本文主要是介绍【ZAN】可视化学习笔记:R_graphics_反映变量间关系——如何“看”出信息?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【ZAN】可视化学习笔记:R_graphics_反映数据分布——如何“看”出信息?_江屿之的博客-CSDN博客拿到一堆数据,统计人的第一想法当然是研究其分布了!本人梳理了R自带的画图包{graphics}中,可以帮助我们实现反映数据分布需求的函数,结合具体数据,让其从粗糙到精致,从默认到个性化。使可视化在数据挖掘、数据分析发挥其作用!https://blog.csdn.net/pikapikaka/article/details/127000863?spm=1001.2014.3001.5501
接上篇,我们整理了用R的基本画图包{graphics}来实现数据可视化中的功能之一,即“探究数据分布”的技术与方法,这次我们来整理和实现另一功能——反映变量间关系。
ps:虽说是功能驱动,但大前提是{graphics}包下,所以某些我知道可以在R中实现的却超出了基本包的图就不介绍了。比如,"热图"很好,但graphics画不出来...因此就不在这篇笔记里写了qwq
目录
【说说】相关和独立,我们是不是都该重视?
【分类+分类】二维列联表
【列联表】Cross Tabulation
【数值+数值】散点图、散点图矩阵、相关系数矩阵
【散点图】scatter plot
【散点图矩阵】scatter plot matrix
【相关系数矩阵】correlation matrix
【分类+数值】分类箱形图/散点图/直方图...
分类散点图
分类直方图
分类箱形图
【最后】为什么我要单独整整理一篇graphics包的可视化内容?
【说说】相关和独立,我们是不是都该重视?
仅仅是个人的感觉!我们在关注一对或者一组变量时,似乎总是期待着找到期间的相关性,非常看重具有相关性的变量,反过来说,那些似乎“毫无关联”的变量就像选择性忽视的灰尘一样被我们请扫到一边,相关才是那尘土下发光的东西。那么独立真的没用吗?我这么想...也就只能想到这儿了。(为相关性不强的变量组合抱不平。。。)
【分类+分类】二维列联表、组合(堆叠)条形图
