本文主要是介绍Filebeat、metricbeat、kafka,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
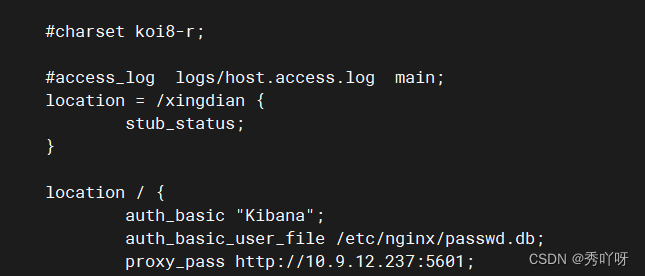
kibana机子上安装filebrat(因为有nginx)
上传filebrat包
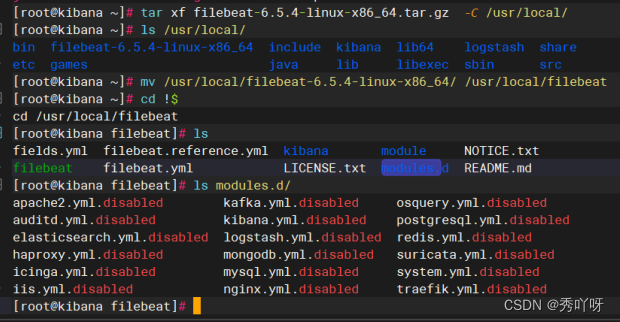
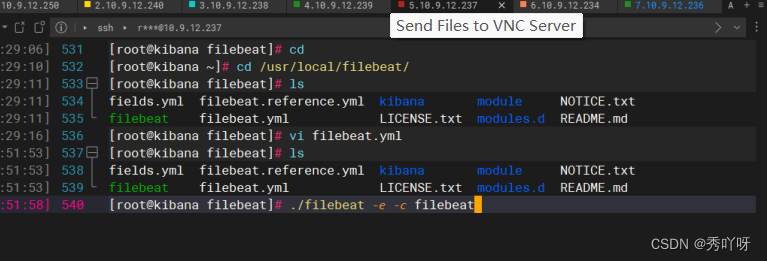
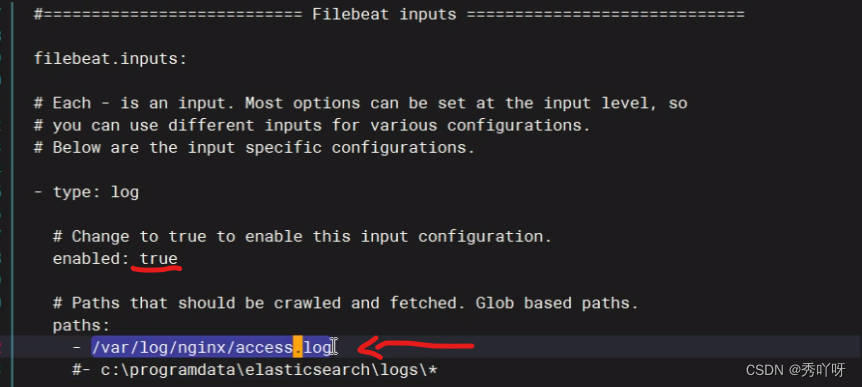
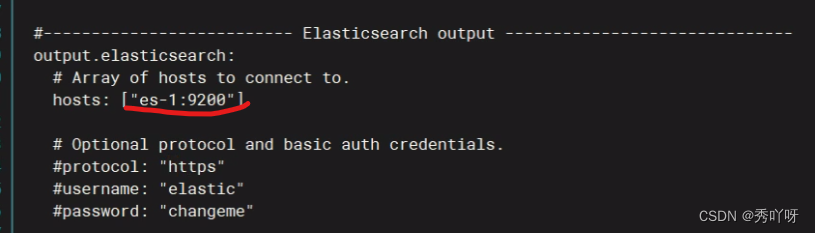

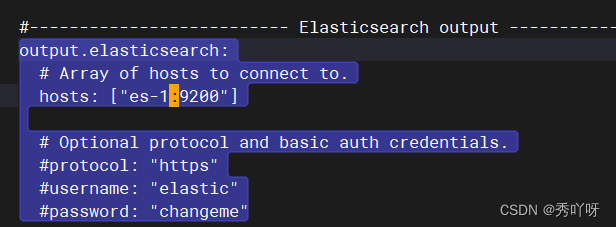
在es概览查看
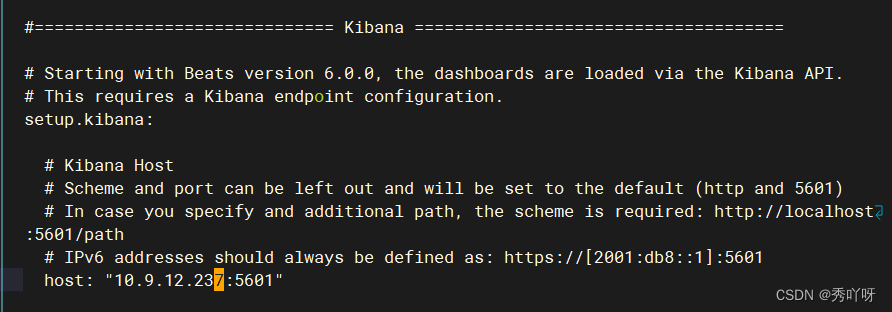
上传metricbeat

![]()


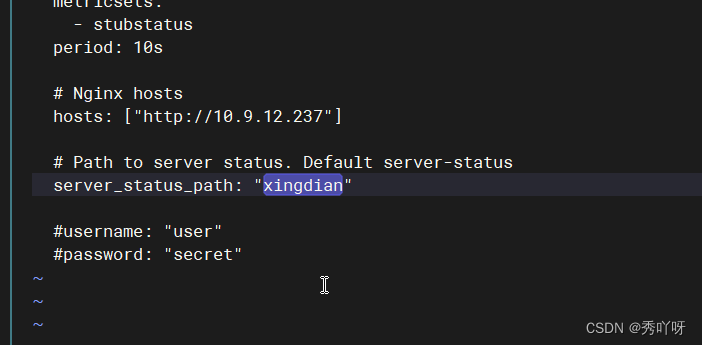
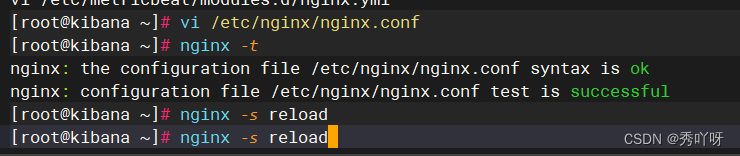
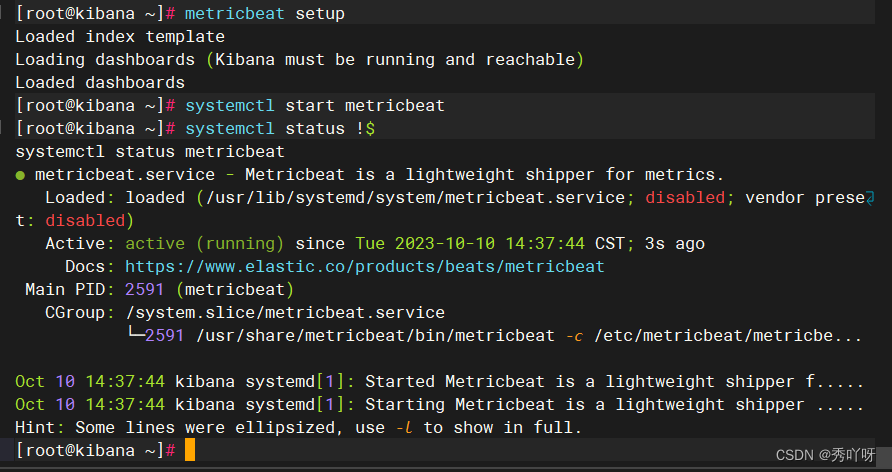
排错

tailf !$
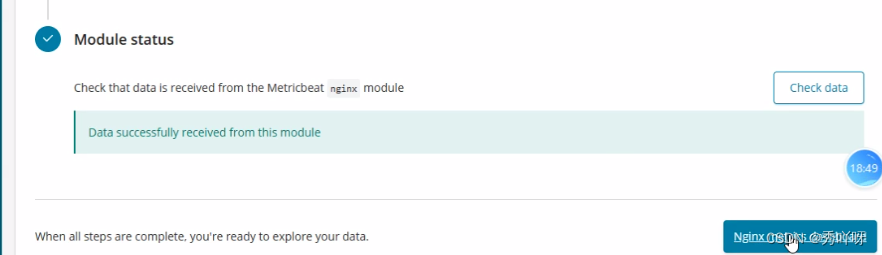
Kibana-Vlsualize查看
kafka(卡夫卡)
kafka是一个分布式的消息发布—订阅系统(kafka其实是消息队列)消息队列中间件
Kafka的特性:(为什么选择kafka的原因)
