本文主要是介绍Progressive Transfer Learning 论文研读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
这个领域未解决的问题:
论文试图解决什么问题?
这个问题如何解决?
有哪些相关研究?
本文的主要贡献:
参数优化程序:
本方法的优越性解释:
STUDENT-TEACHER DISTILLATION METHOD
这个领域未解决的问题:
person ReID(重识别)近年来引起了学术界和工业界的极大兴趣。随着深度学习方法的发展和新出现的人重识别数据集,人重识别的性能最近得到了显着提升。但是,仍然存在几个未解决的问题:
- 从头开始训练一个特征提取模型需要大量的标注数据。然而,由于图像质量差和行人隐私问题,注释数据很难在人的 ReID 任务中获取。因此,使用现有数据集来帮助优化特征提取器在学术界中引起了极大的关注。
- 不同场景之间和同一场景内的显着差异使得人员重识别任务具有挑战性,一个显著的表现就是如果我们直接在目标数据集上应用预训练模型而不将其微调到目标场景中,通常会发生退化。
论文试图解决什么问题?
由于目标场景内部的显着变化,例如不同的相机视点、光照变化和遮挡,当使用 mini-batch 训练时,这些变化会导致每个 mini-batch 的分布与整个数据集的分布之间存在差距。在本文中,我们从使用小批量训练时数据集全局信息的聚合和利用的角度研究模型微调。
这个问题如何解决?
引入了一种称为批量相关卷积单元(BConv-Cell)的新型网络结构,它逐步将数据集的全局信息收集到latent state(隐藏层),并使用它来纠正提取的特征。在 BConv-Cells 的基础上,作者进一步提出了渐进式迁移学习 (PTL) 方法,通过联合优化 BConv-Cells 和预训练的 ReID 模型来促进模型微调过程。
有哪些相关研究?
- 最近提出的大多数工作都专注于减轻不同数据集之间变化的影响。这些工作中的大多数都专注于通过使用基于生成对抗网络 (GAN) 的模型将目标域和源域的图像风格转移到相同的位置。然而,不完美的风格转移模型会带来噪音,并可能改变整个数据集的数据分布。同时,生成的图像中的人物 ID 不能保证与真实图像中的相同。
- 大多数最先进的个人重识别任务深度学习方法都使用了现成的网络,如 DenseNet和 ResNet ,作为骨干网络。然而深度 CNN 难以用有限的训练数据进行初始化和优化。因此,模型微调被广泛用于缓解人员 ReID 任务中带标签的训练数据的短缺,使得研究如何减轻内部变化的影响更加关键。例如,在 ReID 任务中使用的大多数现成模型都是在相对较大的数据集(如 ImageNet [6])上进行预训练的,然后微调到目标数据集。
本文的主要贡献:
- 我们提出了一种新的网络结构,称为批量相关卷积单元(BConv-Cell)及其变体(BConv-Cell-v2)。在小批量训练中,BConv-Cells 可以逐步聚合数据集的全局信息,然后在下一批中使用它来优化模型。
- 基于 BConv-Cells及其变体(BConv-Cell-v2),我们提出了渐进式迁移学习 PTL 以及PTL-V2方法,通过集成 BConv-Cells 将预训练模型微调到目标场景中。 3实验结果表明,使用我们的提议的微调模型可以在四个有说服力的行人 ReID 数据集上实现最先进的性能。 4在这项工作中,我们将我们提出的应用场景从行人重识别任务扩展到一般的图像分类任务。几个图像分类基准数据集的实验结果表明,我们的提议可以显著提高主干模型的性能。
The Batch-related Convolutional Cell
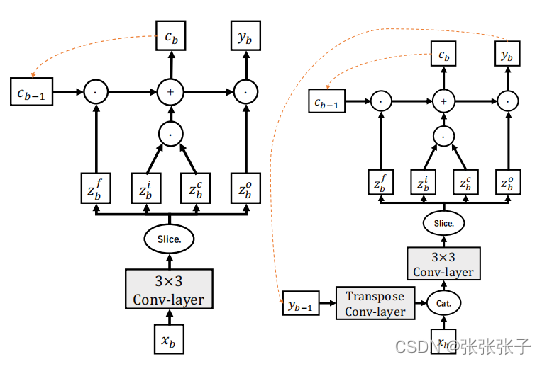
![]()
![]()
BConv-Cell 的关键方程如下所示:
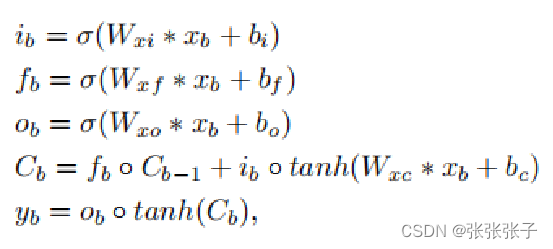
![]()
本文用几种不同的骨干网络结构测试了 PTL 方法,包括 DenseNets 和 ResNets。我们使用 DenseNet-161 作为骨干网络来描述 PTL 网络的构建。
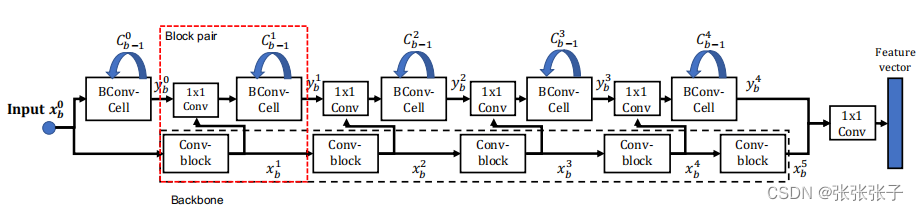