我们选择英国父亲与儿子职业地位的数据集,origin代表着父亲的职业地位1-8,destination代表儿子的职业地位1-8,很明显除了观测两代人的职业地位分布之外我们可以探究父子代的地位变化与关系:“龙生龙凤生凤”还是“寒门出贵子”?


图1-occupationalStatus数据概览
首先我们复习一下上篇内容,由于职业等级是分类但有序的变量,所以我们采用柱状图,又因为想要对比两代在分布上的差异,组合柱状图差了点儿意思,于是我们修改颜色的透明度,做了一个叠加的柱状图。
#两代分布-叠加柱状图
d<-as.data.frame(occupationalStatus) #英国男性父子职业联系
f<-aggregate(d$Freq,by=list(d$origin),FUN=sum)
sum(f$x);f#统计父代分布
s<-aggregate(d$Freq,by=list(d$destination),FUN=sum)
sum(s$x);s#子代分布
png(filename = "occup_bars_r.png",width = 600,height = 480,units = "px",bg = "transparent",res = 70)#创建画布
par(oma=c(0,0,4,0))#我们画一个绝对值的、一个百分比的
col1=rainbow(n=1,start = 8/10,end = 9/10,alpha = 0.3)#rainbow可以调节透明度
col2=rainbow(n=1,start = 3/10,end = 4/10,alpha = 0.3)
barplot(f$x,border = 'transparent',col = col1,names.arg = c(1:8),ylim = c(0,1500),xlab='the occupation status',ylab = 'numbers')
par(new=T)#这样才可以叠加图片
barplot(s$x,border = 'transparent',col = col2,ylim = c(0,1500),xaxt='n')
legend('topright',legend=c('father','son'),fill=c(col1,col2))#加图例