- 高吞吐量、低延迟:kafka每秒可以处理几十万条消息,它的延迟最低只有几毫秒,每个topic可以分多个partition, consumer group 对partition进行consumer操作。
- 可扩展性:kafka集群支持热扩展
- 可靠性:消息被持久化到本地磁盘,并且支持数据备份防止数据丢失
- 容错性:允许集群中节点失败(若副本数量为n,则允许n-1个节点失败)
- 高并发:支持数千个客户端同时读写
kafka1.2.3
vi /etc/hosts
ip kafka-1、2、3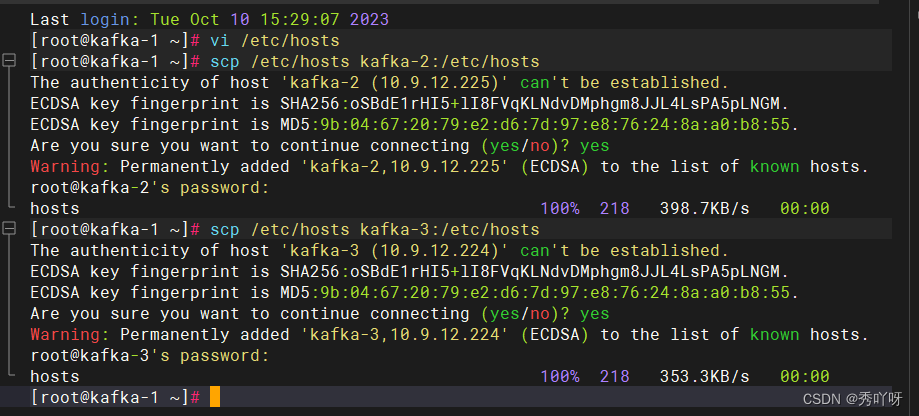
上传jdk
tar xf jdk -C /usr/local
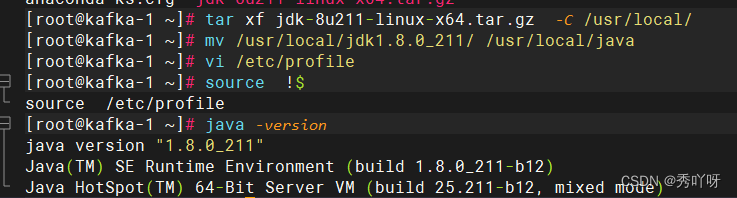
vi /etc/profile
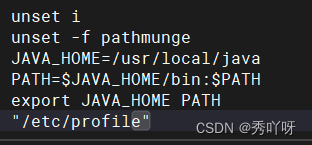
source !$
java -version
上传kafka
scp kafka... kafka-2:/root/
scp kafka... kafka-3:/root/
tar xf kafka.... -C /usr/local
mv /usr/local/kafka /usr/local/kafka
sed -i 's/^[^#]/#&/' /usr/local/kafka_2.11-2.1.0/config/zookeeper.properties
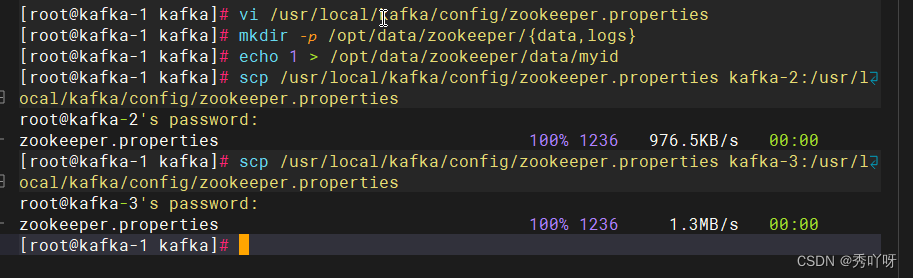
