本文主要是介绍python学法用法 自动刷分_Python selenium模拟手动操作实现无人值守刷积分功能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
经常为学校的各种刷分而发愁,得知开学无望,日后还要刷课,索性自动化一次,学而不用乃愚昧 聪慧
四大模块
初始化
from selenium import webdriver
if __name__ == '__main__':
driver = webdriver.Chrome()
url = 'https://pc.xuexi.cn/points/login.html?ref=https://pc.xuexi.cn/points/my-points.html'
driver.get(url = url)
文章有效阅读积分 + 文章时长积分
def article():
driver.get(url='https://www.xuexi.cn/d05cad69216e688d304bb91ef3aac4c6/9a3668c13f6e303932b5e0e100fc248b.html')
# 该网址只是众文章阅读中的其中一个类别,还有很多类别的文章供阅读,只需更换链接即可
article_lis = WebDriverWait(driver,100).until(EC.presence_of_all_elements_located((By.XPATH,'//span[@style=white-space: nowrap;]')))
# 显示等待 WebDriverWait(driver,100).until() 在这里等待,直到满足条件或等待时间超过100,即 用xpath找到符合属性style = "white-space: nowrap;" 的span节点;
print('共找到%s篇文章' % len(article_lis))
article_num = 0
# article_num 每天有效阅读上限为6篇文章,但为确保有效时长达到12分钟,所以多出2篇
for data in article_lis: # 遍历找到的文章列表进行模拟阅读
if article_num >= 8: # 当读够8篇时跳出循环,结束文章刷分
break
try:
loading_page(data)
print('已加载', data.text)
# 输出已刷文章,从而得出进度
article_num += 1
except:
continue
def loading_page(element = None):
element.click()
ele = driver.find_element_by_xpath('//a[contains(class,"search-icon")]')
ele.send_keys(Keys.PAGE_DOWN)
# 模拟页面滚动。采用的方法是找到 ‘搜索' 功能按钮,不点击,直接模拟点击按键 PAGE_DOWN
time.sleep(120)
# 每个页面停留两分钟,至少30秒。经测试,每隔30s 将会提交一个post请求,只有请求过后,有效阅读数才会 +1
return None
视频有效观看积分 + 视频时长积分
driver.get(url = 'https://www.xuexi.cn/4426aa87b0b64ac671c96379a3a8bd26/db086044562a57b441c24f2af1c8e101.html#11c4o0tv7nb-5')
# 同上,该网址只是众视频观看中的其中一个类别,还有很多类别的视频供观看,只需更换链接即可
video_lis = WebDriverWait(driver,100).until(EC.presence_of_all_elements_located((By.XPATH,'//div[@style="margin: 0px auto;"]/div/div')))
# 同上,显示等待
print('共找到%s篇文章' % len(video_lis))
video_long = 0
# 记录已经播放的时间
video_lis_1 = []
for data in video_lis:
video_lis_1.append(data.get_attribute('data-link-target'))
# 与文章不同的地方是,文章阅读是模拟点击,而视频播放获取网址,放到video_lis_1 中
for url_1 in video_lis_1: # 遍历视频列表,播放视频
if video_long >= 1080: #视频时长为18分钟,即1080秒,在播放时间超过18分后结束播放,其实也根据分钟判断,我也不知道为什么当时就用上了秒
break
try:
video.get(url = url_1)
tim_now = loading_video(driver = driver)
video_long += tim_now*60
# loading_video 返回的是已阅读分钟数,故*60
print('视频播放中,已播放时长%s秒'%video_num)
except:
continue
def loading_video(driver = None):
elem_first = WebDriverWait(driver, 100).until(EC.presence_of_all_elements_located((By.XPATH, '//span[@class="duration"]')))
elem_start = driver.find_element_by_xpath('//div[@class="outter"]')
elem_start.click()
# 打开网页后不自动播放,应该是因为是直接打开网址的原因
# 因为在此之前我也直接通过模拟点击打开网页,结果是自动播放的,但有一点儿不符合我当时的需求,故改为打开网页的方式
tim_num = (int(elem_first[0].text[0])*10 + int(elem_first[0].text[1]))
# 目的是获取视频的总时间,只取分钟数
if tim_num != 0: # 因为有些视频它根本不到一分钟,故加判断条件
time.sleep(tim_num * 60)
return tim_num
else:
time.sleep(60)
# 不足一分钟,不播放也要凑够一分钟
return 1
每日答题积分
def DaTi():
driver.get(url = 'https://pc.xuexi.cn/points/exam-practice.html')
elem_juje = WebDriverWait(driver,100).until(EC.presence_of_element_located((By.XPATH,'//div[@class="q-header"]')))
juje = elem_juje.get_attribute('innerText')
# 在每日答题中,有三类题,判断题、选择题、填空题,所以先获取题的类别
# 注意 特别需要注意的是 By.XPATH 和 xpath 文本获取稍有却别,By.XPATH 获取文本方式为.get_attribute('innerText')
time.sleep(1) # 等待一秒,其实也无所谓,但是为防止过快操作造成电脑卡顿,还是等待一秒。