mtext('the frequency of the occupation status from two generations',cex=1.5,col='purple',side=3,line=3)#标题
dev.off() 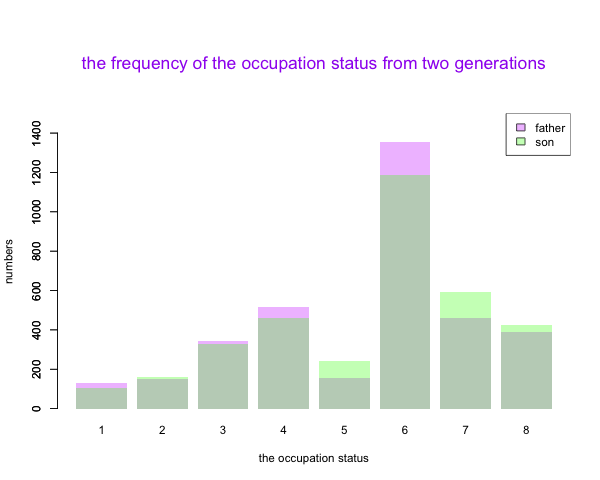
结果1-两代人的职业地位频数统计-叠加柱状图
如结果1所示,图中2、5、6、7、8柱子的子代人数要多于父代(5、7、8尤其),1、3、4、6父代多于子代(6尤其),我们可以推测:子代的职业地位分布有向更加“左偏”的趋势,即集中在中下职业地位的人越来越多了,如果要论证这个结论,可以运用到非参数统计中的秩和检验。先不展开,我们来回答另外一个问题——父子代之间存在什么样的关系?
【列联表】Cross Tabulation
很多人会有疑问,不是讲可视化吗?怎么还有表啊?
因为可视化不仅仅是图噢!是图和表!
其实在上篇笔记中我们就有使用过交叉表,xtabs函数,通过prop.table()我们可以将其显示成百分比的形式,便于我们观察。
#二维列联表
#table、xtabs
d<-as.data.frame(occupationalStatus) #英国男性父子职业联系
ct<-xtabs(Freq~destination+origin,#origin(父亲的职业地位);destination(儿子的职业地位)data = d)#xtabs实现二维列联表:+号前的是行,+号后是列print(ct)
print(ct)
pcol<-prop.table(ct,margin = 2)#列百分比:父代阶层的子代流向
print(pcol*100,digit=2)#位数有点多就设定digit参数
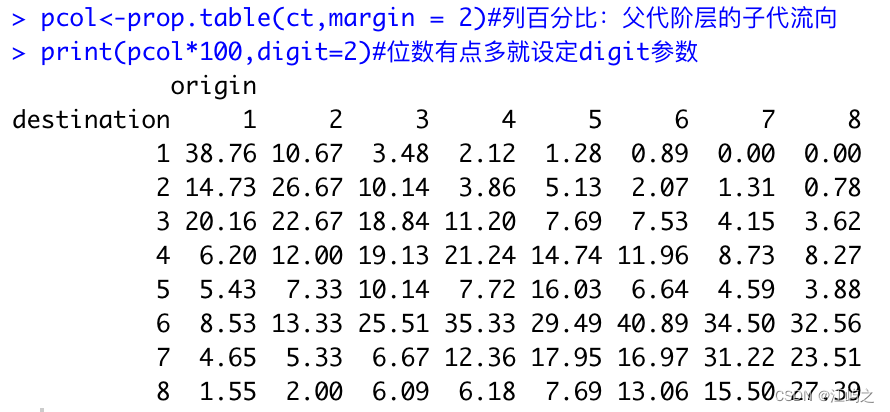
结果2-二维频数、百分数列联表
由于是列求百分比(每一列之和为100%)结果1所示,父代1至8职业阶层分别有38.76%、26.67%、18.84%、21.24%、16.03%、40.89%、31.22%、27.39%保持了原始职业等级,那么子代等级的父代组成呢?修改下margin函数即可。
prow<-prop.table(ct,margin = 1)#行百分比:子代阶级的父代组成
