本文主要是介绍ELK在大数据运维中的应用,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
转载自http://blog.csdn.net/lively1982/article/details/50678657
圈子里关于大数据、云计算相关文章和讨论是越来越多,愈演愈烈。行业内企业也争前恐后,群雄逐鹿。而在大数据时代的运维挑站问题也就日渐突出,任重而道远了。本文旨在针对复杂的大数据运维系统推荐一把利器,达到抛砖引玉的效果,如果文中出现任何纰漏和错误的地方,恳请指正,欢迎讨论,希望大家不吝赐教。
众所周知,大数据平台组件是很复杂的。笔者之前接触的一个大数据平台解决方案,仅平台组件就达20多个,这还没有加上物联网系统各组件。而这庞大的系统整合问题,对于运维来说是很头疼的。所以,在大数据时代下的运维问题是日渐尖锐。
有人把运维比作医生给病人看病,那么日志则是病人对自己的陈述。所以只有在海量分布式日志系统中有效的提取关键信息,才能对症下药。如果能把这些日志集中管理,并提供全文检索功能,不仅可以提高诊断的效率,同时可以起到实时系统监测、网络安全、事件管理和发现bug等功能。基于此,本文向大家推荐一款开源利器——ELK组件(Apache 2.0 License),提供分布式的实时日志(数据)搜集和分析的监控系统。
ELK多种架构及优劣
既然要谈ELK在大数据运维系统中的应用,那么ELK架构就不得不谈。本章节引出四种笔者曾经用过的ELK架构,并讨论各种架构所适合的场景和优劣供大家参考。
先大致介绍ELK组件。ELK是Elasticsearch、Logstash、Kibana的简称,这三者是核心套件,但并非全部。后文的四种基本架构中将逐一介绍应用到的其它套件。
-
Elasticsearch是实时全文搜索和分析引擎,提供搜集、分析、存储数据三大功能;是一套开放REST和JAVA API等结构提供高效搜索功能,可扩展的分布式系统。它构建于Apache Lucene搜索引擎库之上。
-
Logstash是一个用来搜集、分析、过滤日志的工具。它支持几乎任何类型的日志,包括系统日志、错误日志和自定义应用程序日志。它可以从许多来源接收日志,这些来源包括 syslog、消息传递(例如 RabbitMQ)和JMX,它能够以多种方式输出数据,包括电子邮件、websockets和Elasticsearch。
