为:
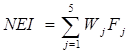
其中,NEI为经济发展新动能指数,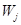 为分类指数
为分类指数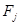 的权数。
的权数。
注:
[1]2018年指数根据当年初步统计数据测算。
[2]从2017年报告期开始,经济发展新动能指数测算改为定基发展指数方法,以2014年为基期,据此对之前发布的2015年和2016年经济发展新动能指数环比测算结果进行了修订。
[3]分类指数对总指数增长贡献率的计算公式为:


推荐阅读
◆ 【数据发布】2017年我国经济发展新动能指数比上年增长34.1%
这篇关于设备能力指数cmk计算公式_【数据发布】2018年我国经济发展新动能指数比上年增长28.7%...的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