print(prow*100,digit=2)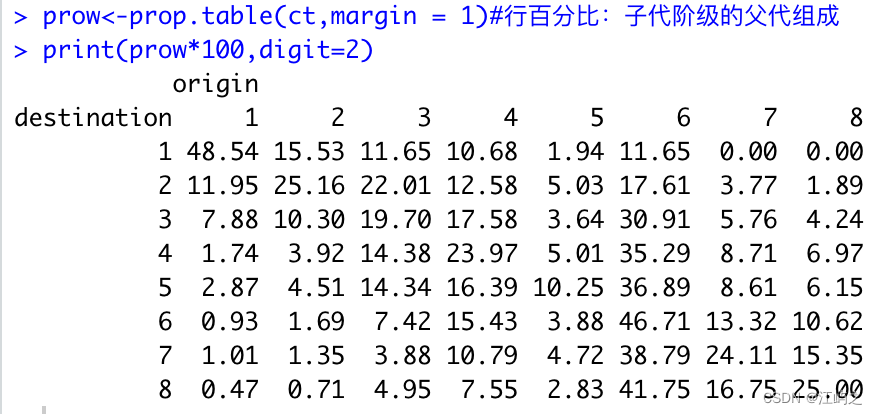
图2-子代阶级的父代组成
子代阶层1-8的父亲最多的分别来自1、2、6、6、6、6、6、6,我们可以观察到,父亲代阶层6(本身数量就多)的子代在除阶层1、2外的职业等级均占据最多。反过来说,我们可以推测,1、2职业阶层确实存在一些依托父代资源的壁垒。
【数值+数值】散点图、散点图矩阵、相关系数矩阵
【散点图】scatter plot
数值加数值的数据组合并不少见,就像人们似乎会不由自主地研究身高和体重的关系,我们都知道“回归之父”高尔顿是在研究父子代的身高(两个数值变量)时发现了这种现象,至此今日,回归方法被广泛地引用。但在回归之前,我们通常都要初步观察下——这两个变量到底有没有哪怕一丁点儿关系,如果有,是正相关还是负相关呢?于是,散点图就起到了至关重要的作用。
#散点图、气泡图
z=Puromycin#两种细胞中辅因子浓度对酶促反应的影响
xl=range(z$conc)
yl=range(z$rate)#获取两个变量的极值向量
png(filename = "xibao_scatter1_r.png",width = 480,height = 480,units = "px",bg = "transparent",res = 64)#创建画布
plot(z$conc,z$rate,pch = 2,cex=0.7,col='blue',main = 'scatter plot',xlim = xl,ylim = yl)#设置点的形状、颜色、标题、坐标轴
dev.off()#关闭画布我们采用了r自带数据集Puromycin(两种细胞中辅因子浓度对酶促反应的影响),虽说涉及到两种细胞,但混合在一起看也有一定的意义——浓度与酶促反应的关系。如结果3所示,我们可以看见随着conc(substrate concentration,基底浓度)的升高,rate(instantaneous reaction rates,瞬时反应速度)也随之升高,只是随着培养皿的浓度越高,这种对酶促反应带来的速率升高影响也不断减少。
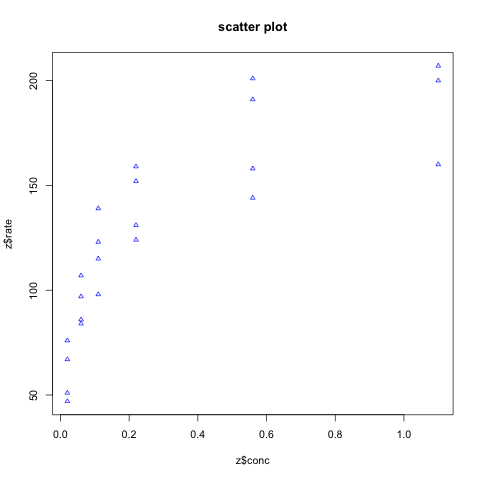
结果3-基底浓度和细胞酶促反应速率的散点图