-
Kibana是一个基于Web的图形界面,用于搜索、分析和可视化存储在 Elasticsearch指标中的日志数据。它利用Elasticsearch的REST接口来检索数据,不仅允许用户创建他们自己的数据的定制仪表板视图,还允许他们以特殊的方式查询和过滤数据。
我们先谈谈第一种ELK架构,如图1,这是最简单的一种ELK架构方式。优点是搭建简单,易于上手。缺点是Logstash耗资源较大,运行占用CPU和内存高。另外没有消息队列缓存,存在数据丢失隐患。建议供学习者和小规模集群使用。
此架构首先由Logstash分布于各个节点上搜集相关日志、数据,并经过分析、过滤后发送给远端服务器上的Elasticsearch进行存储。Elasticsearch将数据以分片的形式压缩存储并提供多种API供用户查询,操作。用户亦可以更直观的通过配置Kibana Web Portal方便的对日志查询,并根据数据生成报表(详细过程和配置在此省略)。
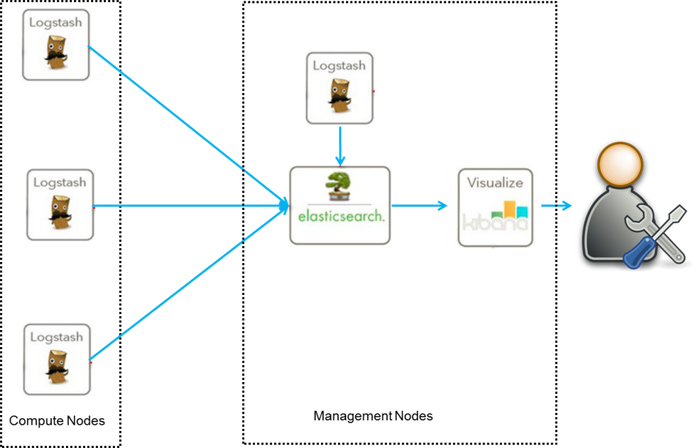
图1 ELK架构一
第二种架构(图2)引入了消息队列机制,位于各个节点上的Logstash Agent先将数据/日志传递给Kafka(或者Redis),并将队列中消息或数据间接传递给Logstash,Logstash过滤、分析后将数据传递给Elasticsearch存储。最后由Kibana将日志和数据呈现给用户。因为引入了Kafka(或者Redis),所以即使远端Logstash server因故障停止运行,数据将会先被存储下来,从而避免数据丢失。
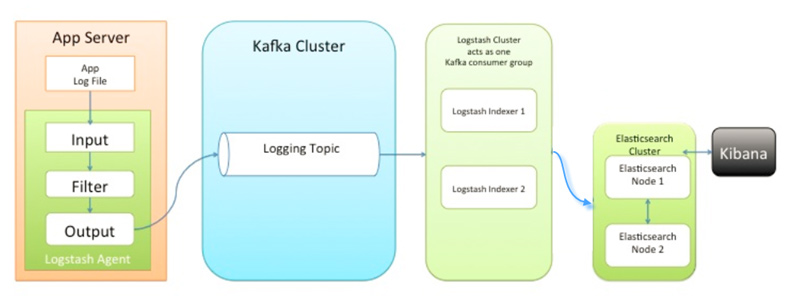
图2 ELK架构二
这种架构适合于较大集群的解决方案,但由于Logstash中心节点和Elasticsearch的负荷会比较重,可将他们配置为集群模式,以分担负荷,这种架构的优点在于引入了消息队列机制,均衡了网络传输,从而降低了网络闭塞尤其是丢失数据的可能性,但依然存在Logstash占用系统资源过多的问题。
第三种架构(图3)引入了Logstash-forwarder。首先,Logstash-forwarder将日志数据搜集并统一发送给主节点上的Logstash,Logstash分析、过滤日志数据后发送至Elasticsearch存储,并由Kibana最终将数据呈现给用户。