vi /usr/local/kafka/config/zookeeper.properties(加进去)
dataDir=/opt/data/zookeeper/data
dataLogDir=/opt/data/zookeeper/logs
clientPort=2181
tickTime=2000
initLimit=20
syncLimit=10
server.1=kafka-1:2888:3888
server.2=kafka-2:2888:3888
server.3=kafka-3:2888:3888
mkdir -p /opt/data/zookeeper/{data,logs} (1.2.3)
echo 2 > /opt/data/zookeeper/data/myid (服务器kafka-2)
echo 3 > /opt/data/zookeeper/data/myid (服务器kafka-3)
sed -i 's/^[^#]/#&/' /usr/local/kafka/config/server.properties (1.2.3)
vi /usr/local/kafka/config/server.properties
broker.id=1
listeners=PLAINTEXT://kafka-1:9092
num.network.threads=3
num.io.threads=8
socket.send.buffer.bytes=102400
socket.receive.buffer.bytes=102400
socket.request.max.bytes=104857600
log.dirs=/opt/data/kafka/logs
num.partitions=6
num.recovery.threads.per.data.dir=1
offsets.topic.replication.factor=2
transaction.state.log.replication.factor=1
transaction.state.log.min.isr=1
log.retention.hours=168
log.segment.bytes=536870912
log.retention.check.interval.ms=300000
zookeeper.connect=kafka-1:2181,kafka-2:2181,kafka-3:2181
zookeeper.connection.timeout.ms=6000
group.initial.rebalance.delay.ms=0
创建log目录 mkdir -p /opt/data/kafka/logs (1.2.3)
去kafka-2,kafka-3修改
broker.id
listeners

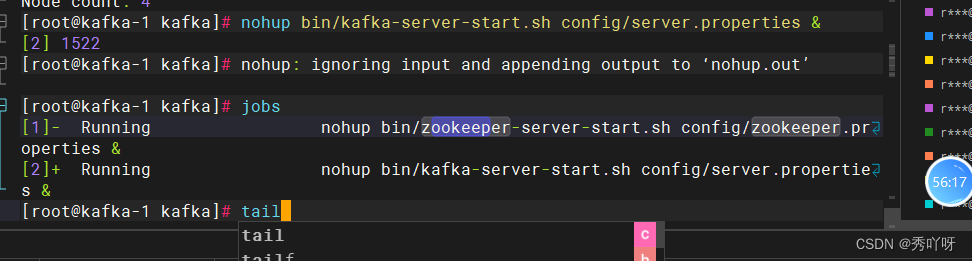
启动(1.2.3)

验证
yum provides nc
yum -y install nmap-ncat
echo conf | nc 127.0.0.1 2181
ss -antpl 2181 9092
这篇关于Filebeat、metricbeat、kafka的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