【散点图矩阵】scatter plot matrix
这是一个只有两个数值变量的数据集,如果存在多个数值变量,我们如何迅速筛选出存在相关的变量组合呢? 自带数据集mtcars反映了32辆汽车在11个指标上的数据表现,其中7个指标为数值型。
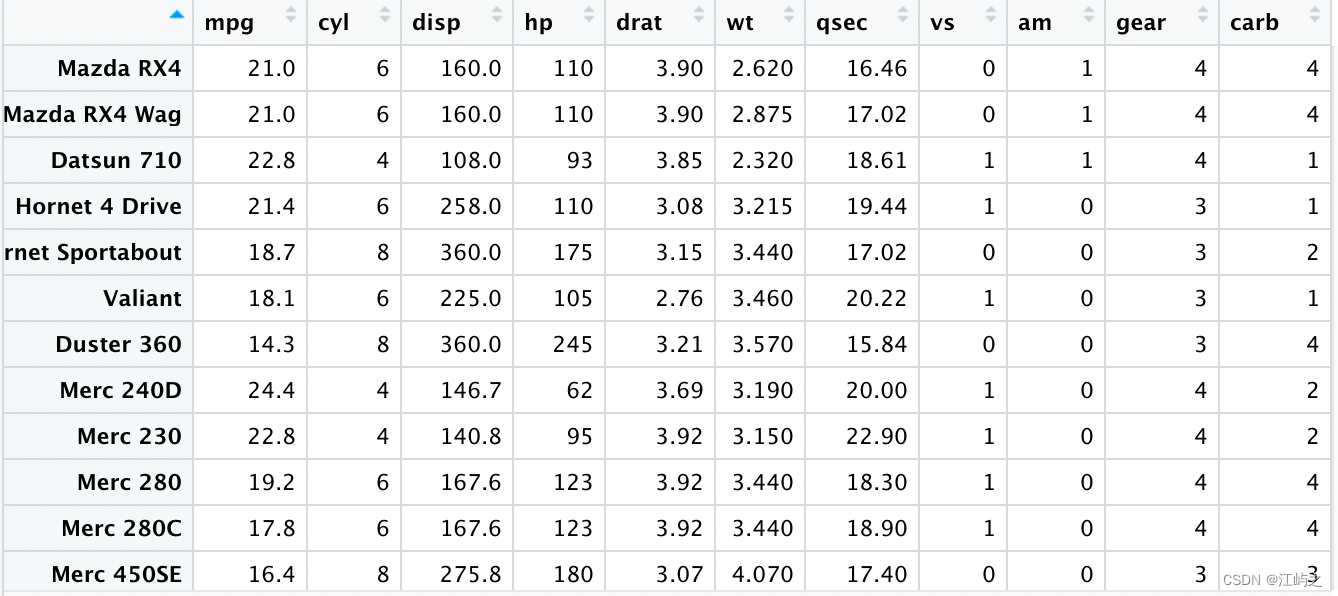
图3-数据集mtcars的概览
#矩阵散点图(多变量情况)pairs
car<-mtcars #32辆汽车在11个指标上的数据
png(filename = "xibao_scatter3_r.png",width = 480,height = 480,units = "px",bg = "transparent",res = 64)
pairs(~mpg+disp+hp+drat+wt+qsec,data=car,#pairs函数即可main='Scatterplot Matrix',pch=20,cex=0.6)
dev.off()
我们采用graphics里的pairs()函数,在短短几行代码中就实现了一些列的散点图(便于查看组成了散点图矩阵),如结果4所示,共15张散点图(虽然显示30张,但对角线左右是对称的,看一边即可),除红色框显示不出明显的相关性之外,其他变量均不同程度的表现出一定的相关性。qesc(1/4 mile time)似乎独立性相对较强(与之无关的变量数量相对多)
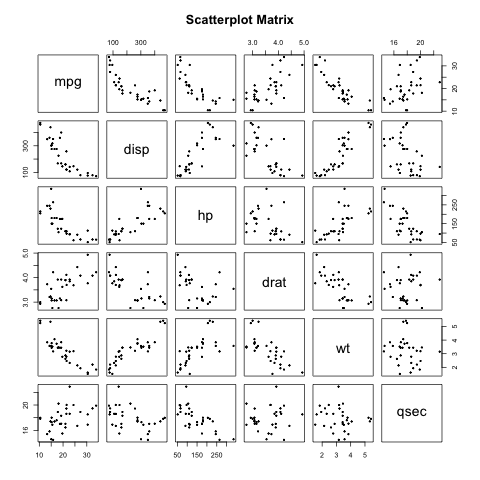
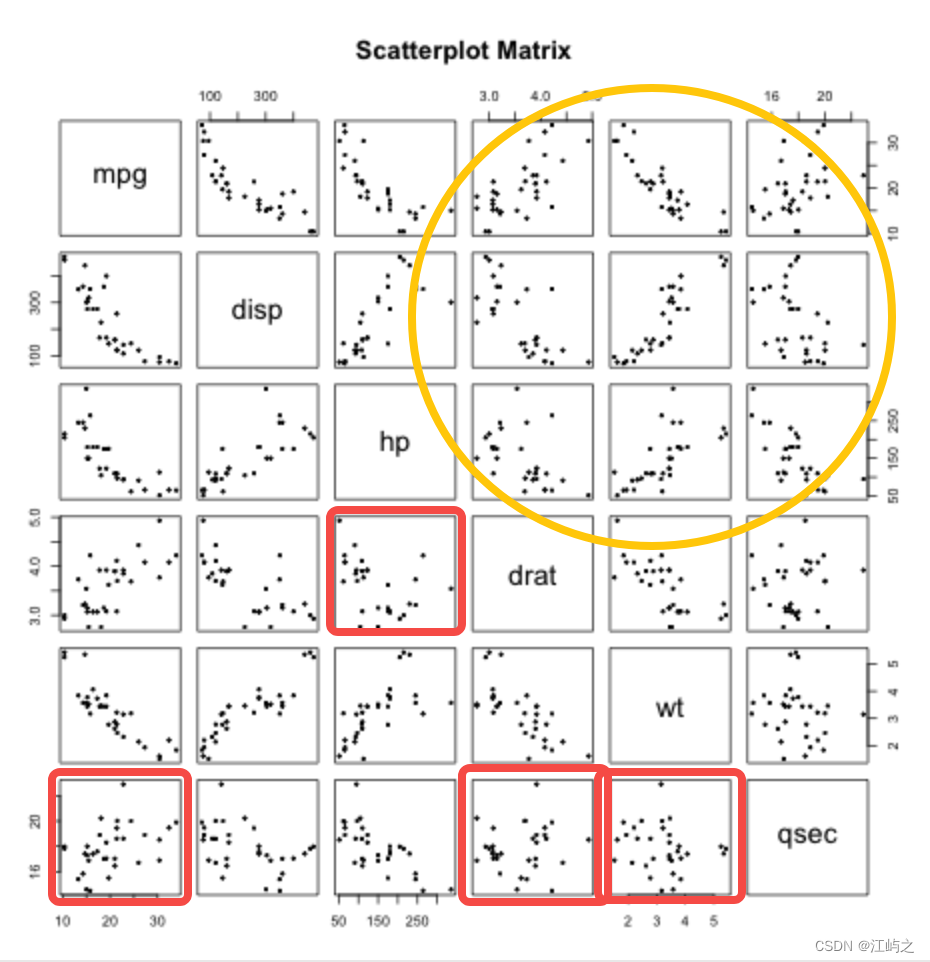
结果4-散点图矩阵及观察标记
【相关系数矩阵】correlation matrix
当然,眼睛其实是会“骗人”的,在画出散点图矩阵后,也可以相关系数矩阵量化变量间的关系,从而来验证我们从图中得到的猜想。
#相关系数矩阵
cars<-mtcars
cmx<-cor(cars[,1:7])#仅仅截取前7列
print(cmx,digit=2)#保留两位小数 

结果5-相关系数矩阵及标记
如结果5所示,对比散点图,我们发现从散点图信息猜测的变量的相关系数确实趋近于0,drat与qsec尤其,相关系数仅有0.091。
【分类+数值】分类箱形图/散点图/直方图...