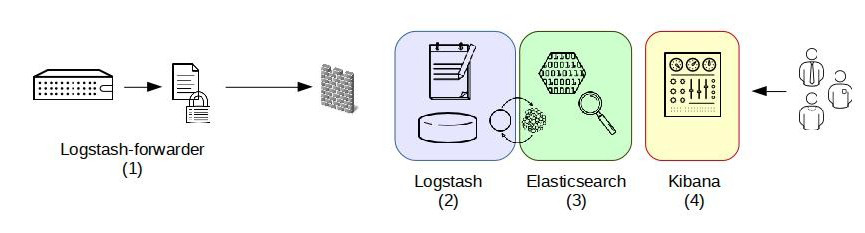
图3 ELK架构三
这种架构解决了Logstash在各计算机点上占用系统资源较高的问题。经测试得出,相比Logstash,Logstash-forwarder所占用系统CPU和MEM几乎可以忽略不计。另外,Logstash-forwarder和Logstash间的通信是通过SSL加密传输,起到了安全保障。如果是较大集群,用户亦可以如结构三那样配置logstash集群和Elasticsearch集群,引入High Available机制,提高数据传输和存储安全。更主要的配置多个Elasticsearch服务,有助于搜索和数据存储效率。但在此种架构下发现Logstash-forwarder和Logstash间通信必须由SSL加密传输,这样便有了一定的限制性。
第四种架构(图4),将Logstash-forwarder替换为Beats。经测试,Beats满负荷状态所耗系统资源和Logstash-forwarder相当,但其扩展性和灵活性有很大提高。Beats platform目前包含有Packagebeat、Topbeat和Filebeat三个产品,均为Apache 2.0 License。同时用户可根据需要进行二次开发。
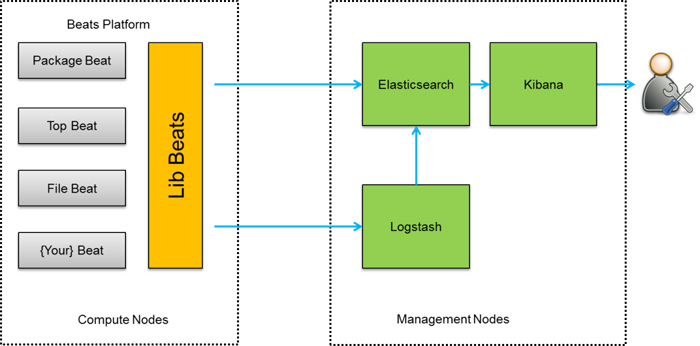
图4 ELK架构四
这种架构原理基于第三种架构,但是更灵活,扩展性更强。同时可配置Logstash 和Elasticsearch 集群用于支持大集群系统的运维日志数据监控和查询。
不管采用上面哪种ELK架构,都包含了其核心组件,即:Logstash、Elasticsearch 和Kibana。当然这三个组件并非不能被替换,只是就性能和功能性而言,这三个组件已经配合的很完美,是密不可分的。各系统运维中究竟该采用哪种架构,可根据现实情况和架构优劣而定。
ELK在大数据运维系统中的应用
在海量日志系统的运维中,以下几个方面是必不可少的:
-
分布式日志数据集中式查询和管理
-
系统监控,包含系统硬件和应用各个组件的监控
-
故障排查
-
安全信息和事件管理
-
报表功能