if '选' in juje:
elem_tishi = WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH, '//span[@class="tips"]')))
elem_tishi.click()
# 在答题中,答案在查看提示中以红色标记,所以首先要模拟点击查看答案,使答案加载
time.sleep(0.5)
elem_answer = WebDriverWait(driver, 100).until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="line-feed"]/font')))
# 提取红色标记的文字,即答案
time.sleep(0.5)
# 同样没什么实际意义
ans_lis = []
for elem in elem_answer:
ans_lis.append(elem.get_attribute('innerText'))
# 因为选择题嘛,不一定就是单选题,所以要存放这些答案,以便于在选项中找答案
print('得到答案')
time.sleep(0.5)
# 同样没什么实际意义
elem_juje.click()
# 再次模拟点击的原因是 此时 查看提示 框还处于打开状态,如果不关闭,会影响提交答案的操作
# 模拟点击网页,关闭 查看提示 框
time.sleep(0.5)
elem_xuanxiang = WebDriverWait(driver, 100).until(EC.presence_of_all_elements_located((By.XPATH, '//div[@class="question"]/div[@class="q-answers"]/div[contains(@class,"q-answer")]')))
# 获取所有的选项节点
for elem in elem_xuanxiang:
data = elem.get_attribute('innerText')[3:].replace('-','')
print(data)
for i in ans_lis:
if i in data:
elem.click()
ans_lis.remove(i)
# 根据依次A -- > D 遍历答案,将两者对照进行选择与否,所以满足要求后去除该答案
# 防止对选项多次点击造成取消选择或其他错误
time.sleep(0.5) #防止过快操作,每次选择后等待0.5秒
break
elem_next = WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH,'//div[@class="action-row"]/button')))
elem_next.click()
# 模拟点击确定按钮跳转下一题
DaTi(driver)
elif '填' in juje:
elem_tishi = WebDriverWait(driver,100).until(EC.presence_of_element_located((By.XPATH,'//span[@class="tips"]')))
elem_tishi.click()
time.sleep(0.5)
elem_answer = WebDriverWait(driver,100).until(EC.presence_of_element_located((By.XPATH,'//div[@class="line-feed"]')))
time.sleep(0.5)
if '请观看视频' in elem_answer.get_attribute('innerText'):
input('手动选择答案后无需点击确定,在此输入回车继续')
elem_next = WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH, '//div[@class="action-row"]/button')))
elem_next.click()
# 在填空题中会有观看视频的题目,而且查看提示中会写‘请观看视频'而不会直接给出答案,所以要人工选择
elem_answer = WebDriverWait(driver,100).until(EC.presence_of_all_elements_located((By.XPATH,'//div[@class="line-feed"]/font')))
answer = []
time.sleep(0.5)
for elem in elem_answer:
answer.append(elem.get_attribute('innerText'))
# 同样填空题中也有多个空的情况,所以将答案放在列表里
time.sleep(1)
elem_data = WebDriverWait(driver,100).until(EC.presence_of_all_elements_located((By.XPATH,'//input[@class="blank"]')))
# 找到每个空
for i in range(len(answer)):
elem_data[i].send_keys(answer[i])
time.sleep(0.5)
# 通过遍历空,将对应的答案写入
elem_data[0].click()
time.sleep(1)
# 模拟点击网页,因为在写完空后,不点击网页会有确定按钮为不可点的情况
elem_next = WebDriverWait(driver,100).until(EC.presence_of_element_located((By.XPATH,'//div[@class="action-row"]/button')))
elem_next.click()
DaTi(driver)
elif '判' in juje:# 同上,判断题不会直接给出答案,所以只能手动吧
input('手动选择答案后无需点击确定,在此输入回车继续')
elem_next = WebDriverWait(driver, 100).until(EC.presence_of_element_located((By.XPATH, '//div[@class="action-row"]/button')))
elem_next.click()
DaTi(driver)
结合PyQt5,最终效果图
声明:图片没有别的意思,个人感觉很欢喜,图片转自------百度图片
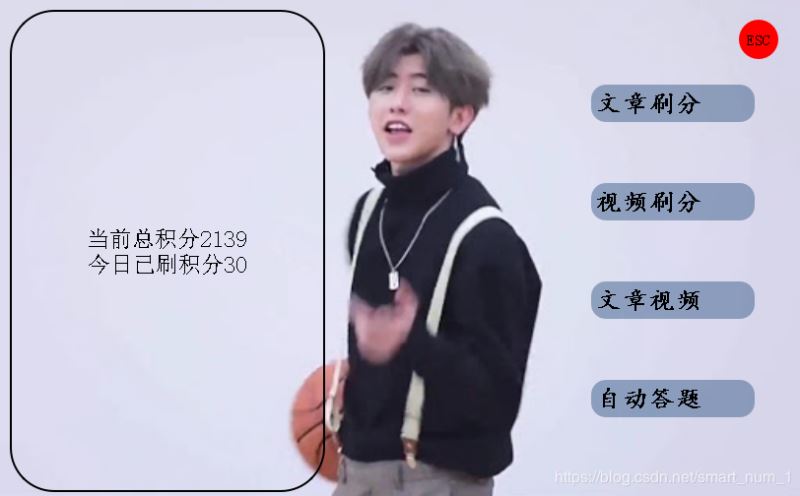
总结
到此这篇关于Python selenium模拟手动操作实现无人值守刷积分功能的文章就介绍到这了,更多相关Python selenium刷积分内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!
这篇关于python学法用法 自动刷分_Python selenium模拟手动操作实现无人值守刷积分功能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