个人认为,分类和数值变量的关系探究是最普遍的,性别差异带来的种种研究、地域差异带来的种种...在可视化上,我们需要尽可能展现不同类的数据分布、趋势,来让我们大致判断类与类之间会不会存在差异,反过来说,不同数值会不会导致分类的变化(俗话说量变引起质变)。在可视化方法中,我们可以引入点、线的颜色、形状属性来区分不同类目。这部分比较简洁,代码+结果+简要分析与解释。
分类散点图
承接上面的散点图,我们引入分类变量,可以进一步观察对照组和实验组的差异——实验到底有没有用?(至少看起来?)
z=Puromycin#两种细胞中辅因子浓度对酶促反应的影响
z_1<-subset(z,z$state=='treated')#treated子集
z_2<-subset(z,z$state!='treated')#untreated子集
png(filename = "xibao_scatter2_r.png",width = 480,height = 480,units = "px",bg = "transparent",res = 64)#创建画布
par(new=TRUE)
plot(z_1$conc,z_1$rate,lty=5,pch = 2,cex=0.7,col='blue',main = 'scatter plot by group',xlim = xl,ylim = yl)
plot(z_2$conc,z_2$rate,lty=5,pch = 4,cex=0.7,col='red',xlab='',ylab='',xlim = xl,ylim = yl)
legend('topleft',legend=c('treated','untreated'),pch = c(2,4),col = c('blue','red'))
dev.off()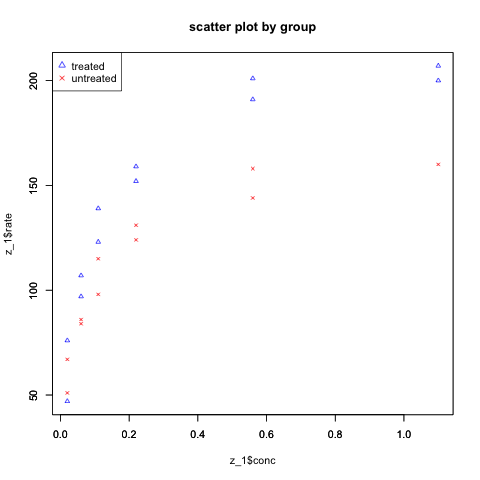
结果6-细胞酶促反应分组散点图
散点图(结果4)的基础上加了分类变量属性(颜色+标记)后,我们清楚地看到(如结果6所示),处理过的细胞相比没处理过的细胞,在基底浓度增加的情况下,有了更快的酶促反应,上界也有了显著的提升。
分类直方图
与叠加柱状图相似,我们只需要控制相同的bin划分、纵坐标尺度,即可得到不同类型的数值指标分布。
#分类直方图
air<-airquality#纽约1973年5-9月每日空气质量
f<-aggregate(d$Freq,by=list(d$origin),FUN=sum)
range(air$Wind)
png(filename = "air_hist+clu_r.png",width = 600,height = 480,units = "px",bg = "transparent",res = 70)#创建画布
par(oma=c(0,0,4,0))#我们画一个绝对值的、一个百分比的
col1=rainbow(n=1,start = 8/10,end = 9/10,alpha = 0.3)#rainbow可以调节透明度
col2=rainbow(n=1,start = 3/10,end = 4/10,alpha = 0.3)
breakair=seq(0,22,by=2)
hist(subset(air,air$Month==5)$Wind,breaks = breakair,main = '',ylab='days',col = col1,labels = T,ylim = c(0,15))
par(new=T)#这样才可以叠加图片