ELK组件各个功能模块如图5所示,它运行于分布式系统之上,通过搜集、过滤、传输、储存,对海量系统和组件日志进行集中管理和准实时搜索、分析,使用搜索、监控、事件消息和报表等简单易用的功能,帮助运维人员进行线上业务的准实时监控、业务异常时及时定位原因、排除故障、程序研发时跟踪分析Bug、业务趋势分析、安全与合规审计,深度挖掘日志的大数据价值。同时Elasticsearch提供多种API(REST JAVA PYTHON等API)供用户扩展开发,以满足其不同需求。
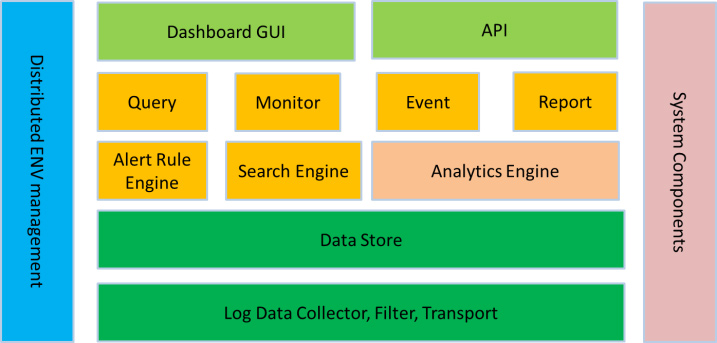
图5 ELK在运维系统组件中应用图示
汇总ELK组件在大数据运维系统中,主要可解决的问题如下:
-
日志查询,问题排查,上线检查
-
服务器监控,应用监控,错误报警,Bug管理
-
性能分析,用户行为分析,安全漏洞分析,时间管理
综上,ELK组件在大数据运维中的应用是一套必不可少的且方便、易用的开源解决方案。
ELK实战举例
ELK实战举例一,通过ELK组件对Spark作业运行状态监控,搜集Spark环境下运行的日志。经过筛选、过滤并存储可用信息,从而完成对Spark作业运行和完成状态进行监控,实时掌握集群状态,了解作业完成情况,并生成报表,方便运维人员监控和查看。
数据来源可以是各式各样的日志,Logstash配置文件有三个主要模块:input()输入或者说收集数据,定义数据来源;filter()对数据进行过滤,分析等操作;output()输出。input plugin目前支持将近50种,如下表所示:
| Beats | couchdb_changes | Xmpp | eventlog | exec | s3 | file | ganglia | gelf |
|---|---|---|---|---|---|---|---|---|
| Github | Heartbeat | Heroku | http | Sqs | Irc | imap | jdbc | JMX |
| lumberjack | varnishlog | Pipe | snmptrap | generator | Rss | rackspace | RabbitMQ | Redis |
| Sqlite | Elasticsearch | http_poller | Stomp | syslog | TCP | unix | UDP | |