DenseNet-161 由五个 Conv 块组成。使用四个 BConv-Cell 与前四个 Conv-block 配对。如图左侧在网络的顶部,使用一个 BConv-Cell 来捕获输入图像的低级特征。将最后一个 BConv-Cell 的输出与最后一个 Conv-block 的输出连接起来,然后馈入一个 1x1 Convlayer 以获得特征向量。在训练过程中,特征向量被输入到一个包含三个全连接层的分类器中。为简单起见,图中没有显示分类器。在评估过程中,作者直接使用特征向量进行图像检索。
本文提出的 PTL-v2 是PTL的一种变体,只替换了其中的 BConv-Cell为BConv-Cell-v2 ,在的每个 BConv-Cell-v2 块中,我们首先恢复先前小批量的历史输入特征,然后将其与当前小批量连接。我们使用先前小批量的聚合信息来优化新输入的特征,从而减轻数据生成的偏差的影响。实验结果表明,PTL-v2 可以在多个图像分类基准中优于所有基线,同时在类别较少的图像分类基准中优于 PTL 网络。
参数优化程序:
本方案利用BConv-Cells 与骨干网络进行参数优化,这对优化方法没有限制,因此仍然可以使用常见的SGD和SGD-M优化器,并且本文的PTL方法可以弥补SGD-M 优化器的两个缺点:
- 历史梯度通过使用人为预定义的权重大致聚合为线性总和,这使其不灵活且未优化。(这里我不太理解,需要再查阅学习)
- 每批后的损失仅由当前输入的批决定,具有很强的偏差,导致训练过程中的性能波动 PTL 方法,通过使用可学习的权重递归地计算组合函数的梯度来代替历史梯度聚合。不仅如此,当前批次的样本偏差可以通过使用学习到的潜在状态 Cb 携带的历史知识来减轻。。
SGD和带momentum的SGD算法这个解释感觉很好
本方法的优越性解释:
许多基于深度学习的方法的训练和测试数据集通常是从相同的数据分布生成的,经过训练的模型可以直接应用于测试数据集,其性能与训练数据集相当。尽管这种方法在许多公共数据集中被经验证明是非常成功的,但它在现实世界的应用中被认为是有缺陷的。 在实际应用中,我们很少知道真正的底层模型,我们不能保证未知的测试数据与训练数据具有相同的分布。此外,在实际应用中,显着的数据生成偏差会导致不同的训练和测试数据集之间存在巨大差异。因此,在这样的训练数据集中训练的模型将陷入特征的统计相关性并导致性能不稳定,从而产生较低的训练损失。为了缓解这个问题,我们的提议逐步聚合训练数据集的全局信息,然后将其应用于减轻训练期间数据生成偏差的影响。
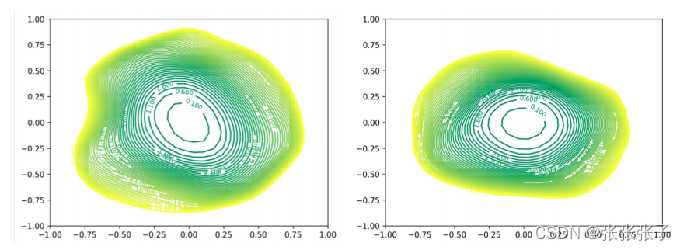
实验表明,无论是在行人ReID任务中,还是在一般的图像分类任务中,我们的建议都能显著提高基类模型的性能。为了验证想法,作者使用可视化工具在 CIFAR-100 数据集上进一步可视化了具有/不具有 PTL-v2 的 DenseNet-100 的损失表面。我们可以注意到 DenseNet-100+PTL-v2 的损失面比 DenseNet-100 宽。损失表面越大,模型的泛化能力越好。因此,我们可以得出一个明确的结论,即 PTL 在使用数据集的全局信息的微调过程中有助于提高模型的性能。
STUDENT-TEACHER DISTILLATION METHOD
与骨干网络相比,PTL网络的参数数量不可避免地增长,为了进行公平比较我们引入了一种改进的STUDENT-TEACHER DISTILLATION,称为师生蒸馏 (STD) 方法, 在面对海量用户的部署阶段,对延时和计算资源有更高的要求,这是复杂模型所不能完成的。然而当复杂模型训练完成时,我们可以额外进行一种叫“蒸馏”的训练,将知识从复杂模型转移到更适合部署的小模型上。 (这里我还不是很明白)
不懂STUDENT-TEACHER DISTILLATION可以先看看这个链接的解释
知识蒸馏 - Teacher与Student爱恨情仇
后续实验部分还没有看完,后续再看
这篇关于Progressive Transfer Learning 论文研读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[论文笔记]LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale](https://img-blog.csdnimg.cn/img_convert/172ed0ed26123345e1773ba0e0505cb3.png)