hist(subset(air,air$Month==9)$Wind,breaks = breakair,main='',ylab = '',col = col2,labels = T,xaxt='n',yaxt='n',ylim = c(0,15))
legend('topright',legend=c('May','September'),fill=c(col1,col2))#加图例
mtext('the histograms of the wind speed on May and September',cex=1.5,col='purple',side=3,line=3)#标题
dev.off()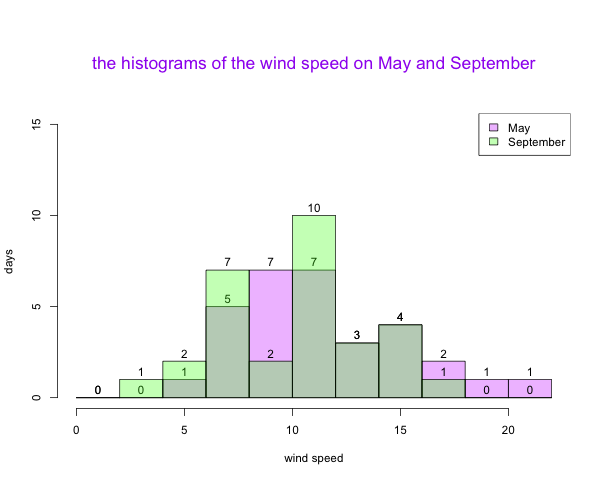
结果7-分类直方图5、9月风速分布的差异
我们对比5月和9月的风速分布(如结果7所示),发现五月的风速似乎整体略高于九月。
分类箱形图
我们发现,结果7虽然能够细致地显示7、9月份的分布,但由于叠加颜色(月份)不易过多,所以在这种分类明细有5种时,分类直方图并不是最佳的选择,于是我们引入分类箱形图。
#分类箱线图
png(filename = "air_box+clu_r.png",width = 700,height = 480,units = "px",bg = "transparent",res = 70)#创建画布,res为分辨率
par(oma=c(0,0,3,0))
boxplot(Wind~Month,data=air,#构建公式即可,~右边为分类变量,左边为数值型变量col=rainbow(5,start = 4/10,end=1/10,alpha = 0.3))
mtext('batches of boxplots',side=3,line=0,cex=1.5,col='purple',outer = T)
dev.off()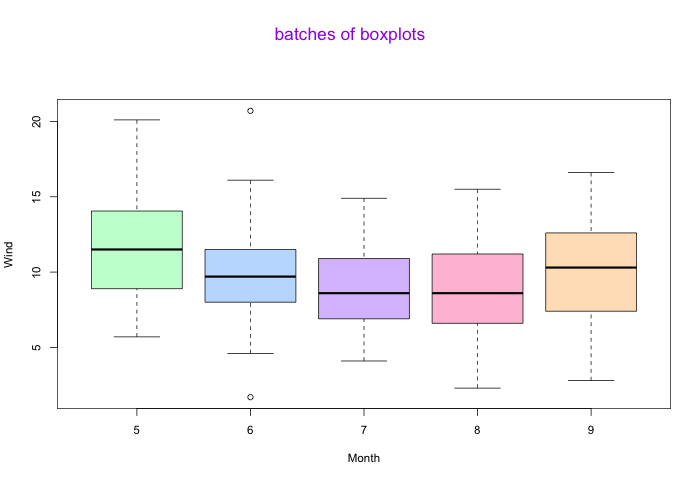
结果8-不同月份的风速分布差异
结果8使得不同月份风俗分布的差异一目了然,整体而言,五月份的风速确实是略高于9月份的。
【最后】为什么我要单独整整理一篇graphics包的可视化内容?
到这儿,关于graphics的可视化部分其实就差不多了。
我什么不把大名鼎鼎,公认好用的ggplot2加进来?因为,这是一个工具为前提,目的为导向的学习笔记,如果把目的作为大前提,那么什么好用的我就会写上来(必然包括ggplot2),只不过目前好用的软件、包、函数太多太多了,这可是项巨大的工程。
另外,也许是我想验证——R真是一个画图nb的工具吗?反正我之前一直是瞧不上的哈哈哈(所以一直去玩python了),甚至到我开始写这篇笔记前,我都并不觉得R有多么厉害。真真正正把每一种画图函数深挖后才发现,原来可精细化地程度在大多数场景下完全够用了!
所以呀,先我为我之前的无知向R说声抱歉。下一篇可视化笔记应该是目的导向,ggplot2做得再漂亮的柱状图应该不会被我放进去,因为graphics已经能满足了,但是像脸图、热图、气泡图、三维柱状图(这个可能得用python)graphic不能实现的,我就会添加进去。
2022年9月30日——9月的最后一天
在图书馆发完最后一个字准备回宿舍的我
这篇关于【ZAN】可视化学习笔记:R_graphics_反映变量间关系——如何“看”出信息?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