| websocket | drupal_dblog | Zenoss | ZeroMQ | Graphite | Log4j | stdin | wmi | relp |
| Kafka | puppet_facter | Meetup |
数据源搜集到后,然后通过filter过滤形成固定的数据格式。目前支持过滤的类JSON、grep、grok、geoip等,最后output到数据库,比如Redis、Kafka或者直接传送给Elasticsearch。当数据被存储于Elasticsearch之后,用户可以使用Elasticsearch所提供API来检索信息数据了,如通过REST API执行CURL GET请求搜索指定数据。用户也可以使用Kibana进行可视化的数据浏览。另外Kibana有时间过滤功能,运维人员可对某一时间段内数据查询并查看报表,方便快捷。
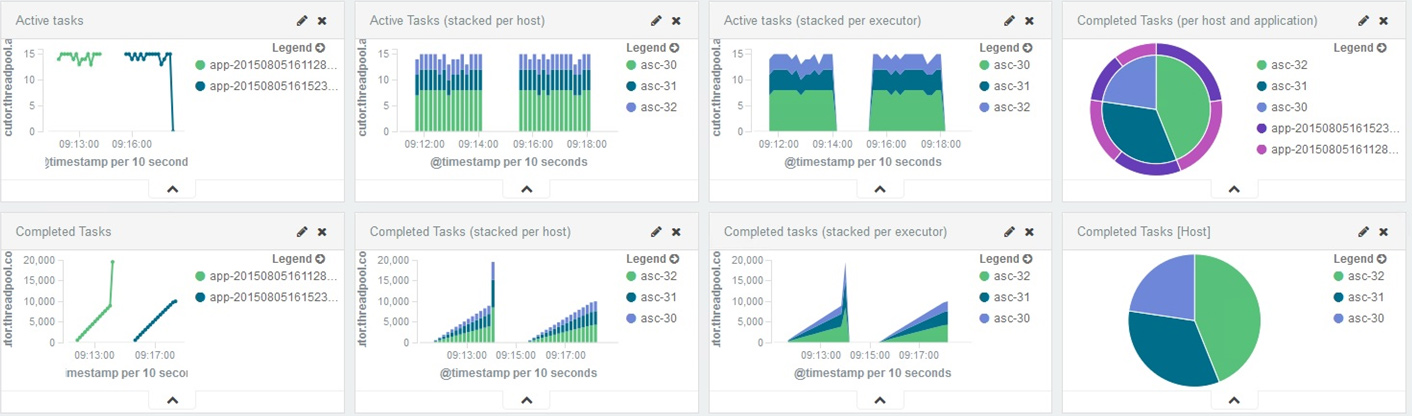
图6 ELK对Spark Task 监控
ELK实战举例二,通过ELK组件对系统资源状态监控,如图7、图8所示,是笔者前段时间使用ELK组件为集群提供日志查询和系统资源监控的例子。通过各类日志搜集,分析,过滤,存储并通过Kibana展现给用户,供用户实时监控系统资源、节点状态、磁盘、CPU、MEM,以及错误、警告信息等。

图7 ELK对系统状态监控
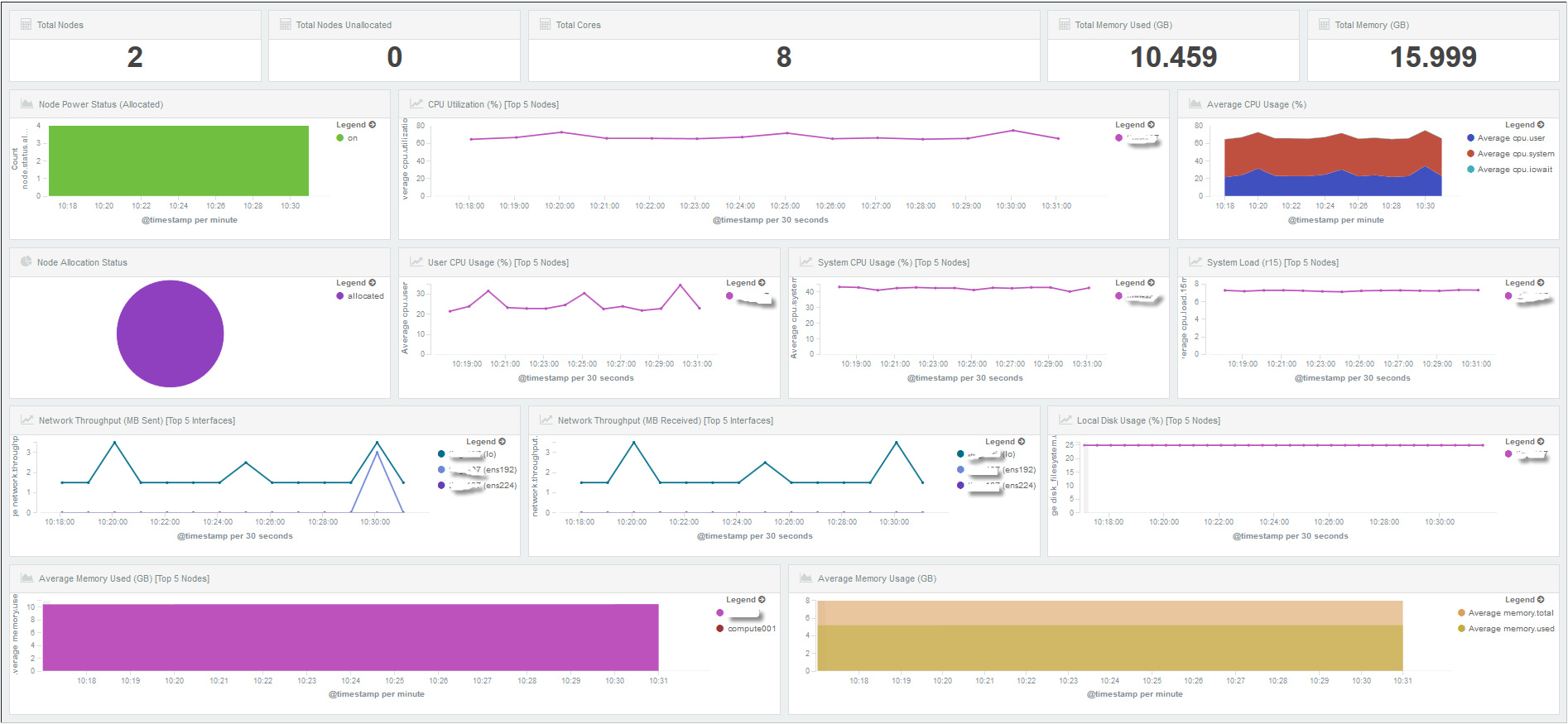
图8 ELK对系统资源情况监控
ELK实战举例三,通过ELK组件对系统负载状态监控,如图9所示。
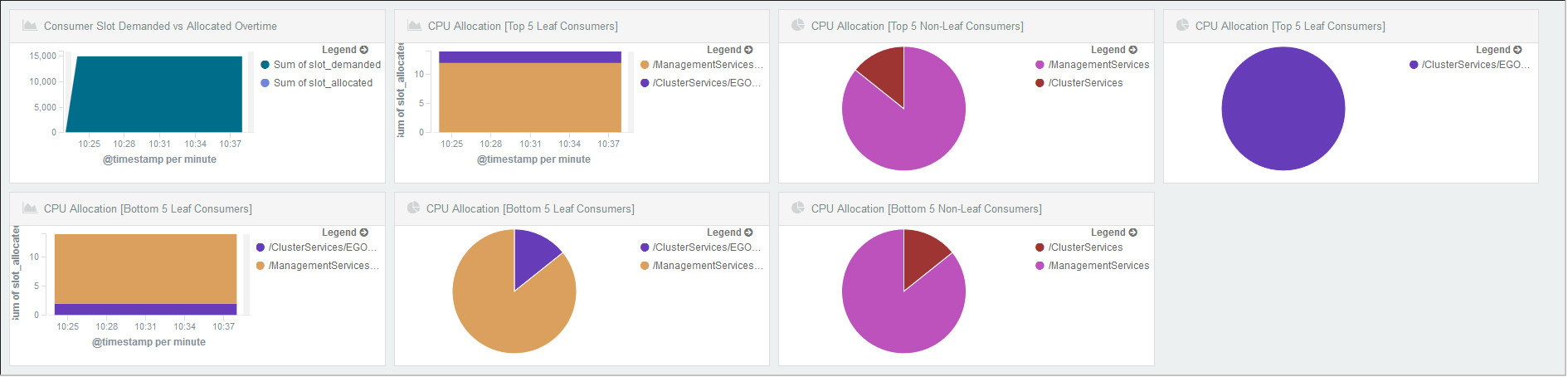
图9 ELK对workload监控
ELK实战举例四,通过ELK组件对系统日志管理和故障排查,如图10所示。用户可根据故障发生时间段集中查询相关日志,可通过搜索、筛选、过滤等功能,快速定位问题,从而排查故障。另外,通过对各个应用组件的日志过滤,可快速列举出各个应用对应节点上的Error或Warning日志,从而对故障排查或者对发现产品bug提供快捷途径。
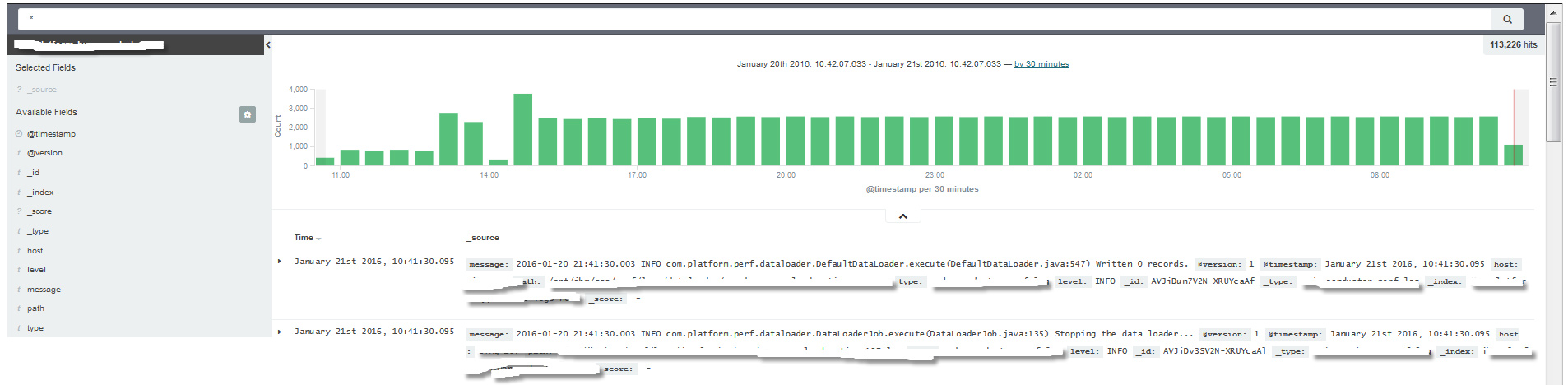
图10 ELK 对日志搜索,查询
结束语
除ELK套件以外,业界关于运维监控产品还有很多,如Splunk、Nagios等。
Splunk是在语句里生成图表。而ELK则是用户在Kibana Web Portal上鼠标选择的方式来点出来,相比Splunk来说要简单得多,用户不用记住那些语法即可绘制多种Chart。易用性有很大提高。另外,Splunk属于入库后对内容的即使处理,比如rex函数等等,而ES是尽量在入库前,即在Logstash端已经将数据源实时过滤、分析。提高了数据处理能力。最重要一点,ELK是免费的,Splunk则需要昂贵的费用。
Nagios最大的特点是其强大的管理中心,但看不到历史数据,很难追查故障原因,而且配置复杂,这些恰恰是ELK组件的优势所在。
本文所述案例和架构来自于IBM Platform团队在使用ELK套件中的实战经历和工作总结,IBM Platform冲出了ELK套件仅对日志搜集的约束,除Logstash所支持input plugin外,还充分利用了Elasticsearch本身所支持多种数据源输入,从而增强了数据源的输入条件,提高了系统监控范围,大大提高了ELK的扩展性和实用性。
ELK本身对POWER系统,还有IBM JAVA支持有一定局限性,不过IBM Platform团队已经将这些问题一一解决,使之可以完美地集成于多个平台。除此之外,IBM Platform将ELK和IBM Platform Cluster Manager、IBM Platform EGO集成于一体。用于ELK自动部署和管理,有效提高了ELK的部署和管理效率。并对IBM Platform Converge、IBM Platform Conductor(包括Spark)提供监控和Dashboard等功能。
作者简介
李峰,供职于IBM Platform 多年,从事分布式计算、高性能计算、大数据相关工作,倾向于日志分析、数据监控等研究。
王占伟,资深研发工程师,供职于IBM多年,专注于大数据、云计算、高性能计算等平台的日志分析、数据监控等方面的研发工作。
何金池,毕业于西安邮电大学,目前供职于IBM,工作方向为大数据日志处理、高性能计算等领域。
李婷,研发工程师,供职于IBM Platform,从事分布式计算、高性能计算、大数据相关工作,对前端开发有较深研究。
这篇关于ELK在大数据运维中的应用的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





